 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfraredGP: Efficient Graph Partitioning via Spectral Graph Neural Networks with Negative Corrections
Aug 27, 2025



Graph partitioning (GP), a.k.a. community detection, is a classic problem that divides nodes of a graph into densely-connected blocks. From a perspective of graph signal processing, we find that graph Laplacian with a negative correction can derive graph frequencies beyond the conventional range $[0, 2]$. To explore whether the low-frequency information beyond this range can encode more informative properties about community structures, we propose InfraredGP. It (\romannumeral1) adopts a spectral GNN as its backbone combined with low-pass filters and a negative correction mechanism, (\romannumeral2) only feeds random inputs to this backbone, (\romannumeral3) derives graph embeddings via one feed-forward propagation (FFP) without any training, and (\romannumeral4) obtains feasible GP results by feeding the derived embeddings to BIRCH. Surprisingly, our experiments demonstrate that based solely on the negative correction mechanism that amplifies low-frequency information beyond $[0, 2]$, InfraredGP can derive distinguishable embeddings for some standard clustering modules (e.g., BIRCH) and obtain high-quality results for GP without any training. Following the IEEE HPEC Graph Challenge benchmark, we evaluate InfraredGP for both static and streaming GP, where InfraredGP can achieve much better efficiency (e.g., 16x-23x faster) and competitive quality over various baselines. We have made our code public at https://github.com/KuroginQin/InfraredGP
End-to-End Out-of-distribution Detection with Self-supervised Sampling
Jul 02, 2023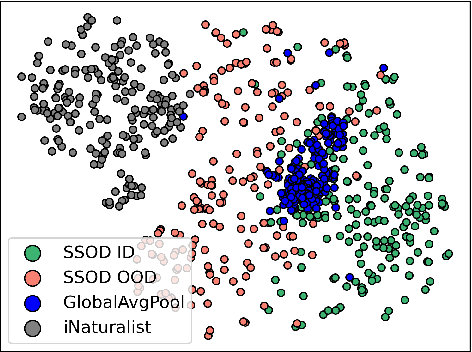
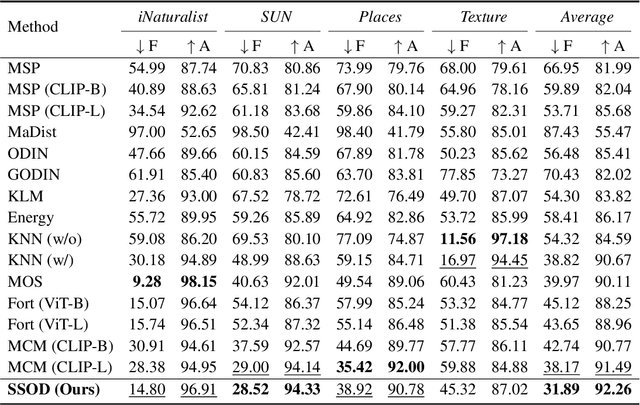

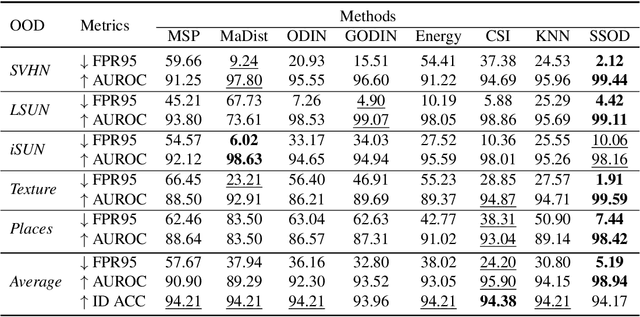
Out-of-distribution (OOD) detection empowers the model trained on the closed set to identify unknown data in the open world. Though many prior techniques have yielded considerable improvements, two crucial obstacles still remain. Firstly, a unified perspective has yet to be presented to view the developed arts with individual designs, which is vital for providing insights into the related directions. Secondly, most research focuses on the post-processing schemes of the pre-trained features while disregarding the superiority of end-to-end training, dramatically limiting the upper bound of OOD detection. To tackle these issues, we propose a general probabilistic framework to interpret many existing methods and an OOD-data-free model, namely Self-supervised Sampling for OOD Detection (SSOD), to unfold the potential of end-to-end learning. SSOD efficiently exploits natural OOD signals from the in-distribution (ID) data based on the local property of convolution. With these supervisions, it jointly optimizes the OOD detection and conventional ID classification. Extensive experiments reveal that SSOD establishes competitive state-of-the-art performance on many large-scale benchmarks, where it outperforms the most recent approaches, such as KNN, by a large margin, e.g., 48.99% to 35.52% on SUN at FPR95.
