 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikiSeeker: Rethinking the Role of Vision-Language Models in Knowledge-Based Visual Question Answering
Apr 07, 2026Multi-modal Retrieval-Augmented Generation (RAG) has emerged as a highly effective paradigm for Knowledge-Based Visual Question Answering (KB-VQA). Despite recent advancements, prevailing methods still primarily depend on images as the retrieval key, and often overlook or misplace the role of Vision-Language Models (VLMs), thereby failing to leverage their potential fully. In this paper, we introduce WikiSeeker, a novel multi-modal RAG framework that bridges these gaps by proposing a multi-modal retriever and redefining the role of VLMs. Rather than serving merely as answer generators, we assign VLMs two specialized agents: a Refiner and an Inspector. The Refiner utilizes the capability of VLMs to rewrite the textual query according to the input image, significantly improving the performance of the multimodal retriever. The Inspector facilitates a decoupled generation strategy by selectively routing reliable retrieved context to another LLM for answer generation, while relying on the VLM's internal knowledge when retrieval is unreliable. Extensive experiments on EVQA, InfoSeek, and M2KR demonstrate that WikiSeeker achieves state-of-the-art performance, with substantial improvements in both retrieval accuracy and answer quality. Our code will be released on https://github.com/zhuyjan/WikiSeeker.
SeaVIS: Sound-Enhanced Association for Online Audio-Visual Instance Segmentation
Mar 02, 2026Recently, an audio-visual instance segmentation (AVIS) task has been introduced, aiming to identify, segment and track individual sounding instances in videos. However, prevailing methods primarily adopt the offline paradigm, that cannot associate detected instances across consecutive clips, making them unsuitable for real-world scenarios that involve continuous video streams. To address this limitation, we introduce SeaVIS, the first online framework designed for audio-visual instance segmentation. SeaVIS leverages the Causal Cross Attention Fusion (CCAF) module to enable efficient online processing, which integrates visual features from the current frame with the entire audio history under strict causal constraints. A major challenge for conventional VIS methods is that appearance-based instance association fails to distinguish between an object's sounding and silent states, resulting in the incorrect segmentation of silent objects. To tackle this, we employ an Audio-Guided Contrastive Learning (AGCL) strategy to generate instance prototypes that encode not only visual appearance but also sounding activity. In this way, instances preserved during per-frame prediction that do not emit sound can be effectively suppressed during instance association process, thereby significantly enhancing the audio-following capability of SeaVIS. Extensive experiments conducted on the AVISeg dataset demonstrate that SeaVIS surpasses existing state-of-the-art models across multiple evaluation metrics while maintaining a competitive inference speed suitable for real-time processing.
Decomposed Object Manipulation via Dual-Actor Policy
Nov 07, 2025Object manipulation, which focuses on learning to perform tasks on similar parts across different types of objects, can be divided into an approaching stage and a manipulation stage. However, previous works often ignore this characteristic of the task and rely on a single policy to directly learn the whole process of object manipulation. To address this problem, we propose a novel Dual-Actor Policy, termed DAP, which explicitly considers different stages and leverages heterogeneous visual priors to enhance each stage. Specifically, we introduce an affordance-based actor to locate the functional part in the manipulation task, thereby improving the approaching process. Following this, we propose a motion flow-based actor to capture the movement of the component, facilitating the manipulation process. Finally, we introduce a decision maker to determine the current stage of DAP and select the corresponding actor. Moreover, existing object manipulation datasets contain few objects and lack the visual priors needed to support training. To address this, we construct a simulated dataset, the Dual-Prior Object Manipulation Dataset, which combines the two visual priors and includes seven tasks, including two challenging long-term, multi-stage tasks. Experimental results on our dataset, the RoboTwin benchmark and real-world scenarios illustrate that our method consistently outperforms the SOTA method by 5.55%, 14.7% and 10.4% on average respectively.
