 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSL: Sweet Spot Learning for Differentiated Guidance in Agentic Optimization
Jan 30, 2026Reinforcement learning with verifiable rewards has emerged as a powerful paradigm for training intelligent agents. However, existing methods typically employ binary rewards that fail to capture quality differences among trajectories achieving identical outcomes, thereby overlooking potential diversity within the solution space. Inspired by the ``sweet spot'' concept in tennis-the racket's core region that produces optimal hitting effects, we introduce \textbf{S}weet \textbf{S}pot \textbf{L}earning (\textbf{SSL}), a novel framework that provides differentiated guidance for agent optimization. SSL follows a simple yet effective principle: progressively amplified, tiered rewards guide policies toward the sweet-spot region of the solution space. This principle naturally adapts across diverse tasks: visual perception tasks leverage distance-tiered modeling to reward proximity, while complex reasoning tasks reward incremental progress toward promising solutions. We theoretically demonstrate that SSL preserves optimal solution ordering and enhances the gradient signal-to-noise ratio, thereby fostering more directed optimization. Extensive experiments across GUI perception, short/long-term planning, and complex reasoning tasks show consistent improvements over strong baselines on 12 benchmarks, achieving up to 2.5X sample efficiency gains and effective cross-task transferability. Our work establishes SSL as a general principle for training capable and robust agents.
VTCBench: Can Vision-Language Models Understand Long Context with Vision-Text Compression?
Dec 23, 2025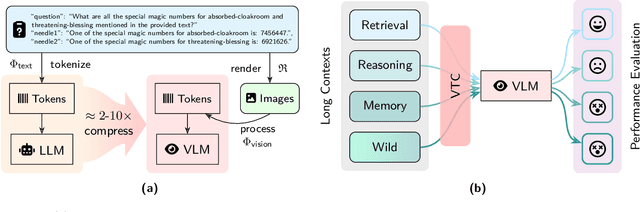

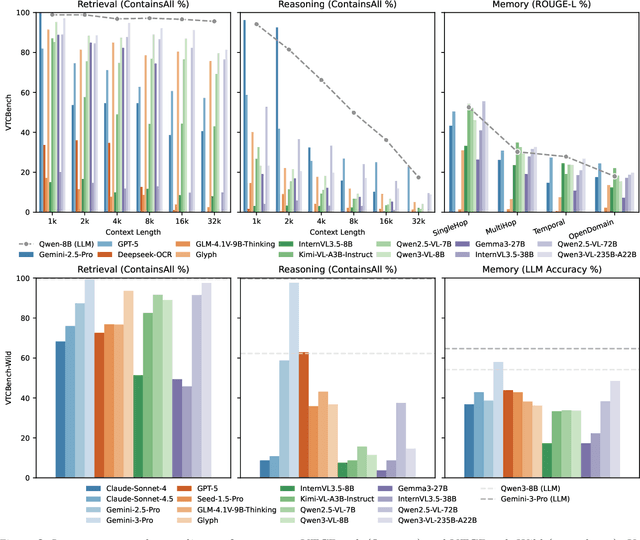
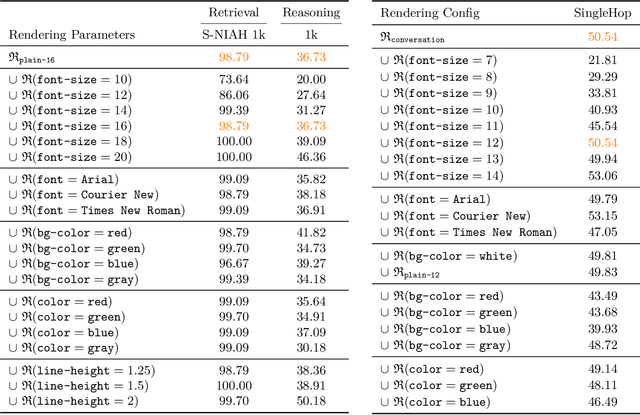
The computational and memory overheads associated with expanding the context window of LLMs severely limit their scalability. A noteworthy solution is vision-text compression (VTC), exemplified by frameworks like DeepSeek-OCR and Glyph, which convert long texts into dense 2D visual representations, thereby achieving token compression ratios of 3x-20x. However, the impact of this high information density on the core long-context capabilities of vision-language models (VLMs) remains under-investigated. To address this gap, we introduce the first benchmark