 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating brain-inspired mechanisms for multimodal learning in artificial intelligence
May 15, 2025Multimodal learning enhances the perceptual capabilities of cognitive systems by integrating information from different sensory modalities. However, existing multimodal fusion research typically assumes static integration, not fully incorporating key dynamic mechanisms found in the brain. Specifically, the brain exhibits an inverse effectiveness phenomenon, wherein weaker unimodal cues yield stronger multisensory integration benefits; conversely, when individual modal cues are stronger, the effect of fusion is diminished. This mechanism enables biological systems to achieve robust cognition even with scarce or noisy perceptual cues. Inspired by this biological mechanism, we explore the relationship between multimodal output and information from individual modalities, proposing an inverse effectiveness driven multimodal fusion (IEMF) strategy. By incorporating this strategy into neural networks, we achieve more efficient integration with improved model performance and computational efficiency, demonstrating up to 50% reduction in computational cost across diverse fusion methods. We conduct experiments on audio-visual classification, continual learning, and question answering tasks to validate our method. Results consistently demonstrate that our method performs excellently in these tasks. To verify universality and generalization, we also conduct experiments on Artificial Neural Networks (ANN) and Spiking Neural Networks (SNN), with results showing good adaptability to both network types. Our research emphasizes the potential of incorporating biologically inspired mechanisms into multimodal networks and provides promising directions for the future development of multimodal artificial intelligence. The code is available at https://github.com/Brain-Cog-Lab/IEMF.
CACE-Net: Co-guidance Attention and Contrastive Enhancement for Effective Audio-Visual Event Localization
Aug 04, 2024

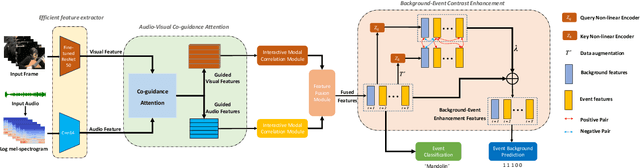
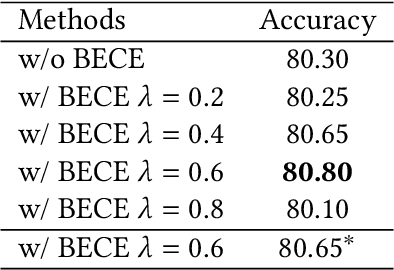
The audio-visual event localization task requires identifying concurrent visual and auditory events from unconstrained videos within a network model, locating them, and classifying their category. The efficient extraction and integration of audio and visual modal information have always been challenging in this field. In this paper, we introduce CACE-Net, which differs from most existing methods that solely use audio signals to guide visual information. We propose an audio-visual co-guidance attention mechanism that allows for adaptive bi-directional cross-modal attentional guidance between audio and visual information, thus reducing inconsistencies between modalities. Moreover, we have observed that existing methods have difficulty distinguishing between similar background and event and lack the fine-grained features for event classification. Consequently, we employ background-event contrast enhancement to increase the discrimination of fused feature and fine-tuned pre-trained model to extract more refined and discernible features from complex multimodal inputs. Specifically, we have enhanced the model's ability to discern subtle differences between event and background and improved the accuracy of event classification in our model. Experiments on the AVE dataset demonstrate that CACE-Net sets a new benchmark in the audio-visual event localization task, proving the effectiveness of our proposed methods in handling complex multimodal learning and event localization in unconstrained videos. Code is available at https://github.com/Brain-Cog-Lab/CACE-Net.
Spiking Neural Networks with Consistent Mapping Relations Allow High-Accuracy Inference
Jun 08, 2024Spike-based neuromorphic hardware has demonstrated substantial potential in low energy consumption and efficient inference. However, the direct training of deep spiking neural networks is challenging, and conversion-based methods still require substantial time delay owing to unresolved conversion errors. We determine that the primary source of the conversion errors stems from the inconsistency between the mapping relationship of traditional activation functions and the input-output dynamics of spike neurons. To counter this, we introduce the Consistent ANN-SNN Conversion (CASC) framework. It includes the Consistent IF (CIF) neuron model, specifically contrived to minimize the influence of the stable point's upper bound, and the wake-sleep conversion (WSC) method, synergistically ensuring the uniformity of neuron behavior. This method theoretically achieves a loss-free conversion, markedly diminishing time delays and improving inference performance in extensive classification and object detection tasks. Our approach offers a viable pathway toward more efficient and effective neuromorphic systems.