AutoMatch: A Large-scale Audio Beat Matching Benchmark for Boosting Deep Learning Assistant Video Editing
Mar 03, 2023The explosion of short videos has dramatically reshaped the manners people socialize, yielding a new trend for daily sharing and access to the latest information. These rich video resources, on the one hand, benefited from the popularization of portable devices with cameras, but on the other, they can not be independent of the valuable editing work contributed by numerous video creators. In this paper, we investigate a novel and practical problem, namely audio beat matching (ABM), which aims to recommend the proper transition time stamps based on the background music. This technique helps to ease the labor-intensive work during video editing, saving energy for creators so that they can focus more on the creativity of video content. We formally define the ABM problem and its evaluation protocol. Meanwhile, a large-scale audio dataset, i.e., the AutoMatch with over 87k finely annotated background music, is presented to facilitate this newly opened research direction. To further lay solid foundations for the following study, we also propose a novel model termed BeatX to tackle this challenging task. Alongside, we creatively present the concept of label scope, which eliminates the data imbalance issues and assigns adaptive weights for the ground truth during the training procedure in one stop. Though plentiful short video platforms have flourished for a long time, the relevant research concerning this scenario is not sufficient, and to the best of our knowledge, AutoMatch is the first large-scale dataset to tackle the audio beat matching problem. We hope the released dataset and our competitive baseline can encourage more attention to this line of research. The dataset and codes will be made publicly available.
Free Lunch for Generating Effective Outlier Supervision
Jan 17, 2023
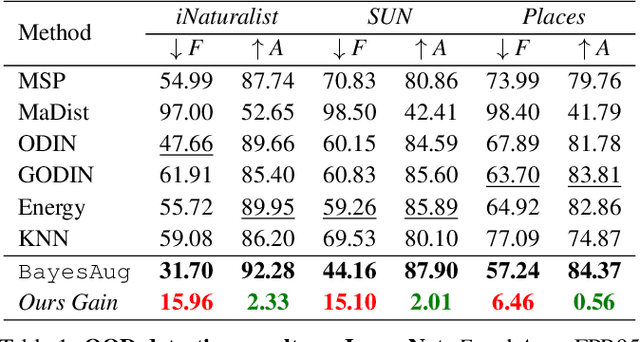
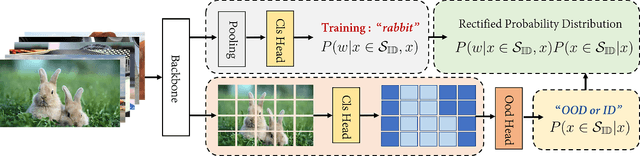
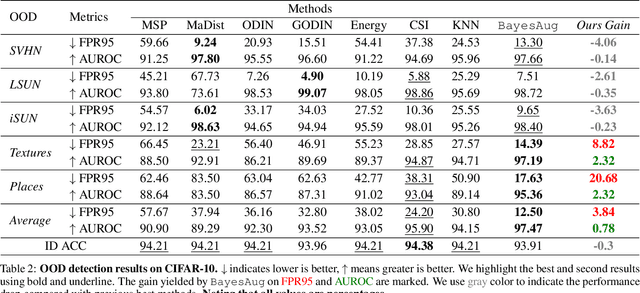
When deployed in practical applications, computer vision systems will encounter numerous unexpected images (\emph{{i.e.}}, out-of-distribution data). Due to the potentially raised safety risks, these aforementioned unseen data should be carefully identified and handled. Generally, existing approaches in dealing with out-of-distribution (OOD) detection mainly focus on the statistical difference between the features of OOD and in-distribution (ID) data extracted by the classifiers. Although many of these schemes have brought considerable performance improvements, reducing the false positive rate (FPR) when processing open-set images, they necessarily lack reliable theoretical analysis and generalization guarantees. Unlike the observed ways, in this paper, we investigate the OOD detection problem based on the Bayes rule and present a convincing description of the reason for failures encountered by conventional classifiers. Concretely, our analysis reveals that refining the probability distribution yielded by the vanilla neural networks is necessary for OOD detection, alleviating the issues of assigning high confidence to OOD data. To achieve this effortlessly, we propose an ultra-effective method to generate near-realistic outlier supervision. Extensive experiments on large-scale benchmarks reveal that our proposed \texttt{BayesAug} significantly reduces the FPR95 over 12.50\% compared with the previous schemes, boosting the reliability of machine learning systems. The code will be made publicly available.