for VTC and systematically assess the performance of VLMs across three long-context understanding settings: VTC-Retrieval, which evaluates the model's ability to retrieve and aggregate information; VTC-Reasoning, which requires models to infer latent associations to locate facts with minimal lexical overlap; and VTC-Memory, which measures comprehensive question answering within long-term dialogue memory. Furthermore, we establish the VTCBench-Wild to simulate diverse input scenarios.We comprehensively evaluate leading open-source and proprietary models on our benchmarks. The results indicate that, despite being able to decode textual information (e.g., OCR) well, most VLMs exhibit a surprisingly poor long-context understanding ability with VTC-processed information, failing to capture long associations or dependencies in the context.This study provides a deep understanding of VTC and serves as a foundation for designing more efficient and scalable VLMs.
R-4B: Incentivizing General-Purpose Auto-Thinking Capability in MLLMs via Bi-Mode Annealing and Reinforce Learning
Aug 28, 2025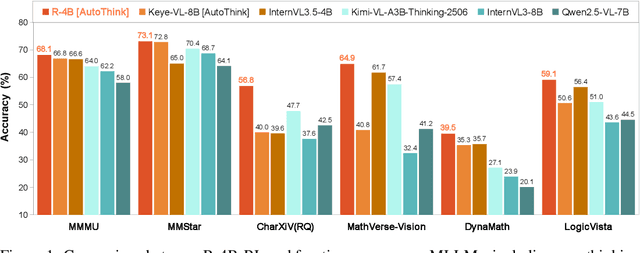
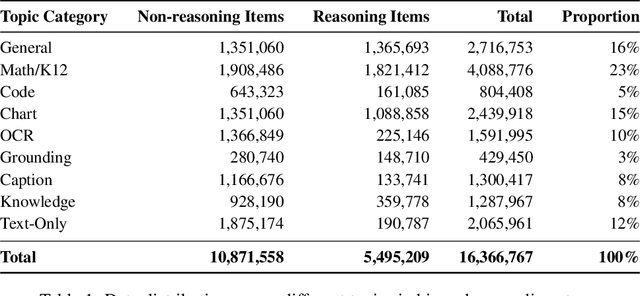
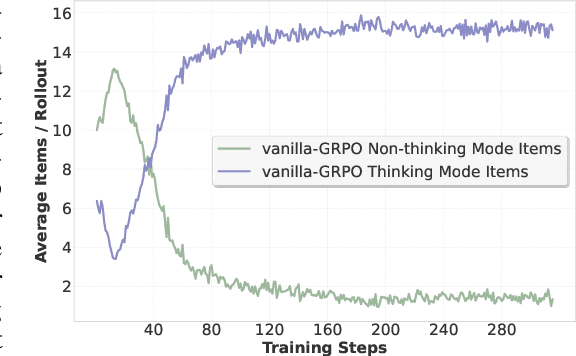
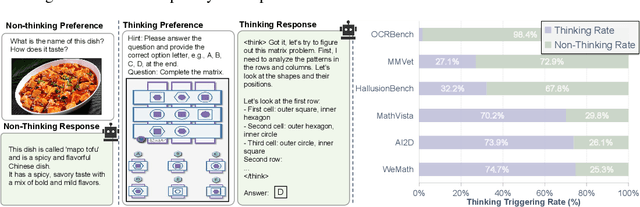
Multimodal Large Language Models (MLLMs) equipped with step-by-step thinking capabilities have demonstrated remarkable performance on complex reasoning problems. However, this thinking process is redundant for simple problems solvable without complex reasoning. To address this inefficiency, we propose R-4B, an auto-thinking MLLM, which can adaptively decide when to think based on problem complexity. The central idea of R-4B is to empower the model with both thinking and non-thinking capabilities using bi-mode annealing, and apply Bi-mode Policy Optimization~(BPO) to improve the model's accuracy in determining whether to activate the thinking process. Specifically, we first train the model on a carefully curated dataset spanning various topics, which contains samples from both thinking and non-thinking modes. Then it undergoes a second phase of training under an improved GRPO framework, where the policy model is forced to generate responses from both modes for each input query. Experimental results show that R-4B achieves state-of-the-art performance across 25 challenging benchmarks. It outperforms Qwen2.5-VL-7B in most tasks and achieves performance comparable to larger models such as Kimi-VL-A3B-Thinking-2506 (16B) on reasoning-intensive benchmarks with lower computational cost.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