Brain-inspired and Self-based Artificial Intelligence
Feb 29, 2024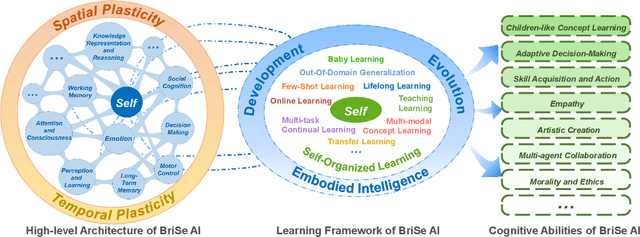
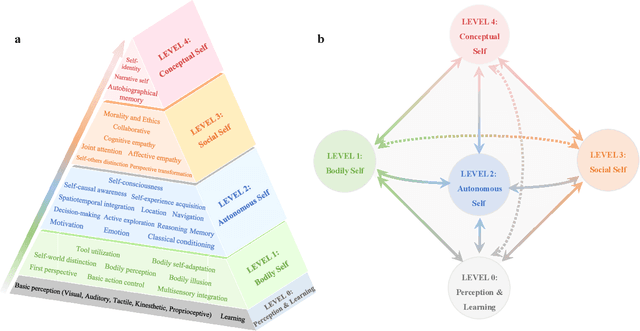


The question "Can machines think?" and the Turing Test to assess whether machines could achieve human-level intelligence is one of the roots of AI. With the philosophical argument "I think, therefore I am", this paper challenge the idea of a "thinking machine" supported by current AIs since there is no sense of self in them. Current artificial intelligence is only seemingly intelligent information processing and does not truly understand or be subjectively aware of oneself and perceive the world with the self as human intelligence does. In this paper, we introduce a Brain-inspired and Self-based Artificial Intelligence (BriSe AI) paradigm. This BriSe AI paradigm is dedicated to coordinating various cognitive functions and learning strategies in a self-organized manner to build human-level AI models and robotic applications. Specifically, BriSe AI emphasizes the crucial role of the Self in shaping the future AI, rooted with a practical hierarchical Self framework, including Perception and Learning, Bodily Self, Autonomous Self, Social Self, and Conceptual Self. The hierarchical framework of the Self highlights self-based environment perception, self-bodily modeling, autonomous interaction with the environment, social interaction and collaboration with others, and even more abstract understanding of the Self. Furthermore, the positive mutual promotion and support among multiple levels of Self, as well as between Self and learning, enhance the BriSe AI's conscious understanding of information and flexible adaptation to complex environments, serving as a driving force propelling BriSe AI towards real Artificial General Intelligence.
Adaptive Reorganization of Neural Pathways for Continual Learning with Hybrid Spiking Neural Networks
Sep 18, 2023



The human brain can self-organize rich and diverse sparse neural pathways to incrementally master hundreds of cognitive tasks. However, most existing continual learning algorithms for deep artificial and spiking neural networks are unable to adequately auto-regulate the limited resources in the network, which leads to performance drop along with energy consumption rise as the increase of tasks. In this paper, we propose a brain-inspired continual learning algorithm with adaptive reorganization of neural pathways, which employs Self-Organizing Regulation networks to reorganize the single and limited Spiking Neural Network (SOR-SNN) into rich sparse neural pathways to efficiently cope with incremental tasks. The proposed model demonstrates consistent superiority in performance, energy consumption, and memory capacity on diverse continual learning tasks ranging from child-like simple to complex tasks, as well as on generalized CIFAR100 and ImageNet datasets. In particular, the SOR-SNN model excels at learning more complex tasks as well as more tasks, and is able to integrate the past learned knowledge with the information from the current task, showing the backward transfer ability to facilitate the old tasks. Meanwhile, the proposed model exhibits self-repairing ability to irreversible damage and for pruned networks, could automatically allocate new pathway from the retained network to recover memory for forgotten knowledge.