Global Prototype Encoding for Incremental Video Highlights Detection
Sep 14, 2022

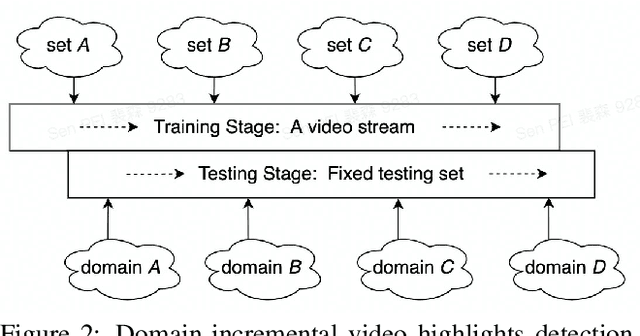
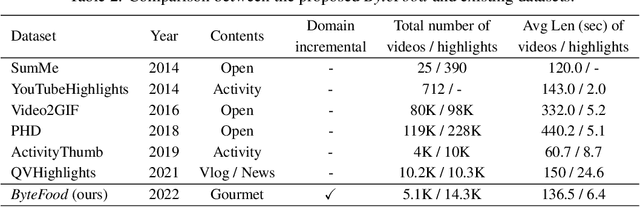
Video highlights detection has been long researched as a topic in computer vision tasks, digging the user-appealing clips out given unexposed raw video inputs. However, in most case, the mainstream methods in this line of research are built on the closed world assumption, where a fixed number of highlight categories is defined properly in advance and need all training data to be available at the same time, and as a result, leads to poor scalability with respect to both the highlight categories and the size of the dataset. To tackle the problem mentioned above, we propose a video highlights detector that is able to learn incrementally, namely \textbf{G}lobal \textbf{P}rototype \textbf{E}ncoding (GPE), capturing newly defined video highlights in the extended dataset via their corresponding prototypes. Alongside, we present a well annotated and costly dataset termed \emph{ByteFood}, including more than 5.1k gourmet videos belongs to four different domains which are \emph{cooking}, \emph{eating}, \emph{food material}, and \emph{presentation} respectively. To the best of our knowledge, this is the first time the incremental learning settings are introduced to video highlights detection, which in turn relieves the burden of training video inputs and promotes the scalability of conventional neural networks in proportion to both the size of the dataset and the quantity of domains. Moreover, the proposed GPE surpasses current incremental learning methods on \emph{ByteFood}, reporting an improvement of 1.57\% mAP at least. The code and dataset will be made available sooner.