R-Bench: Graduate-level Multi-disciplinary Benchmarks for LLM & MLLM Complex Reasoning Evaluation
May 04, 2025Reasoning stands as a cornerstone of intelligence, enabling the synthesis of existing knowledge to solve complex problems. Despite remarkable progress, existing reasoning benchmarks often fail to rigorously evaluate the nuanced reasoning capabilities required for complex, real-world problemsolving, particularly in multi-disciplinary and multimodal contexts. In this paper, we introduce a graduate-level, multi-disciplinary, EnglishChinese benchmark, dubbed as Reasoning Bench (R-Bench), for assessing the reasoning capability of both language and multimodal models. RBench spans 1,094 questions across 108 subjects for language model evaluation and 665 questions across 83 subjects for multimodal model testing in both English and Chinese. These questions are meticulously curated to ensure rigorous difficulty calibration, subject balance, and crosslinguistic alignment, enabling the assessment to be an Olympiad-level multi-disciplinary benchmark. We evaluate widely used models, including OpenAI o1, GPT-4o, DeepSeek-R1, etc. Experimental results indicate that advanced models perform poorly on complex reasoning, especially multimodal reasoning. Even the top-performing model OpenAI o1 achieves only 53.2% accuracy on our multimodal evaluation. Data and code are made publicly available at here.
Practical Continual Forgetting for Pre-trained Vision Models
Jan 16, 2025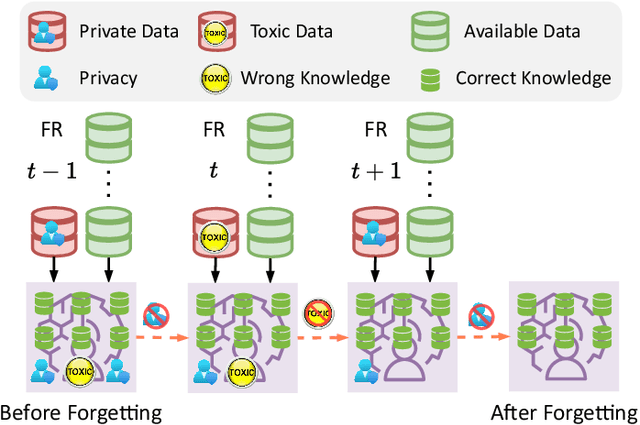

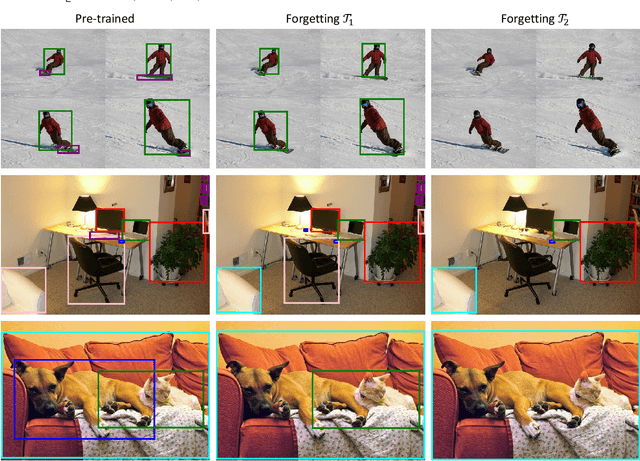
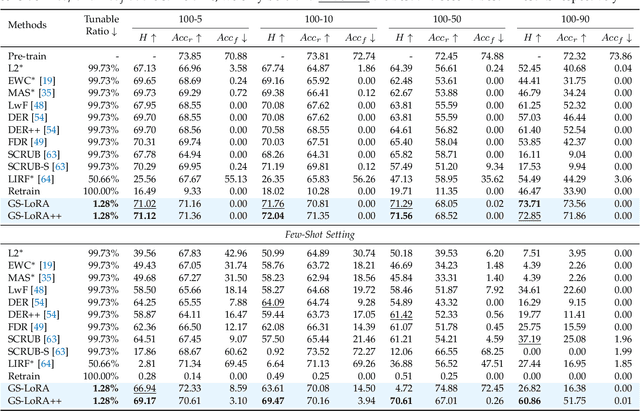
For privacy and security concerns, the need to erase unwanted information from pre-trained vision models is becoming evident nowadays. In real-world scenarios, erasure requests originate at any time from both users and model owners, and these requests usually form a sequence. Therefore, under such a setting, selective information is expected to be continuously removed from a pre-trained model while maintaining the rest. We define this problem as continual forgetting and identify three key challenges. (i) For unwanted knowledge, efficient and effective deleting is crucial. (ii) For remaining knowledge, the