Improving the Performance of Spiking Neural Networks on Event-based Datasets with Knowledge Transfer
Mar 23, 2023



Spiking neural networks (SNNs) have rich spatial-temporal dynamics, which are suitable for processing neuromorphic, event-based data. However, event-based datasets are usually less annotated than static datasets used in traditional deep learning. Small data scale makes SNNs prone to overfitting and limits the performance of the SNN. To enhance the generalizability of SNNs on event-based datasets, we propose a knowledge-transfer framework that leverages static images to assist in the training on neuromorphic datasets. Our method proposes domain loss and semantic loss to exploit both domain-invariant and unique features of these two domains, providing SNNs with more generalized knowledge for subsequent targeted training on neuromorphic data. Specifically, domain loss aligns the feature space and aims to capture common features between static and event-based images, while semantic loss emphasizes that the differences between samples from different categories should be as large as possible. Experimental results demonstrate that our method outperforms existing methods on all mainstream neuromorphic vision datasets. In particular, we achieve significant performance improvement of 2.7\% and 9.8\% when using only 10\% training data of CIFAR10-DVS and N-Caltech 101 datasets, respectively.
MSAT: Biologically Inspired Multi-Stage Adaptive Threshold for Conversion of Spiking Neural Networks
Mar 23, 2023



Spiking Neural Networks (SNNs) can do inference with low power consumption due to their spike sparsity. ANN-SNN conversion is an efficient way to achieve deep SNNs by converting well-trained Artificial Neural Networks (ANNs). However, the existing methods commonly use constant threshold for conversion, which prevents neurons from rapidly delivering spikes to deeper layers and causes high time delay. In addition, the same response for different inputs may result in information loss during the information transmission. Inspired by the biological model mechanism, we propose a multi-stage adaptive threshold (MSAT). Specifically, for each neuron, the dynamic threshold varies with firing history and input properties and is positively correlated with the average membrane potential and negatively correlated with the rate of depolarization. The self-adaptation to membrane potential and input allows a timely adjustment of the threshold to fire spike faster and transmit more information. Moreover, we analyze the Spikes of Inactivated Neurons error which is pervasive in early time steps and propose spike confidence accordingly as a measurement of confidence about the neurons that correctly deliver spikes. We use such spike confidence in early time steps to determine whether to elicit spike to alleviate this error. Combined with the proposed method, we examine the performance on non-trivial datasets CIFAR-10, CIFAR-100, and ImageNet. We also conduct sentiment classification and speech recognition experiments on the IDBM and Google speech commands datasets respectively. Experiments show near-lossless and lower latency ANN-SNN conversion. To the best of our knowledge, this is the first time to build a biologically inspired multi-stage adaptive threshold for converted SNN, with comparable performance to state-of-the-art methods while improving energy efficiency.
BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation
Jul 18, 2022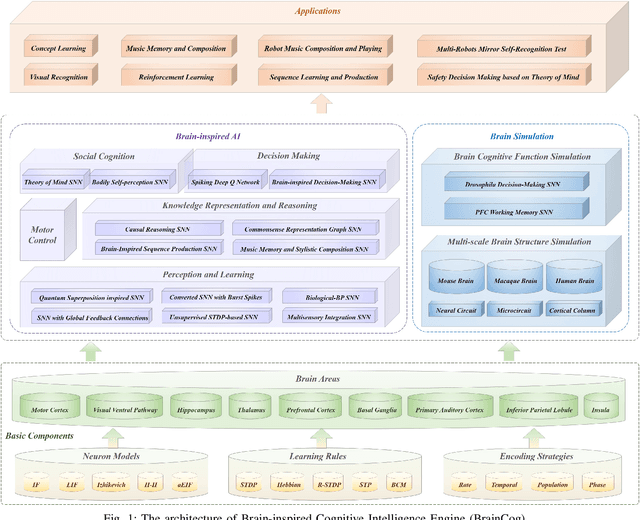
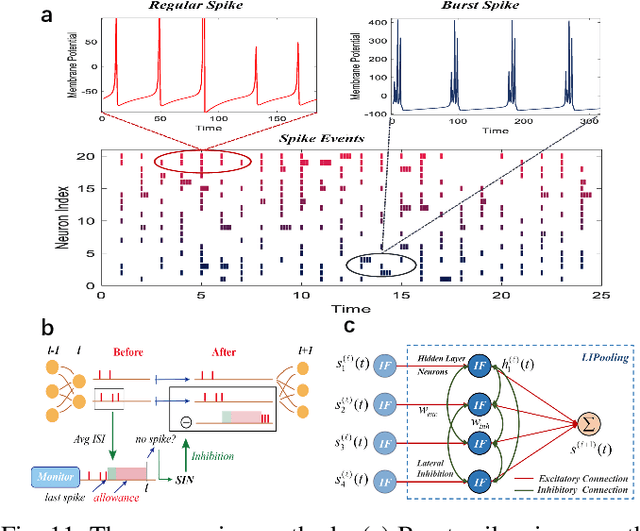
