 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisible Light Positioning With Lamé Curve LEDs: A Generic Approach for Camera Pose Estimation
Feb 02, 2026Camera-based visible light positioning (VLP) is a promising technique for accurate and low-cost indoor camera pose estimation (CPE). To reduce the number of required light-emitting diodes (LEDs), advanced methods commonly exploit LED shape features for positioning. Although interesting, they are typically restricted to a single LED geometry, leading to failure in heterogeneous LED-shape scenarios. To address this challenge, this paper investigates Lamé curves as a unified representation of common LED shapes and proposes a generic VLP algorithm using Lamé curve-shaped LEDs, termed LC-VLP. In the considered system, multiple ceiling-mounted Lamé curve-shaped LEDs periodically broadcast their curve parameters via visible light communication, which are captured by a camera-equipped receiver. Based on the received LED images and curve parameters, the receiver can estimate the camera pose using LC-VLP. Specifically, an LED database is constructed offline to store the curve parameters, while online positioning is formulated as a nonlinear least-squares problem and solved iteratively. To provide a reliable initialization, a correspondence-free perspective-\textit{n}-points (FreeP\textit{n}P) algorithm is further developed, enabling approximate CPE without any pre-calibrated reference points. The performance of LC-VLP is verified by both simulations and experiments. Simulations show that LC-VLP outperforms state-of-the-art methods in both circular- and rectangular-LED scenarios, achieving reductions of over 40% in position error and 25% in rotation error. Experiments further show that LC-VLP can achieve an average position accuracy of less than 4 cm.
Self-motion as a structural prior for coherent and robust formation of cognitive maps
Dec 23, 2025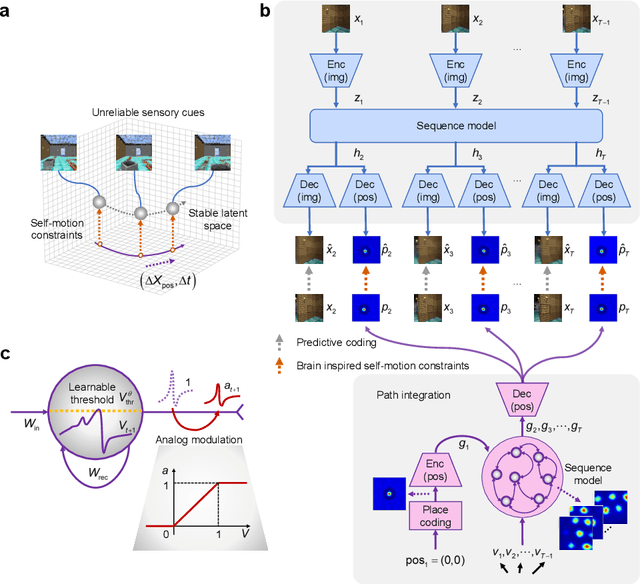
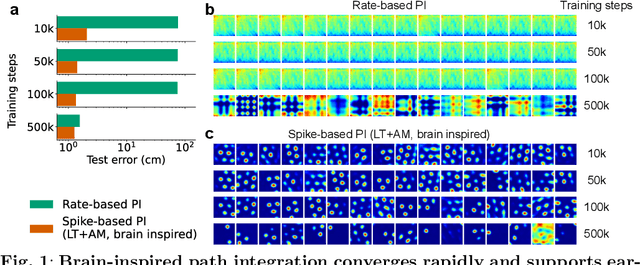
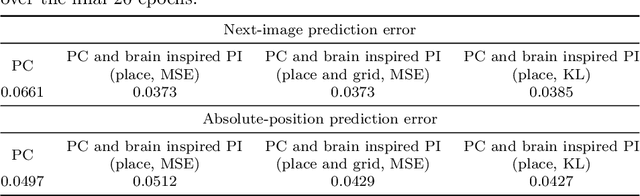
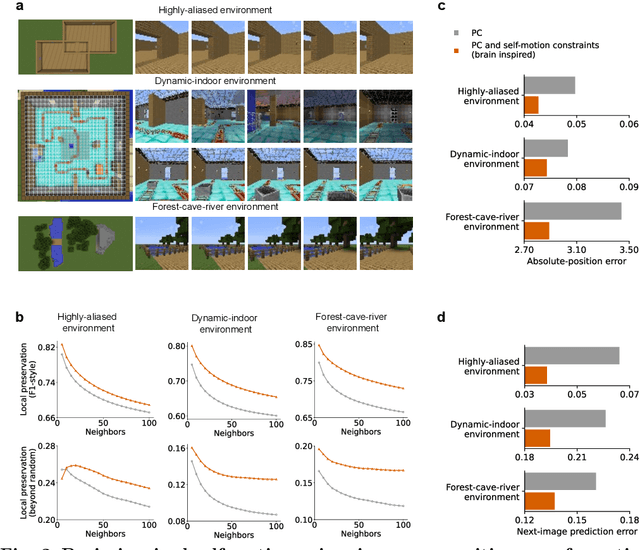