Autoregressive Image Generation with Linear Complexity: A Spatial-Aware Decay Perspective
Jul 02, 2025Autoregressive (AR) models have garnered significant attention in image generation for their ability to effectively capture both local and global structures within visual data. However, prevalent AR models predominantly rely on the transformer architectures, which are beset by quadratic computational complexity concerning input sequence length and substantial memory overhead due to the necessity of maintaining key-value caches. Although linear attention mechanisms have successfully reduced this burden in language models, our initial experiments reveal that they significantly degrade image generation quality because of their inability to capture critical long-range dependencies in visual data. We propose Linear Attention with Spatial-Aware Decay (LASAD), a novel attention mechanism that explicitly preserves genuine 2D spatial relationships within the flattened image sequences by computing position-dependent decay factors based on true 2D spatial location rather than 1D sequence positions. Based on this mechanism, we present LASADGen, an autoregressive image generator that enables selective attention to relevant spatial contexts with linear complexity. Experiments on ImageNet show LASADGen achieves state-of-the-art image generation performance and computational efficiency, bridging the gap between linear attention's efficiency and spatial understanding needed for high-quality generation.
Instance-Level Moving Object Segmentation from a Single Image with Events
Feb 18, 2025Moving object segmentation plays a crucial role in understanding dynamic scenes involving multiple moving objects, while the difficulties lie in taking into account both spatial texture structures and temporal motion cues. Existing methods based on video frames encounter difficulties in distinguishing whether pixel displacements of an object are caused by camera motion or object motion due to the complexities of accurate image-based motion modeling. Recent advances exploit the motion sensitivity of novel event cameras to counter conventional images' inadequate motion modeling capabilities, but instead lead to challenges in segmenting pixel-level object masks due to the lack of dense texture structures in events. To address these two limitations imposed by unimodal settings, we propose the first instance-level moving object segmentation framework that integrates complementary texture and motion cues. Our model incorporates implicit cross-modal masked attention augmentation, explicit contrastive feature learning, and flow-guided motion enhancement to exploit dense texture information from a single image and rich motion information from events, respectively. By leveraging the augmented texture and motion features, we separate mask segmentation from motion classification to handle varying numbers of independently moving objects. Through extensive evaluations on multiple datasets, as well as ablation experiments with different input settings and real-time efficiency analysis of the proposed framework, we believe that our first attempt to incorporate image and event data for practical deployment can provide new insights for future work in event-based motion related works. The source code with model training and pre-trained weights is released at https://npucvr.github.io/EvInsMOS
Pattern Matching in AI Compilers and its Formalization (Extended Version)
Dec 18, 2024



PyPM is a Python-based domain specific language (DSL) for building rewrite-based optimization passes on machine learning computation graphs. Users define individual optimizations by writing (a) patterns that match subgraphs of a computation graph and (b) corresponding rules which replace a matched subgraph with an optimized kernel. PyPM is distinguished from the many other DSLs for defining rewriting passes by its complex and novel pattern language which borrows concepts from logic programming. PyPM patterns can be recursive, nondeterminstic, and can require checking domain-specific constraints such as the shapes of tensors. The PyPM implementation is thus similarly complicated, consisting of thousands of lines of C++ code. In this paper, we present our work on building PyPM, as well as formalizing and distilling and this complexity to an understandable mathematical core. We have developed a formal core calculus expressing the main operations of the PyPM pattern language. We define both a declarative semantics - describing which patterns match which terms - and an algorithmic semantics - an idealized version of the PyPM pattern interpreter - and prove their equivalence. The development is fully mechanized in the Coq proof assistant.
Boosting Gaze Object Prediction via Pixel-level Supervision from Vision Foundation Model
Aug 02, 2024Gaze object prediction (GOP) aims to predict the category and location of the object that a human is looking at. Previous methods utilized box-level supervision to identify the object that a person is looking at, but struggled with semantic ambiguity, ie, a single box may contain several items since objects are close together. The Vision foundation model (VFM) has improved in object segmentation using box prompts, which can reduce confusion by more precisely locating objects, offering advantages for fine-grained prediction of gaze objects. This paper presents a more challenging gaze object segmentation (GOS) task, which involves inferring the pixel-level mask corresponding to the object captured by human gaze behavior. In particular, we propose that the pixel-level supervision provided by VFM can be integrated into gaze object prediction to mitigate semantic ambiguity. This leads to our gaze object detection and segmentation framework that enables accurate pixel-level predictions. Different from previous methods that require additional head input or ignore head features, we propose to automatically obtain head features from scene features to ensure the model's inference efficiency and flexibility in the real world. Moreover, rather than directly fuse features to predict gaze heatmap as in existing methods, which may overlook spatial location and subtle details of the object, we develop a space-to-object gaze regression method to facilitate human-object gaze interaction. Specifically, it first constructs an initial human-object spatial connection, then refines this connection by interacting with semantically clear features in the segmentation branch, ultimately predicting a gaze heatmap for precise localization. Extensive experiments on GOO-Synth and GOO-Real datasets demonstrate the effectiveness of our method.