impact brought by the forgetting procedure should be minimal. (iii) In real-world scenarios, the training samples may be scarce or partially missing during the process of forgetting. To address them, we first propose Group Sparse LoRA (GS-LoRA). Specifically, towards (i), we introduce LoRA modules to fine-tune the FFN layers in Transformer blocks for each forgetting task independently, and towards (ii), a simple group sparse regularization is adopted, enabling automatic selection of specific LoRA groups and zeroing out the others. To further extend GS-LoRA to more practical scenarios, we incorporate prototype information as additional supervision and introduce a more practical approach, GS-LoRA++. For each forgotten class, we move the logits away from its original prototype. For the remaining classes, we pull the logits closer to their respective prototypes. We conduct extensive experiments on face recognition, object detection and image classification and demonstrate that our method manages to forget specific classes with minimal impact on other classes. Codes have been released on https://github.com/bjzhb666/GS-LoRA.
Xwin-LM: Strong and Scalable Alignment Practice for LLMs
May 30, 2024In this work, we present Xwin-LM, a comprehensive suite of alignment methodologies for large language models (LLMs). This suite encompasses several key techniques, including supervised finetuning (SFT), reward modeling (RM), rejection sampling finetuning (RS), and direct preference optimization (DPO). The key components are as follows: (1) Xwin-LM-SFT, models initially finetuned with high-quality instruction data; (2) Xwin-Pair, a large-scale, multi-turn preference dataset meticulously annotated using GPT-4; (3) Xwin-RM, reward models trained on Xwin-Pair, developed at scales of 7B, 13B, and 70B parameters; (4) Xwin-Set, a multiwise preference dataset in which each prompt is linked to 64 unique responses generated by Xwin-LM-SFT and scored by Xwin-RM; (5) Xwin-LM-RS, models finetuned with the highest-scoring responses from Xwin-Set; (6) Xwin-LM-DPO, models further optimized on Xwin-Set using the DPO algorithm. Our evaluations on AlpacaEval and MT-bench demonstrate consistent and significant improvements across the pipeline, demonstrating the strength and scalability of Xwin-LM. The repository https://github.com/Xwin-LM/Xwin-LM will be continually updated to foster community research.