Most computational accounts of cognitive maps assume that stability is achieved primarily through sensory anchoring, with self-motion contributing to incremental positional updates only. However, biological spatial representations often remain coherent even when sensory cues degrade or conflict, suggesting that self-motion may play a deeper organizational role. Here, we show that self-motion can act as a structural prior that actively organizes the geometry of learned cognitive maps. We embed a path-integration-based motion prior in a predictive-coding framework, implemented using a capacity-efficient, brain-inspired recurrent mechanism combining spiking dynamics, analog modulation and adaptive thresholds. Across highly aliased, dynamically changing and naturalistic environments, this structural prior consistently stabilizes map formation, improving local topological fidelity, global positional accuracy and next-step prediction under sensory ambiguity. Mechanistic analyses reveal that the motion prior itself encodes geometrically precise trajectories under tight constraints of internal states and generalizes zero-shot to unseen environments, outperforming simpler motion-based constraints. Finally, deployment on a quadrupedal robot demonstrates that motion-derived structural priors enhance online landmark-based navigation under real-world sensory variability. Together, these results reframe self-motion as an organizing scaffold for coherent spatial representations, showing how brain-inspired principles can systematically strengthen spatial intelligence in embodied artificial agents.
Fusing Bluetooth with Pedestrian Dead Reckoning: A Floor Plan-Assisted Positioning Approach
Apr 14, 2025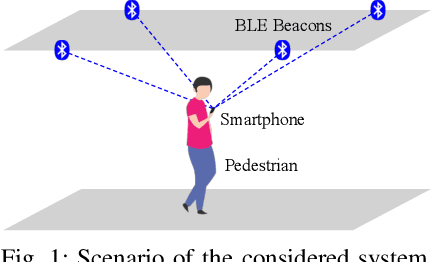
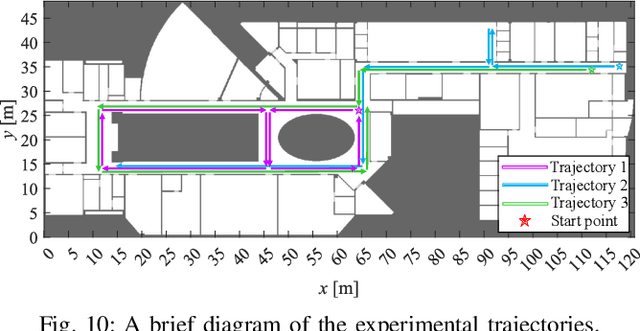
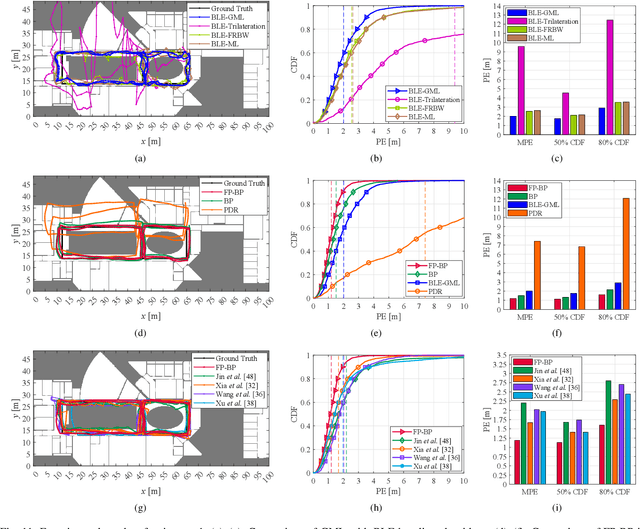
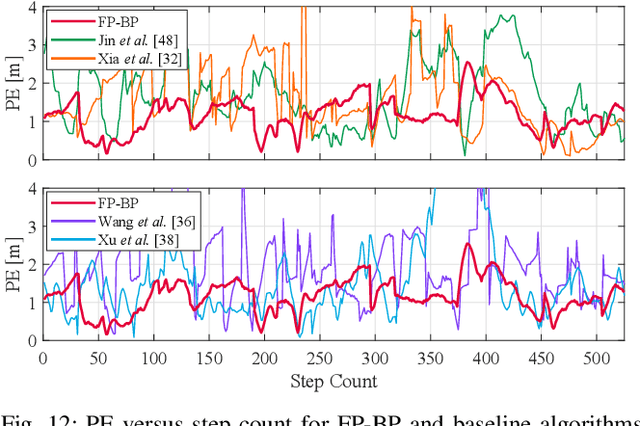
Floor plans can provide valuable prior information that helps enhance the accuracy of indoor positioning systems. However, existing research typically faces challenges in efficiently leveraging floor plan information and applying it to complex indoor layouts. To fully exploit information from floor plans for positioning, we propose a floor plan-assisted fusion positioning algorithm (FP-BP) using Bluetooth low energy (BLE) and pedestrian dead reckoning (PDR). In the considered system, a user holding a smartphone walks through a positioning area with BLE beacons installed on the ceiling, and can locate himself in real time. In particular, FP-BP consists of two phases. In the offline phase, FP-BP programmatically extracts map features from a stylized floor plan based on their binary masks, and constructs