Reusable Architecture Growth for Continual Stereo Matching
Mar 30, 2024



The remarkable performance of recent stereo depth estimation models benefits from the successful use of convolutional neural networks to regress dense disparity. Akin to most tasks, this needs gathering training data that covers a number of heterogeneous scenes at deployment time. However, training samples are typically acquired continuously in practical applications, making the capability to learn new scenes continually even more crucial. For this purpose, we propose to perform continual stereo matching where a model is tasked to 1) continually learn new scenes, 2) overcome forgetting previously learned scenes, and 3) continuously predict disparities at inference. We achieve this goal by introducing a Reusable Architecture Growth (RAG) framework. RAG leverages task-specific neural unit search and architecture growth to learn new scenes continually in both supervised and self-supervised manners. It can maintain high reusability during growth by reusing previous units while obtaining good performance. Additionally, we present a Scene Router module to adaptively select the scene-specific architecture path at inference. Comprehensive experiments on numerous datasets show that our framework performs impressively in various weather, road, and city circumstances and surpasses the state-of-the-art methods in more challenging cross-dataset settings. Further experiments also demonstrate the adaptability of our method to unseen scenes, which can facilitate end-to-end stereo architecture learning and practical deployment.
ProIn: Learning to Predict Trajectory Based on Progressive Interactions for Autonomous Driving
Mar 25, 2024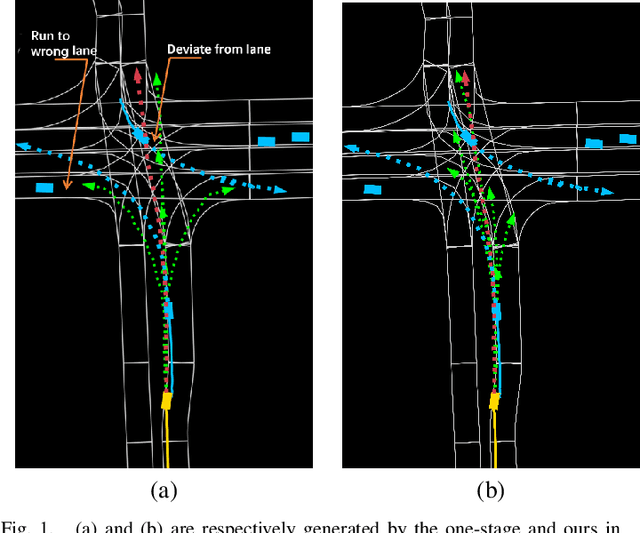
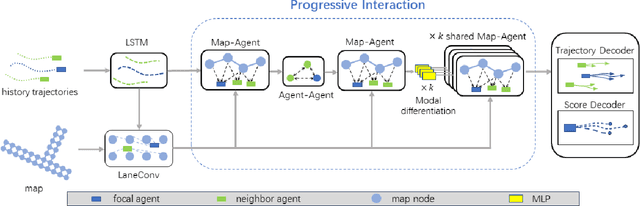
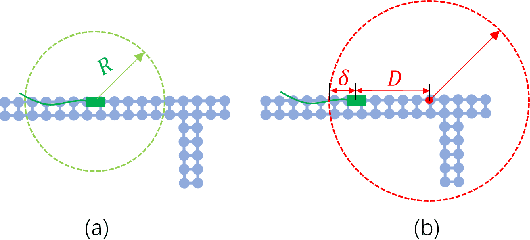
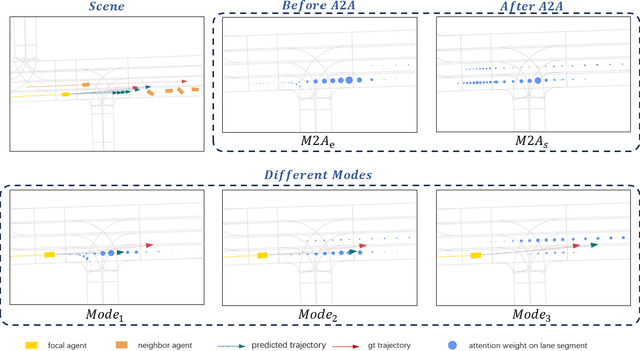
Accurate motion prediction of pedestrians, cyclists, and other surrounding vehicles (all called agents) is very important for autonomous driving. Most existing works capture map information through an one-stage interaction with map by vector-based attention, to provide map constraints for social interaction and multi-modal differentiation. However, these methods have to encode all required map rules into the focal agent's feature, so as to retain all possible intentions' paths while at the meantime to adapt to potential social interaction. In this work, a progressive interaction network is proposed to enable the agent's feature to progressively focus on relevant maps, in order to better learn agents' feature representation capturing the relevant map constraints. The network progressively encode the complex influence of map constraints into the agent's feature through graph convolutions at the following three stages: after historical trajectory encoder, after social interaction, and after multi-modal differentiation. In addition, a weight allocation mechanism is proposed for multi-modal training, so that each mode can obtain learning opportunities from a single-mode ground truth. Experiments have validated the superiority of progressive interactions to the existing one-stage interaction, and demonstrate the effectiveness of each component. Encouraging results were obtained in the challenging benchmarks.
