 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressCLIP: Empowering Vision-Language Models for City-wide Image Address Localization
Jul 11, 2024



In this study, we introduce a new problem raised by social media and photojournalism, named Image Address Localization (IAL), which aims to predict the readable textual address where an image was taken. Existing two-stage approaches involve predicting geographical coordinates and converting them into human-readable addresses, which can lead to ambiguity and be resource-intensive. In contrast, we propose an end-to-end framework named AddressCLIP to solve the problem with more semantics, consisting of two key ingredients: i) image-text alignment to align images with addresses and scene captions by contrastive learning, and ii) image-geography matching to constrain image features with the spatial distance in terms of manifold learning. Additionally, we have built three datasets from Pittsburgh and San Francisco on different scales specifically for the IAL problem. Experiments demonstrate that our approach achieves compelling performance on the proposed datasets and outperforms representative transfer learning methods for vision-language models. Furthermore, extensive ablations and visualizations exhibit the effectiveness of the proposed method. The datasets and source code are available at https://github.com/xsx1001/AddressCLIP.
Defying Imbalanced Forgetting in Class Incremental Learning
Mar 22, 2024
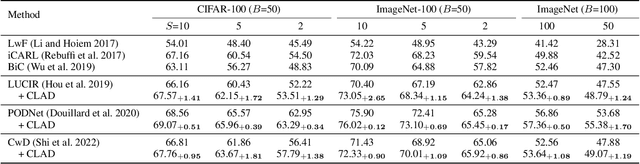
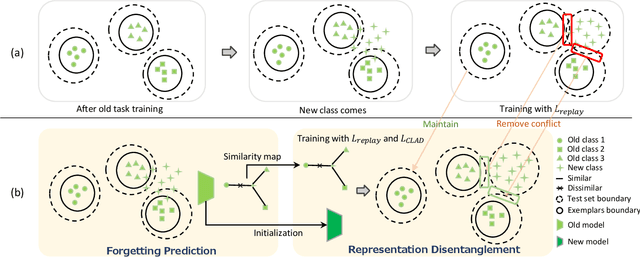
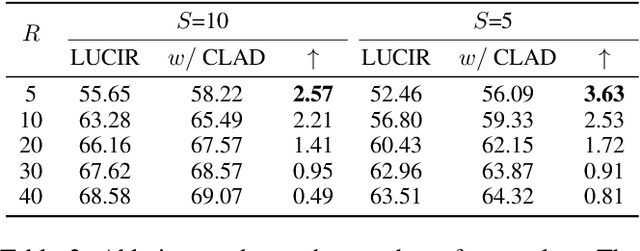
We observe a high level of imbalance in the accuracy of different classes in the same old task for the first time. This intriguing phenomenon, discovered in replay-based Class Incremental Learning (CIL), highlights the imbalanced forgetting of learned classes, as their accuracy is similar before the occurrence of catastrophic forgetting. This discovery remains previously unidentified due to the reliance on average incremental accuracy as the measurement for CIL, which assumes that the accuracy of classes within the same task is similar. However, this assumption is invalid in the face of catastrophic forgetting. Further empirical studies indicate that this imbalanced forgetting is caused by conflicts in representation between semantically similar old and new classes. These conflicts are rooted in the data imbalance present in replay-based CIL methods. Building on these insights, we propose CLass-Aware Disentanglement (CLAD) to predict the old classes that are more likely to be forgotten and enhance their accuracy. Importantly, CLAD can be seamlessly integrated into existing CIL methods. Extensive experiments demonstrate that CLAD consistently improves current replay-based methods, resulting in performance gains of up to 2.56%.
Global Prototype Encoding for Incremental Video Highlights Detection
Sep 14, 2022

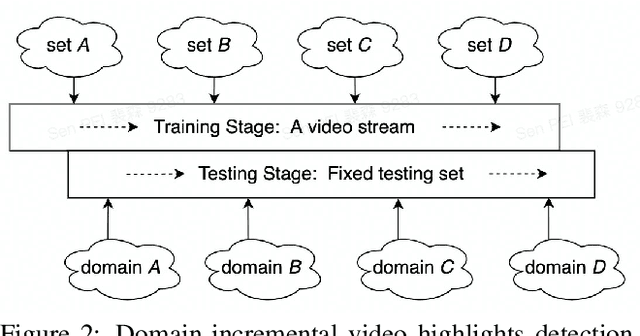
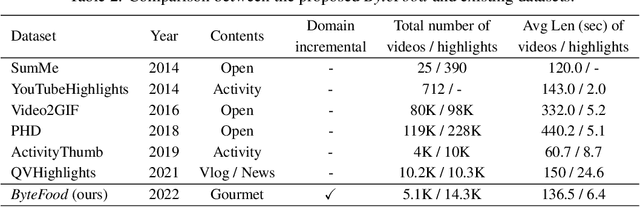
Video highlights detection has been long researched as a topic in computer vision tasks, digging the user-appealing clips out given unexposed raw video inputs. However, in most case, the mainstream methods in this line of research are built on the closed world assumption, where a fixed number of highlight categories is defined properly in advance and need all training data to be available at the same time, and as a result, leads to poor scalability with respect to both the highlight categories and the size of the dataset. To tackle the problem mentioned above, we propose a video highlights detector that is able to learn incrementally, namely \textbf{G}lobal \textbf{P}rototype \textbf{E}ncoding (GPE), capturing newly defined video highlights in the extended dataset via their corresponding prototypes. Alongside, we present a well annotated and costly dataset termed \emph{ByteFood}, including more than 5.1k gourmet videos belongs to four different domains which are \emph{cooking}, \emph{eating}, \emph{food material}, and \emph{presentation} respectively. To the best of our knowledge, this is the first time the incremental learning settings are introduced to video highlights detection, which in turn relieves the burden of training video inputs and promotes the scalability of conventional neural networks in proportion to both the size of the dataset and the quantity of domains. Moreover, the proposed GPE surpasses current incremental learning methods on \emph{ByteFood}, reporting an improvement of 1.57\% mAP at least. The code and dataset will be made available sooner.