a mapping function to identify the corresponding map feature of any given position on the map. In the online phase, FP-BP continuously computes BLE positions and PDR results from BLE signals and smartphone sensors, where a novel grid-based maximum likelihood estimation (GML) algorithm is introduced to enhance BLE positioning. Then, a particle filter is used to fuse them and obtain an initial estimate. Finally, FP-BP performs post-position correction to obtain the final position based on its specific map feature. Experimental results show that FP-BP can achieve a real-time mean positioning accuracy of 1.19 m, representing an improvement of over 28% compared to existing floor plan-fused baseline algorithms.
Continual Learning of Multiple Cognitive Functions with Brain-inspired Temporal Development Mechanism
Apr 08, 2025Cognitive functions in current artificial intelligence networks are tied to the exponential increase in network scale, whereas the human brain can continuously learn hundreds of cognitive functions with remarkably low energy consumption. This advantage is in part due to the brain cross-regional temporal development mechanisms, where the progressive formation, reorganization, and pruning of connections from basic to advanced regions, facilitate knowledge transfer and prevent network redundancy. Inspired by these, we propose the Continual Learning of Multiple Cognitive Functions with Brain-inspired Temporal Development Mechanism(TD-MCL), enabling cognitive enhancement from simple to complex in Perception-Motor-Interaction(PMI) multiple cognitive task scenarios. The TD-MCL model proposes the sequential evolution of long-range connections between different cognitive modules to promote positive knowledge transfer, while using feedback-guided local connection inhibition and pruning to effectively eliminate redundancies in previous tasks, reducing energy consumption while preserving acquired knowledge. Experiments show that the proposed method can achieve continual learning capabilities while reducing network scale, without introducing regularization, replay, or freezing strategies, and achieving superior accuracy on new tasks compared to direct learning. The proposed method shows that the brain's developmental mechanisms offer a valuable reference for exploring biologically plausible, low-energy enhancements of general cognitive abilities.