Defying Imbalanced Forgetting in Class Incremental Learning
Mar 22, 2024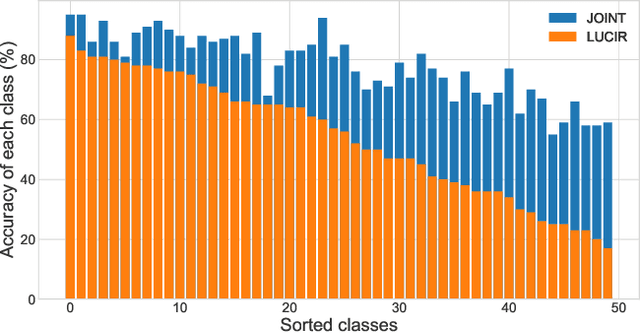
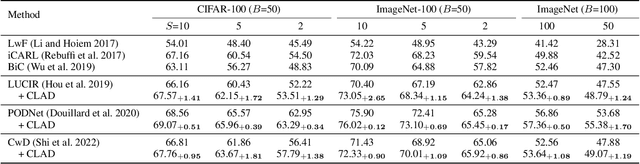
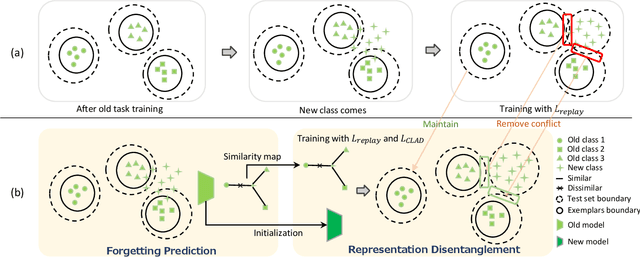
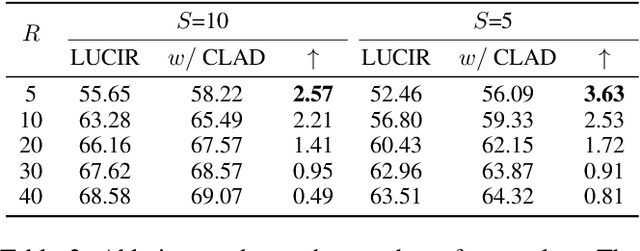
We observe a high level of imbalance in the accuracy of different classes in the same old task for the first time. This intriguing phenomenon, discovered in replay-based Class Incremental Learning (CIL), highlights the imbalanced forgetting of learned classes, as their accuracy is similar before the occurrence of catastrophic forgetting. This discovery remains previously unidentified due to the reliance on average incremental accuracy as the measurement for CIL, which assumes that the accuracy of classes within the same task is similar. However, this assumption is invalid in the face of catastrophic forgetting. Further empirical studies indicate that this imbalanced forgetting is caused by conflicts in representation between semantically similar old and new classes. These conflicts are rooted in the data imbalance present in replay-based CIL methods. Building on these insights, we propose CLass-Aware Disentanglement (CLAD) to predict the old classes that are more likely to be forgotten and enhance their accuracy. Importantly, CLAD can be seamlessly integrated into existing CIL methods. Extensive experiments demonstrate that CLAD consistently improves current replay-based methods, resulting in performance gains of up to 2.56%.