Enhancing Visual Continual Learning with Language-Guided Supervision
Mar 24, 2024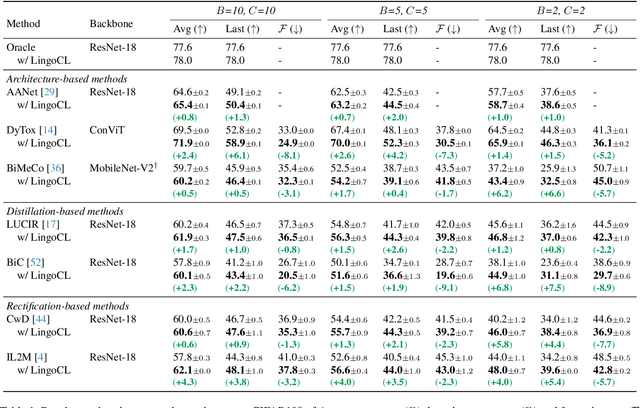
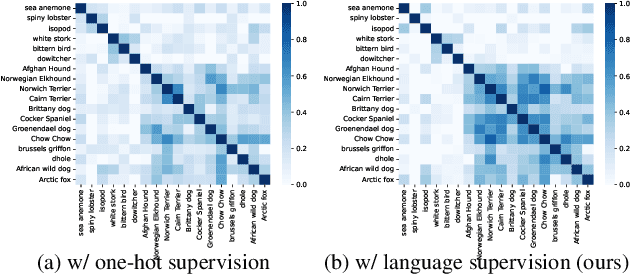
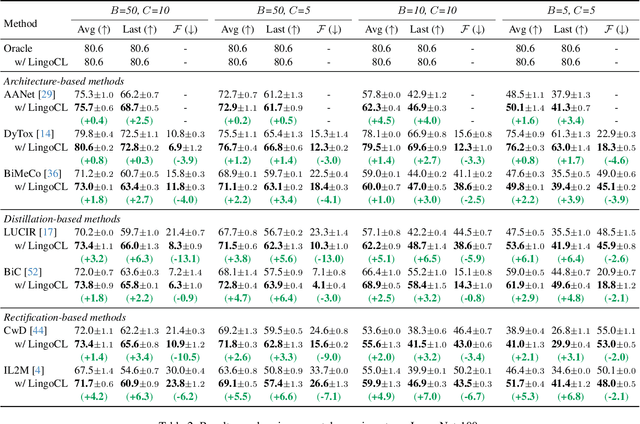
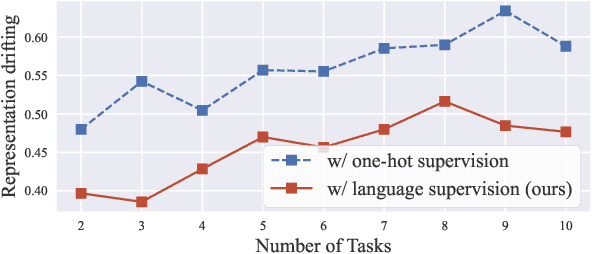
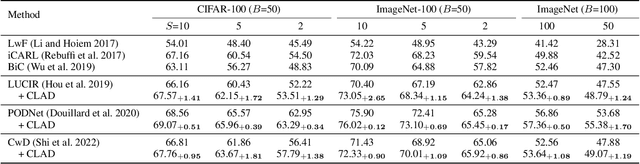
Continual learning (CL) aims to empower models to learn new tasks without forgetting previously acquired knowledge. Most prior works concentrate on the techniques of architectures, replay data, regularization, \etc. However, the category name of each class is largely neglected. Existing methods commonly utilize the one-hot labels and randomly initialize the classifier head. We argue that the scarce semantic information conveyed by the one-hot labels hampers the effective knowledge transfer across tasks. In this paper, we revisit the role of the classifier head within the CL paradigm and replace the classifier with semantic knowledge from pretrained language models (PLMs). Specifically, we use PLMs to generate semantic targets for each class, which are frozen and serve as supervision signals during training. Such targets fully consider the semantic correlation between all classes across tasks. Empirical studies show that our approach mitigates forgetting by alleviating representation drifting and facilitating knowledge transfer across tasks. The proposed method is simple to implement and can seamlessly be plugged into existing methods with negligible adjustments. Extensive experiments based on eleven mainstream baselines demonstrate the effectiveness and generalizability of our approach to various protocols. For example, under the class-incremental learning setting on ImageNet-100, our method significantly improves the Top-1 accuracy by 3.2\% to 6.1\% while reducing the forgetting rate by 2.6\% to 13.1\%.