Domain Decorrelation with Potential Energy Ranking
Jul 26, 2022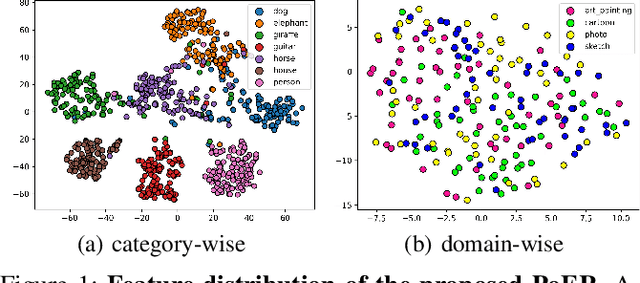
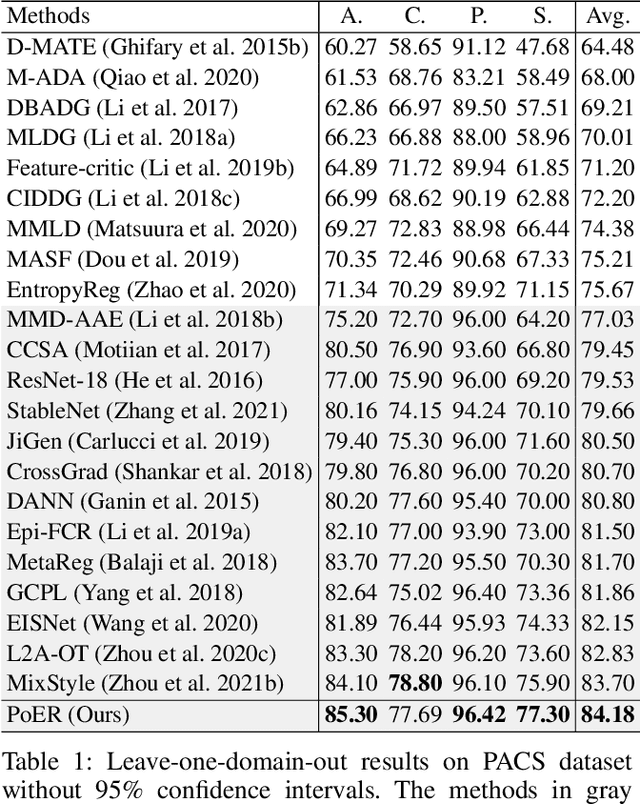

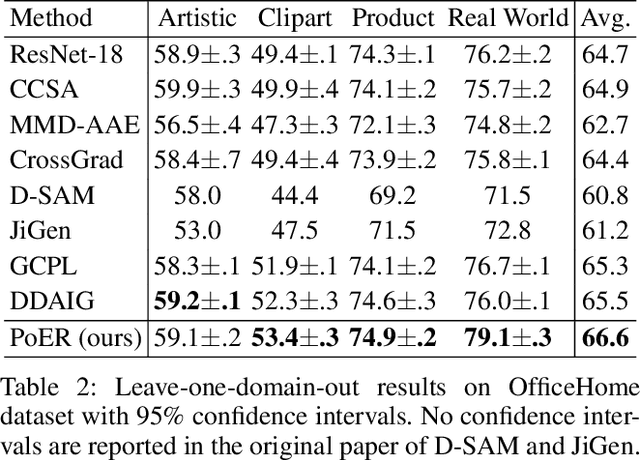
Machine learning systems, especially the methods based on deep learning, enjoy great success in modern computer vision tasks under experimental settings. Generally, these classic deep learning methods are built on the \emph{i.i.d.} assumption, supposing the training and test data are drawn from a similar distribution independently and identically. However, the aforementioned \emph{i.i.d.} assumption is in general unavailable in the real-world scenario, and as a result, leads to sharp performance decay of deep learning algorithms. Behind this, domain shift is one of the primary factors to be blamed. In order to tackle this problem, we propose using \textbf{Po}tential \textbf{E}nergy \textbf{R}anking (PoER) to decouple the object feature and the domain feature (\emph{i.e.,} appearance feature) in given images, promoting the learning of label-discriminative features while filtering out the irrelevant correlations between the objects and the background. PoER helps the neural networks to capture label-related features which contain the domain information first in shallow layers and then distills the label-discriminative representations out progressively, enforcing the neural networks to be aware of the characteristic of objects and background which is vital to the generation of domain-invariant features. PoER reports superior performance on domain generalization benchmarks, improving the average top-1 accuracy by at least 1.20\% compared to the existing methods. Moreover, we use PoER in the ECCV 2022 NICO Challenge\footnote{https://nicochallenge.com}, achieving top place with only a vanilla ResNet-18. The code has been made available at https://github.com/ForeverPs/PoER.
