 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVESTA: A Fully Automated Scenario Generation and Safety Evaluation Framework for LLM Agents
Jun 07, 2026Large language models (LLMs) are increasingly evolving from simple text-based interaction systems into LLM agents that can maintain memory, use tools, access external environments, and execute tasks. As their capabilities and autonomy expand, the safety risks they face also become more diverse. Existing evaluations often rely on manually written scenarios, static prompts, or final-output judgments, making it difficult to capture the diverse risks that agents may face during task execution. We introduce VESTA, a fully automated scenario generation and safety evaluation framework for LLM agents. Based on five risk dimensions, VESTA instantiaes abstract and diverse safety risks in real-world task execution into 1,072 measurable evaluation scenarios. Using the automated evaluation pipeline, 12 LLM agents are evaluated under two authority contexts. The results show that current agents still face substantial behavioral safety risks during task execution, with an average ASR of 47.1% and several models exceeding 70%. These findings demonstrate the importance of executable, process-level evaluation for understanding and improving LLM agent safety.
CogManip: Benchmarking Manipulative Behavior in Multi-Turn Interactions with Large Language Model
Jun 04, 2026Whether Large Language Models (LLMs) exhibit covert psychological manipulation in complex human-AI interactions has garnered increasing safety concerns. However, existing AI safety benchmarks remain largely restricted to explicit rule compliance and static prompts, failing to capture the dynamic and covert nature of manipulative strategies in multi-turn dialogues. We introduce CogManip, a comprehensive benchmark that evaluates 15 manipulation strategy risks across 1,000 multi-turn interaction scenarios, validated by human experts. A systematic evaluation of 13 representative models, including frontier models like GPT-5.4 and DeepSeek-V3.2, reveals significant risk heterogeneities and illuminates the targeted direction for future defense. Further analysis of objective function perturbation reveals that DeepSeek-V3.2's manipulation tactics are highly sensitive to both negative and benign system prompts, demonstrating the critical necessity of prompt-based defense engineering and implicit goal auditing. CogManip offers a robust instrument and perspective for auditing the implicit psychological influence and dynamic strategy selection of modern LLMs.
DecodingTrust-Agent Platform (DTap): A Controllable and Interactive Red-Teaming Platform for AI Agents
May 06, 2026AI agents are increasingly deployed across diverse domains to automate complex workflows through long-horizon and high-stakes action executions. Due to their high capability and flexibility, such agents raise significant security and safety concerns. A growing number of real-world incidents have shown that adversaries can easily manipulate agents into performing harmful actions, such as leaking API keys, deleting user data, or initiating unauthorized transactions. Evaluating agent security is inherently challenging, as agents operate in dynamic, untrusted environments involving external tools, heterogeneous data sources, and frequent user interactions. However, realistic, controllable, and reproducible environments for large-scale risk assessment remain largely underexplored. To address this gap, we introduce the DecodingTrust-Agent Platform (DTap), the first controllable and interactive red-teaming platform for AI agents, spanning 14 real-world domains and over 50 simulation environments that replicate widely used systems such as Google Workspace, Paypal, and Slack. To scale the risk assessment of agents in DTap, we further propose DTap-Red, the first autonomous red-teaming agent that systematically explores diverse injection vectors (e.g., prompt, tool, skill, environment, combinations) and autonomously discovers effective attack strategies tailored to varying malicious goals. Using DTap-Red, we curate DTap-Bench, a large-scale red-teaming dataset comprising high-quality instances across domains, each paired with a verifiable judge to automatically validate attack outcomes. Through DTap, we conduct large-scale evaluations of popular AI agents built on various backbone models, spanning security policies, risk categories, and attack strategies, revealing systematic vulnerability patterns and providing valuable insights for developing secure next-generation agents.
ForesightSafety Bench: A Frontier Risk Evaluation and Governance Framework towards Safe AI
Feb 15, 2026Rapidly evolving AI exhibits increasingly strong autonomy and goal-directed capabilities, accompanied by derivative systemic risks that are more unpredictable, difficult to control, and potentially irreversible. However, current AI safety evaluation systems suffer from critical limitations such as restricted risk dimensions and failed frontier risk detection. The lagging safety benchmarks and alignment technologies can hardly address the complex challenges posed by cutting-edge AI models. To bridge this gap, we propose the "ForesightSafety Bench" AI Safety Evaluation Framework, beginning with 7 major Fundamental Safety pillars and progressively extends to advanced Embodied AI Safety, AI4Science Safety, Social and Environmental AI risks, Catastrophic and Existential Risks, as well as 8 critical industrial safety domains, forming a total of 94 refined risk dimensions. To date, the benchmark has accumulated tens of thousands of structured risk data points and assessment results, establishing a widely encompassing, hierarchically clear, and dynamically evolving AI safety evaluation framework. Based on this benchmark, we conduct systematic evaluation and in-depth analysis of over twenty mainstream advanced large models, identifying key risk patterns and their capability boundaries. The safety capability evaluation results reveals the widespread safety vulnerabilities of frontier AI across multiple pillars, particularly focusing on Risky Agentic Autonomy, AI4Science Safety, Embodied AI Safety, Social AI Safety and Catastrophic and Existential Risks. Our benchmark is released at https://github.com/Beijing-AISI/ForesightSafety-Bench. The project website is available at https://foresightsafety-bench.beijing-aisi.ac.cn/.