Evolving Efficient Genetic Encoding for Deep Spiking Neural Networks
Nov 11, 2024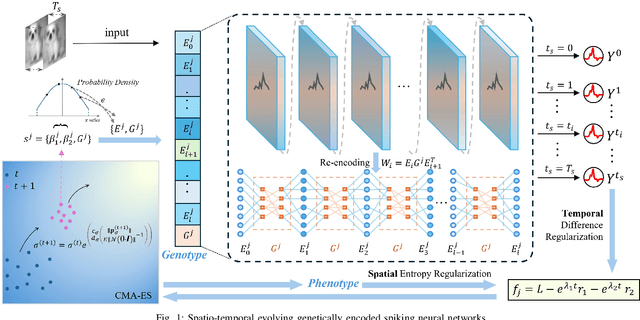
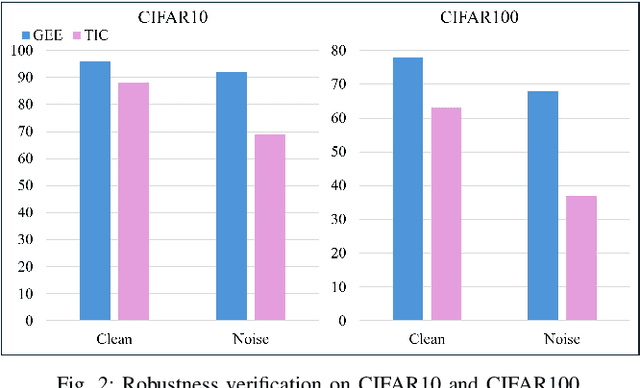
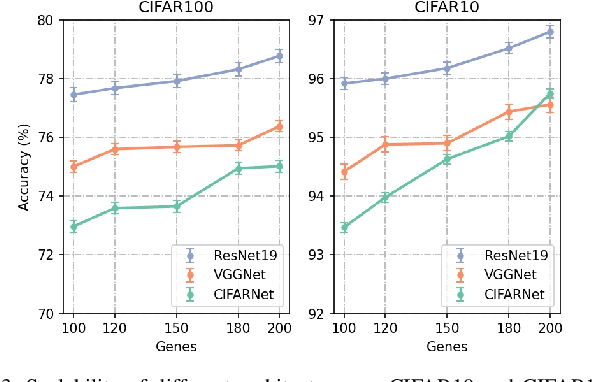
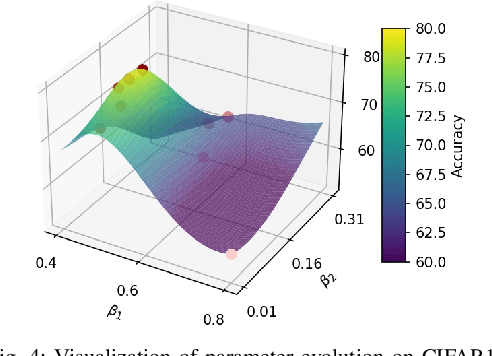
By exploiting discrete signal processing and simulating brain neuron communication, Spiking Neural Networks (SNNs) offer a low-energy alternative to Artificial Neural Networks (ANNs). However, existing SNN models, still face high computational costs due to the numerous time steps as well as network depth and scale. The tens of billions of neurons and trillions of synapses in the human brain are developed from only 20,000 genes, which inspires us to design an efficient genetic encoding strategy that dynamic evolves to regulate large-scale deep SNNs at low cost. Therefore, we first propose a genetically scaled SNN encoding scheme that incorporates globally shared genetic interactions to indirectly optimize neuronal encoding instead of weight, which obviously brings about reductions in parameters and energy consumption. Then, a spatio-temporal evolutionary framework is designed to optimize the inherently initial wiring rules. Two dynamic regularization operators in the fitness function evolve the neuronal encoding to a suitable distribution and enhance information quality of the genetic interaction respectively, substantially accelerating evolutionary speed and improving efficiency. Experiments show that our approach compresses parameters by approximately 50\% to 80\%, while outperforming models on the same architectures by 0.21\% to 4.38\% on CIFAR-10, CIFAR-100 and ImageNet. In summary, the consistent trends of the proposed genetically encoded spatio-temporal evolution across different datasets and architectures highlight its significant enhancements in terms of efficiency, broad scalability and robustness, demonstrating the advantages of the brain-inspired evolutionary genetic coding for SNN optimization.