Gradient Concealment: Free Lunch for Defending Adversarial Attacks
May 21, 2022
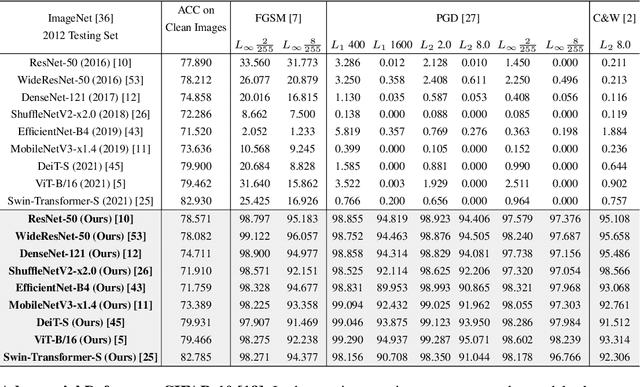
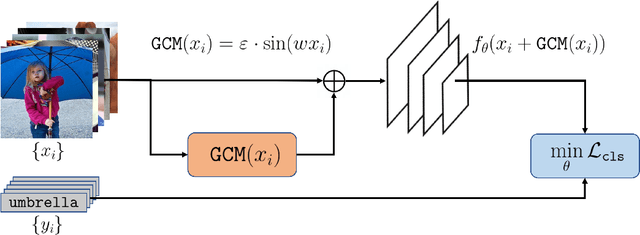

Recent studies show that the deep neural networks (DNNs) have achieved great success in various tasks. However, even the \emph{state-of-the-art} deep learning based classifiers are extremely vulnerable to adversarial examples, resulting in sharp decay of discrimination accuracy in the presence of enormous unknown attacks. Given the fact that neural networks are widely used in the open world scenario which can be safety-critical situations, mitigating the adversarial effects of deep learning methods has become an urgent need. Generally, conventional DNNs can be attacked with a dramatically high success rate since their gradient is exposed thoroughly in the white-box scenario, making it effortless to ruin a well trained classifier with only imperceptible perturbations in the raw data space. For tackling this problem, we propose a plug-and-play layer that is training-free, termed as \textbf{G}radient \textbf{C}oncealment \textbf{M}odule (GCM), concealing the vulnerable direction of gradient while guaranteeing the classification accuracy during the inference time. GCM reports superior defense results on the ImageNet classification benchmark, improving up to 63.41\% top-1 attack robustness (AR) when faced with adversarial inputs compared to the vanilla DNNs. Moreover, we use GCM in the CVPR 2022 Robust Classification Challenge, currently achieving \textbf{2nd} place in Phase II with only a tiny version of ConvNext. The code will be made available.
Boundary Aware Learning for Out-of-distribution Detection
Jan 14, 2022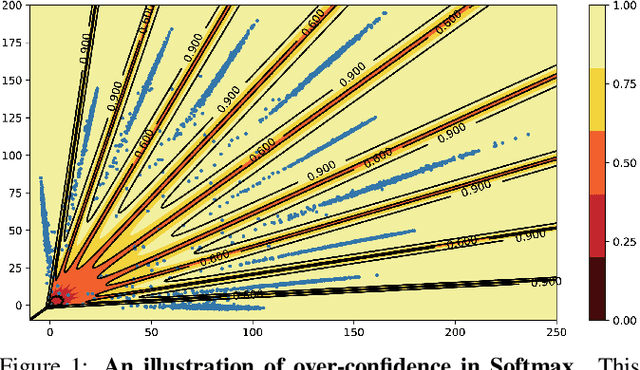
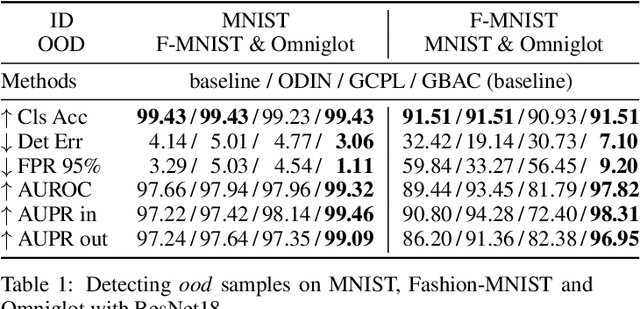
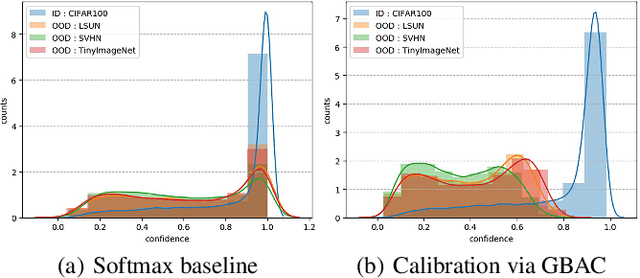
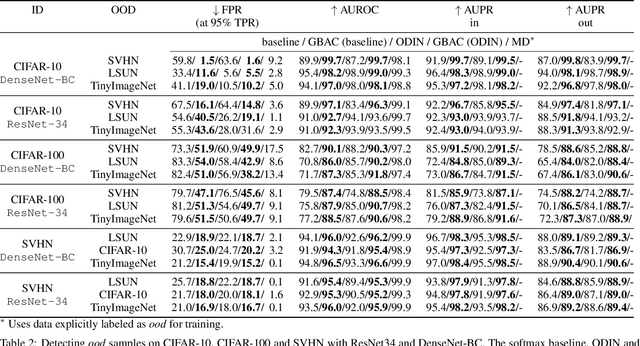
This paper focuses on the problem of detecting out-of-distribution (ood) samples with neural nets. In image recognition tasks, the trained classifier often gives high confidence score for input images which are remote from the in-distribution (id) data, and this has greatly limited its application in real world. For alleviating this problem, we propose a GAN based boundary aware classifier (GBAC) for generating a closed hyperspace which only contains most id data. Our method is