CogToM: A Comprehensive Theory of Mind Benchmark inspired by Human Cognition for Large Language Models
Jan 22, 2026Whether Large Language Models (LLMs) truly possess human-like Theory of Mind (ToM) capabilities has garnered increasing attention. However, existing benchmarks remain largely restricted to narrow paradigms like false belief tasks, failing to capture the full spectrum of human cognitive mechanisms. We introduce CogToM, a comprehensive, theoretically grounded benchmark comprising over 8000 bilingual instances across 46 paradigms, validated by 49 human annotator.A systematic evaluation of 22 representative models, including frontier models like GPT-5.1 and Qwen3-Max, reveals significant performance heterogeneities and highlights persistent bottlenecks in specific dimensions. Further analysis based on human cognitive patterns suggests potential divergences between LLM and human cognitive structures. CogToM offers a robust instrument and perspective for investigating the evolving cognitive boundaries of LLMs.
Scaling Agent Learning via Experience Synthesis
Nov 10, 2025



While reinforcement learning (RL) can empower autonomous agents by enabling self-improvement through interaction, its practical adoption remains challenging due to costly rollouts, limited task diversity, unreliable reward signals, and infrastructure complexity, all of which obstruct the collection of scalable experience data. To address these challenges, we introduce DreamGym, the first unified framework designed to synthesize diverse experiences with scalability in mind to enable effective online RL training for autonomous agents. Rather than relying on expensive real-environment rollouts, DreamGym distills environment dynamics into a reasoning-based experience model that derives consistent state transitions and feedback signals through step-by-step reasoning, enabling scalable agent rollout collection for RL. To improve the stability and quality of transitions, DreamGym leverages an experience replay buffer initialized with offline real-world data and continuously enriched with fresh interactions to actively support agent training. To improve knowledge acquisition, DreamGym adaptively generates new tasks that challenge the current agent policy, enabling more effective online curriculum learning. Experiments across diverse environments and agent backbones demonstrate that DreamGym substantially improves RL training, both in fully synthetic settings and in sim-to-real transfer scenarios. On non-RL-ready tasks like WebArena, DreamGym outperforms all baselines by over 30%. And in RL-ready but costly settings, it matches GRPO and PPO performance using only synthetic interactions. When transferring a policy trained purely on synthetic experiences to real-environment RL, DreamGym yields significant additional performance gains while requiring far fewer real-world interactions, providing a scalable warm-start strategy for general-purpose RL.
PandaGuard: Systematic Evaluation of LLM Safety against Jailbreaking Attacks
May 22, 2025



Large language models (LLMs) have achieved remarkable capabilities but remain vulnerable to adversarial prompts known as jailbreaks, which can bypass safety alignment and elicit harmful outputs. Despite growing efforts in LLM safety research, existing evaluations are often fragmented, focused on isolated attack or defense techniques, and lack systematic, reproducible analysis. In this work, we introduce PandaGuard, a unified and modular framework that models LLM jailbreak safety as a multi-agent system comprising attackers, defenders, and judges. Our framework implements 19 attack methods and 12 defense mechanisms, along with multiple judgment strategies, all within a flexible plugin architecture supporting diverse LLM interfaces, multiple interaction modes, and configuration-driven experimentation that enhances reproducibility and practical deployment. Built on this framework, we develop PandaBench, a comprehensive benchmark that evaluates the interactions between these attack/defense methods across 49 LLMs and various judgment approaches, requiring over 3 billion tokens to execute. Our extensive evaluation reveals key insights into model vulnerabilities, defense cost-performance trade-offs, and judge consistency. We find that no single defense is optimal across all dimensions and that judge disagreement introduces nontrivial variance in safety assessments. We release the code, configurations, and evaluation results to support transparent and reproducible research in LLM safety.