Brain-inspired and Self-based Artificial Intelligence
Feb 29, 2024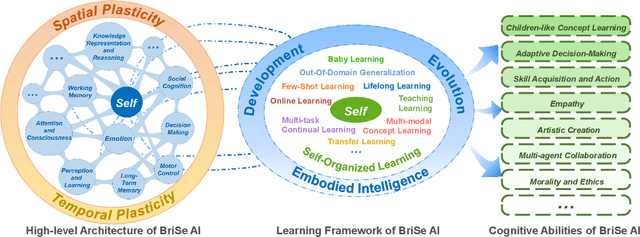
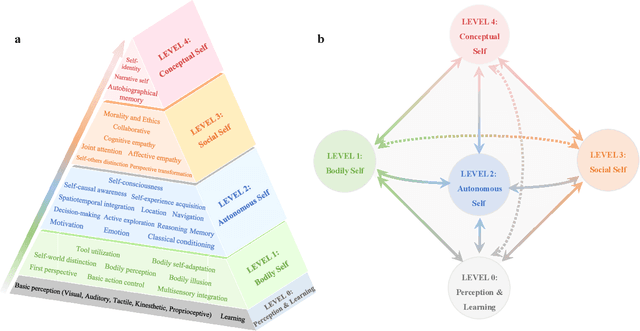


The question "Can machines think?" and the Turing Test to assess whether machines could achieve human-level intelligence is one of the roots of AI. With the philosophical argument "I think, therefore I am", this paper challenge the idea of a "thinking machine" supported by current AIs since there is no sense of self in them. Current artificial intelligence is only seemingly intelligent information processing and does not truly understand or be subjectively aware of oneself and perceive the world with the self as human intelligence does. In this paper, we introduce a Brain-inspired and Self-based Artificial Intelligence (BriSe AI) paradigm. This BriSe AI paradigm is dedicated to coordinating various cognitive functions and learning strategies in a self-organized manner to build human-level AI models and robotic applications. Specifically, BriSe AI emphasizes the crucial role of the Self in shaping the future AI, rooted with a practical hierarchical Self framework, including Perception and Learning, Bodily Self, Autonomous Self, Social Self, and Conceptual Self. The hierarchical framework of the Self highlights self-based environment perception, self-bodily modeling, autonomous interaction with the environment, social interaction and collaboration with others, and even more abstract understanding of the Self. Furthermore, the positive mutual promotion and support among multiple levels of Self, as well as between Self and learning, enhance the BriSe AI's conscious understanding of information and flexible adaptation to complex environments, serving as a driving force propelling BriSe AI towards real Artificial General Intelligence.
Adaptive Reorganization of Neural Pathways for Continual Learning with Hybrid Spiking Neural Networks
Sep 18, 2023



The human brain can self-organize rich and diverse sparse neural pathways to incrementally master hundreds of cognitive tasks. However, most existing continual learning algorithms for deep artificial and spiking neural networks are unable to adequately auto-regulate the limited resources in the network, which leads to performance drop along with energy consumption rise as the increase of tasks. In this paper, we propose a brain-inspired continual learning algorithm with adaptive reorganization of neural pathways, which employs Self-Organizing Regulation networks to reorganize the single and limited Spiking Neural Network (SOR-SNN) into rich sparse neural pathways to efficiently cope with incremental tasks. The proposed model demonstrates consistent superiority in performance, energy consumption, and memory capacity on diverse continual learning tasks ranging from child-like simple to complex tasks, as well as on generalized CIFAR100 and ImageNet datasets. In particular, the SOR-SNN model excels at learning more complex tasks as well as more tasks, and is able to integrate the past learned knowledge with the information from the current task, showing the backward transfer ability to facilitate the old tasks. Meanwhile, the proposed model exhibits self-repairing ability to irreversible damage and for pruned networks, could automatically allocate new pathway from the retained network to recover memory for forgotten knowledge.