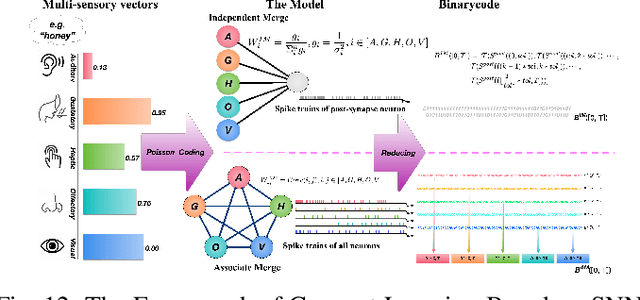
Spiking neural networks (SNNs) have attracted extensive attentions in Brain-inspired Artificial Intelligence and computational neuroscience. They can be used to simulate biological information processing in the brain at multiple scales. More importantly, SNNs serve as an appropriate level of abstraction to bring inspirations from brain and cognition to Artificial Intelligence. In this paper, we present the Brain-inspired Cognitive Intelligence Engine (BrainCog) for creating brain-inspired AI and brain simulation models. BrainCog incorporates different types of spiking neuron models, learning rules, brain areas, etc., as essential modules provided by the platform. Based on these easy-to-use modules, BrainCog supports various brain-inspired cognitive functions, including Perception and Learning, Decision Making, Knowledge Representation and Reasoning, Motor Control, and Social Cognition. These brain-inspired AI models have been effectively validated on various supervised, unsupervised, and reinforcement learning tasks, and they can be used to enable AI models to be with multiple brain-inspired cognitive functions. For brain simulation, BrainCog realizes the function simulation of decision-making, working memory, the structure simulation of the Neural Circuit, and whole brain structure simulation of Mouse brain, Macaque brain, and Human brain. An AI engine named BORN is developed based on BrainCog, and it demonstrates how the components of BrainCog can be integrated and used to build AI models and applications. To enable the scientific quest to decode the nature of biological intelligence and create AI, BrainCog aims to provide essential and easy-to-use building blocks, and infrastructural support to develop brain-inspired spiking neural network based AI, and to simulate the cognitive brains at multiple scales. The online repository of BrainCog can be found at https://github.com/braincog-x.
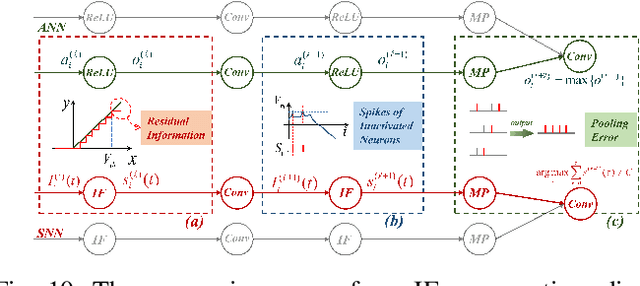
Spike Calibration: Fast and Accurate Conversion of Spiking Neural Network for Object Detection and Segmentation
Jul 06, 2022

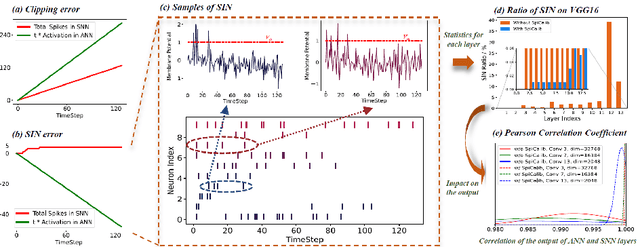

Spiking neural network (SNN) has been attached to great importance due to the properties of high biological plausibility and low energy consumption on neuromorphic hardware. As an efficient method to obtain deep SNN, the conversion method has exhibited high performance on various large-scale datasets. However, it typically suffers from severe performance degradation and high time delays. In particular, most of the previous work focuses on simple classification tasks while ignoring the precise approximation to ANN output. In this paper, we first theoretically analyze the conversion errors and derive the harmful effects of time-varying extremes on synaptic currents. We propose the Spike Calibration (SpiCalib) to eliminate the damage of discrete spikes to the output distribution and modify the LIPooling to allow conversion of the arbitrary MaxPooling layer losslessly. Moreover, Bayesian optimization for optimal normalization parameters is proposed to avoid empirical settings. The experimental results demonstrate the state-of-the-art performance on classification, object detection, and segmentation tasks. To the best of our knowledge, this is the first time to obtain SNN comparable to ANN on these tasks simultaneously. Moreover, we only need 1/50 inference time of the previous work on the detection task and can achieve the same performance under 0.492$\times$ energy consumption of ANN on the segmentation task.