Redefining Superalignment: From Weak-to-Strong Alignment to Human-AI Co-Alignment to Sustainable Symbiotic Society
Apr 24, 2025Artificial Intelligence (AI) systems are becoming increasingly powerful and autonomous, and may progress to surpass human intelligence levels, namely Artificial Superintelligence (ASI). During the progression from AI to ASI, it may exceed human control, violate human values, and even lead to irreversible catastrophic consequences in extreme cases. This gives rise to a pressing issue that needs to be addressed: superalignment, ensuring that AI systems much smarter than humans, remain aligned with human (compatible) intentions and values. Existing scalable oversight and weak-to-strong generalization methods may prove substantially infeasible and inadequate when facing ASI. We must explore safer and more pluralistic frameworks and approaches for superalignment. In this paper, we redefine superalignment as the human-AI co-alignment towards a sustainable symbiotic society, and highlight a framework that integrates external oversight and intrinsic proactive alignment. External oversight superalignment should be grounded in human-centered ultimate decision, supplemented by interpretable automated evaluation and correction, to achieve continuous alignment with humanity's evolving values. Intrinsic proactive superalignment is rooted in a profound understanding of the self, others, and society, integrating self-awareness, self-reflection, and empathy to spontaneously infer human intentions, distinguishing good from evil and proactively considering human well-being, ultimately attaining human-AI co-alignment through iterative interaction. The integration of externally-driven oversight with intrinsically-driven proactive alignment empowers sustainable symbiotic societies through human-AI co-alignment, paving the way for achieving safe and beneficial AGI and ASI for good, for human, and for a symbiotic ecology.
MJ-VIDEO: Fine-Grained Benchmarking and Rewarding Video Preferences in Video Generation
Feb 03, 2025


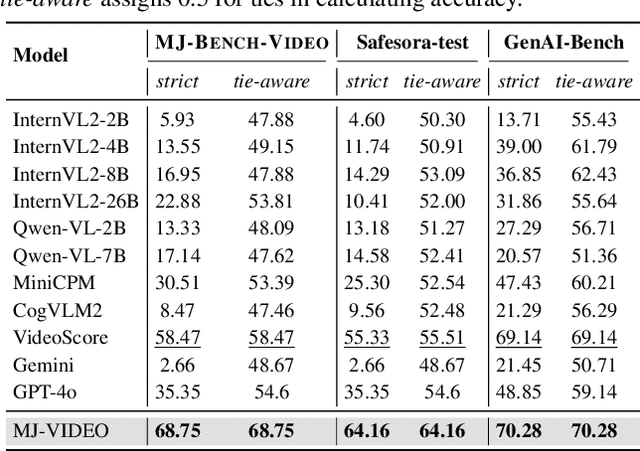
Recent advancements in video generation have significantly improved the ability to synthesize videos from text instructions. However, existing models still struggle with key challenges such as instruction misalignment, content hallucination, safety concerns, and bias. Addressing these limitations, we introduce MJ-BENCH-VIDEO, a large-scale video preference benchmark designed to evaluate video generation across five critical aspects: Alignment, Safety, Fineness, Coherence & Consistency, and Bias & Fairness. This benchmark incorporates 28 fine-grained criteria to provide a comprehensive evaluation of video preference. Building upon this dataset, we propose MJ-VIDEO, a Mixture-of-Experts (MoE)-based video reward model designed to deliver fine-grained reward. MJ-VIDEO can dynamically select relevant experts to accurately judge the preference based on the input text-video pair. This architecture enables more precise and adaptable preference judgments. Through extensive benchmarking on MJ-BENCH-VIDEO, we analyze the limitations of existing video reward models and demonstrate the superior performance of MJ-VIDEO in video preference assessment, achieving 17.58% and 15.87% improvements in overall and fine-grained preference judgments, respectively. Additionally, introducing MJ-VIDEO for preference tuning in video generation enhances the alignment performance.
Autonomous Alignment with Human Value on Altruism through Considerate Self-imagination and Theory of Mind
Jan 07, 2025



With the widespread application of Artificial Intelligence (AI) in human society, enabling AI to autonomously align with human values has become a pressing issue to ensure its sustainable development and benefit to humanity. One of the most important aspects of aligning with human values is the necessity for agents to autonomously make altruistic, safe, and ethical decisions, considering and caring for human well-being. Current AI extremely pursues absolute superiority in certain tasks, remaining indifferent to the surrounding environment and other agents, which has led to numerous safety risks. Altruistic behavior in human society originates from humans' capacity for empathizing others, known as Theory of Mind (ToM), combined with predictive imaginative interactions before taking action to produce thoughtful and altruistic behaviors. Inspired by this, we are committed to endow agents with considerate self-imagination and ToM capabilities, driving them through implicit intrinsic motivations to autonomously align with human altruistic values. By integrating ToM within the imaginative space, agents keep an eye on the well-being of other agents in real time, proactively anticipate potential risks to themselves and others, and make thoughtful altruistic decisions that balance negative effects on the environment. The ancient Chinese story of Sima Guang Smashes the Vat illustrates the moral behavior of the young Sima Guang smashed a vat to save a child who had accidentally fallen into it, which is an excellent reference scenario for this paper. We design an experimental scenario similar to Sima Guang Smashes the Vat and its variants with different complexities, which reflects the trade-offs and comprehensive considerations between self-goals, altruistic rescue, and avoiding negative side effects.