based on the fact that the traditional neural net seperates the feature space as several unclosed regions which are not suitable for ood detection. With GBAC as an auxiliary module, the ood data distributed outside the closed hyperspace will be assigned with much lower score, allowing more effective ood detection while maintaining the classification performance. Moreover, we present a fast sampling method for generating hard ood representations which lie on the boundary of pre-mentioned closed hyperspace. Experiments taken on several datasets and neural net architectures promise the effectiveness of GBAC.
Alleviating Mode Collapse in GAN via Diversity Penalty Module
Aug 24, 2021

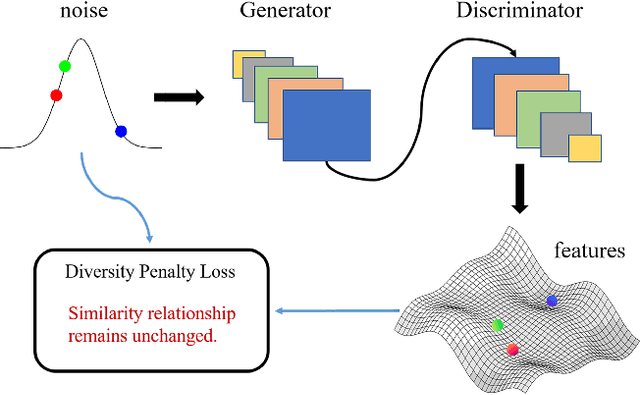

The vanilla GAN (Goodfellow et al. 2014) suffers from mode collapse deeply, which usually manifests as that the images generated by generators tend to have a high similarity amongst them, even though their corresponding latent vectors have been very different. In this paper, we introduce a pluggable diversity penalty module (DPM) to alleviate mode collapse of GANs. It reduces the similarity of image pairs in feature space, i.e., if two latent vectors are different, then we enforce the generator to generate two images with different features. The normalized Gram matrix is used to measure the similarity. We compare the proposed method with Unrolled GAN (Metz et al. 2016), BourGAN (Xiao, Zhong, and Zheng 2018), PacGAN (Lin et al. 2018), VEEGAN (Srivastava et al. 2017) and ALI (Dumoulin et al. 2016) on 2D synthetic dataset, and results show that the diversity penalty module can help GAN capture much more modes of the data distribution. Further, in classification tasks, we apply this method as image data augmentation on MNIST, Fashion- MNIST and CIFAR-10, and the classification testing accuracy is improved by 0.24%, 1.34% and 0.52% compared with WGAN GP (Gulrajani et al. 2017), respectively. In domain translation, diversity penalty module can help StarGAN (Choi et al. 2018) generate more accurate attention masks and accelarate the convergence process. Finally, we quantitatively evaluate the proposed method with IS and FID on CelebA, CIFAR-10, MNIST and Fashion-MNIST, and the results suggest GAN with diversity penalty module gets much higher IS and lower FID compared with some SOTA GAN architectures.