A Performance Evaluation of Local Features for Image Based 3D Reconstruction
Dec 14, 2017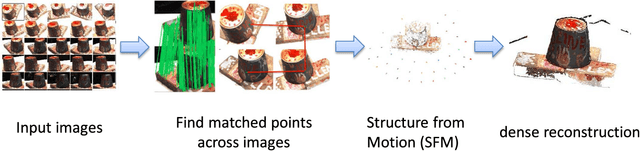

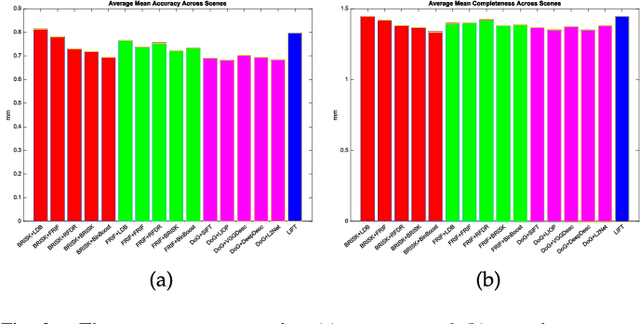
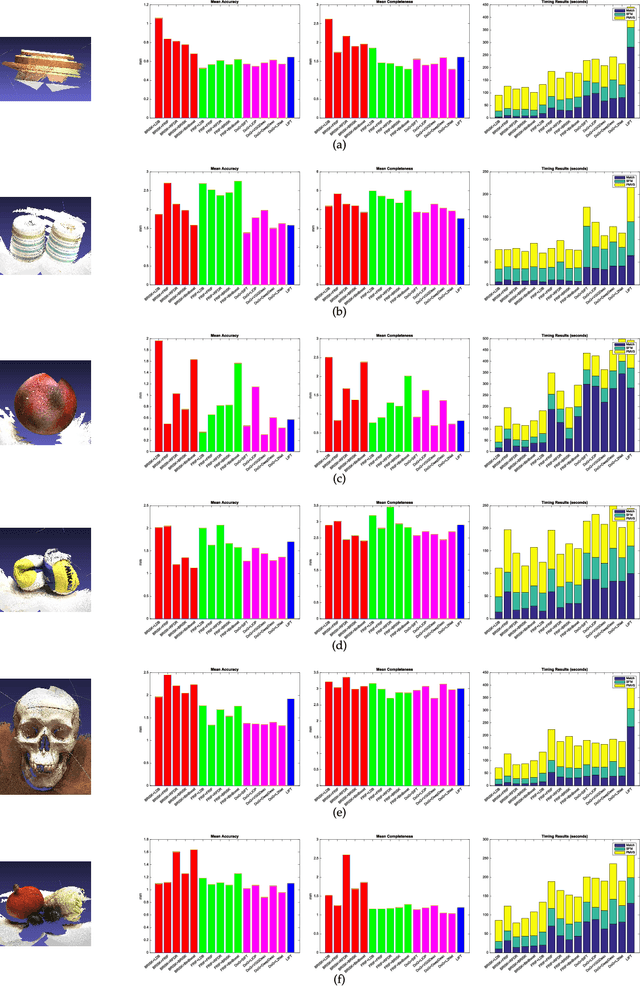
This paper performs a comprehensive and comparative evaluation of the state of the art local features for the task of image based 3D reconstruction. The evaluated local features cover the recently developed ones by using powerful machine learning techniques and the elaborately designed handcrafted features. To obtain a comprehensive evaluation, we choose to include both float type features and binary ones. Meanwhile, two kinds of datasets have been used in this evaluation. One is a dataset of many different scene types with groundtruth 3D points, containing images of different scenes captured at fixed positions, for quantitative performance evaluation of different local features in the controlled image capturing situations. The other dataset contains Internet scale image sets of several landmarks with a lot of unrelated images, which is used for qualitative performance evaluation of different local features in the free image collection situations. Our experimental results show that binary features are competent to reconstruct scenes from controlled image sequences with only a fraction of processing time compared to use float type features. However, for the case of large scale image set with many distracting images, float type features show a clear advantage over binary ones.