Brain-inspired Evolutionary Architectures for Spiking Neural Networks
Sep 11, 2023



The complex and unique neural network topology of the human brain formed through natural evolution enables it to perform multiple cognitive functions simultaneously. Automated evolutionary mechanisms of biological network structure inspire us to explore efficient architectural optimization for Spiking Neural Networks (SNNs). Instead of manually designed fixed architectures or hierarchical Network Architecture Search (NAS), this paper evolves SNNs architecture by incorporating brain-inspired local modular structure and global cross-module connectivity. Locally, the brain region-inspired module consists of multiple neural motifs with excitatory and inhibitory connections; Globally, we evolve free connections among modules, including long-term cross-module feedforward and feedback connections. We further introduce an efficient multi-objective evolutionary algorithm based on a few-shot performance predictor, endowing SNNs with high performance, efficiency and low energy consumption. Extensive experiments on static datasets (CIFAR10, CIFAR100) and neuromorphic datasets (CIFAR10-DVS, DVS128-Gesture) demonstrate that our proposed model boosts energy efficiency, archiving consistent and remarkable performance. This work explores brain-inspired neural architectures suitable for SNNs and also provides preliminary insights into the evolutionary mechanisms of biological neural networks in the human brain.
Enhancing Efficient Continual Learning with Dynamic Structure Development of Spiking Neural Networks
Aug 09, 2023
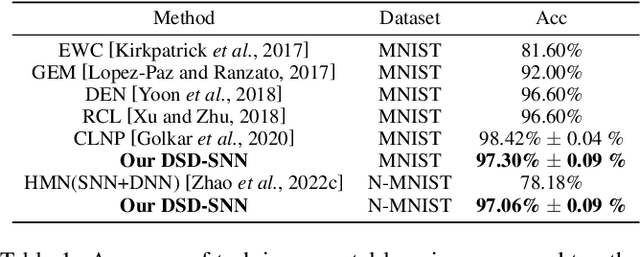


Children possess the ability to learn multiple cognitive tasks sequentially, which is a major challenge toward the long-term goal of artificial general intelligence. Existing continual learning frameworks are usually applicable to Deep Neural Networks (DNNs) and lack the exploration on more brain-inspired, energy-efficient Spiking Neural Networks (SNNs). Drawing on continual learning mechanisms during child growth and development, we propose Dynamic Structure Development of Spiking Neural Networks (DSD-SNN) for efficient and adaptive continual learning. When learning a sequence of tasks, the DSD-SNN dynamically assigns and grows new neurons to new tasks and prunes redundant neurons, thereby increasing memory capacity and reducing computational overhead. In addition, the overlapping shared structure helps to quickly leverage all acquired knowledge to new tasks, empowering a single network capable of supporting multiple incremental tasks (without the separate sub-network mask for each task). We validate the effectiveness of the proposed model on multiple class incremental learning and task incremental learning benchmarks. Extensive experiments demonstrated that our model could significantly improve performance, learning speed and memory capacity, and reduce computational overhead. Besides, our DSD-SNN model achieves comparable performance with the DNNs-based methods, and significantly outperforms the state-of-the-art (SOTA) performance for existing SNNs-based continual learning methods.
Multi-scale Evolutionary Neural Architecture Search for Deep Spiking Neural Networks
Apr 21, 2023



Spiking Neural Networks (SNNs) have received considerable attention not only for their superiority in energy efficient with discrete signal processing, but also for their natural suitability to integrate multi-scale biological plasticity. However, most SNNs directly adopt the structure of the well-established DNN, rarely automatically design Neural Architecture Search (NAS) for SNNs. The neural motifs topology, modular regional structure and global cross-brain region connection of the human brain are the product of natural evolution and can serve as a perfect reference for designing brain-inspired SNN architecture. In this paper, we propose a Multi-Scale Evolutionary Neural Architecture Search (MSE-NAS) for SNN, simultaneously considering micro-, meso- and macro-scale brain topologies as the evolutionary search space. MSE-NAS evolves individual neuron operation, self-organized integration of multiple circuit motifs, and global connectivity across motifs through a brain-inspired indirect evaluation function, Representational Dissimilarity Matrices (RDMs). This training-free fitness function could greatly reduce computational consumption and NAS's time, and its task-independent property enables the searched SNNs to exhibit excellent transferbility and scalability. Extensive experiments demonstrate that the proposed algorithm achieves state-of-the-art (SOTA) performance with shorter simulation steps on static datasets (CIFAR10, CIFAR100) and neuromorphic datasets (CIFAR10-DVS and DVS128-Gesture). The thorough analysis also illustrates the significant performance improvement and consistent bio-interpretability deriving from the topological evolution at different scales and the RDMs fitness function.