 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFDAN: Flow-guided Deformable Alignment Network for Video Super-Resolution
Paper and Code
May 12, 2021


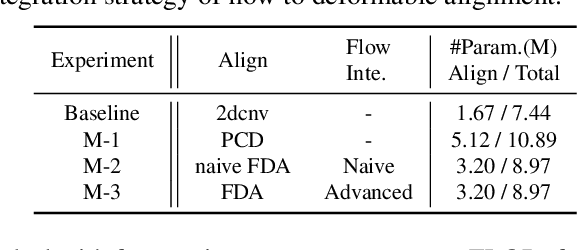
Most Video Super-Resolution (VSR) methods enhance a video reference frame by aligning its neighboring frames and mining information on these frames. Recently, deformable alignment has drawn extensive attention in VSR community for its remarkable performance, which can adaptively align neighboring frames with the reference one. However, we experimentally find that deformable alignment methods still suffer from fast motion due to locally loss-driven offset prediction and lack explicit motion constraints. Hence, we propose a Matching-based Flow Estimation (MFE) module to conduct global semantic feature matching and estimate optical flow as coarse offset for each location. And a Flow-guided Deformable Module (FDM) is proposed to integrate optical flow into deformable convolution. The FDM uses the optical flow to warp the neighboring frames at first. And then, the warped neighboring frames and the reference one are used to predict a set of fine offsets for each coarse offset. In general, we propose an end-to-end deep network called Flow-guided Deformable Alignment Network (FDAN), which reaches the state-of-the-art performance on two benchmark datasets while is still competitive in computation and memory consumption.