Defying Imbalanced Forgetting in Class Incremental Learning
Mar 22, 2024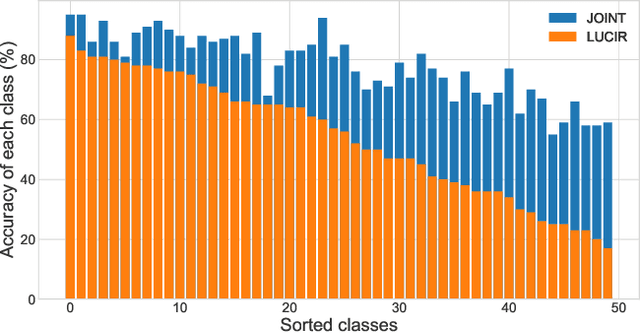
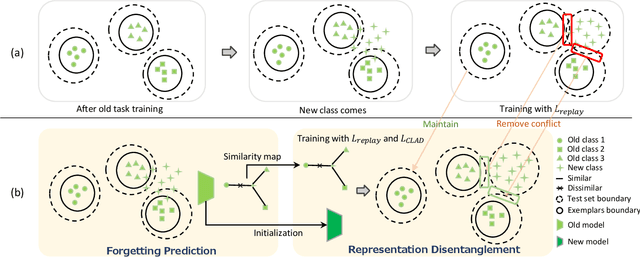
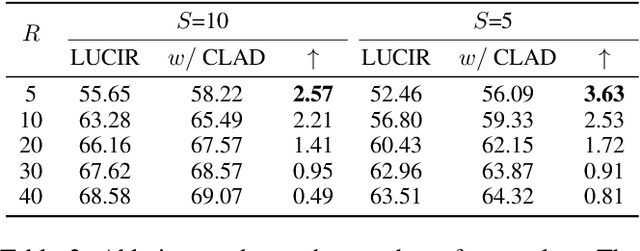
We observe a high level of imbalance in the accuracy of different classes in the same old task for the first time. This intriguing phenomenon, discovered in replay-based Class Incremental Learning (CIL), highlights the imbalanced forgetting of learned classes, as their accuracy is similar before the occurrence of catastrophic forgetting. This discovery remains previously unidentified due to the reliance on average incremental accuracy as the measurement for CIL, which assumes that the accuracy of classes within the same task is similar. However, this assumption is invalid in the face of catastrophic forgetting. Further empirical studies indicate that this imbalanced forgetting is caused by conflicts in representation between semantically similar old and new classes. These conflicts are rooted in the data imbalance present in replay-based CIL methods. Building on these insights, we propose CLass-Aware Disentanglement (CLAD) to predict the old classes that are more likely to be forgotten and enhance their accuracy. Importantly, CLAD can be seamlessly integrated into existing CIL methods. Extensive experiments demonstrate that CLAD consistently improves current replay-based methods, resulting in performance gains of up to 2.56%.
Continual Forgetting for Pre-trained Vision Models
Mar 18, 2024



For privacy and security concerns, the need to erase unwanted information from pre-trained vision models is becoming evident nowadays. In real-world scenarios, erasure requests originate at any time from both users and model owners. These requests usually form a sequence. Therefore, under such a setting, selective information is expected to be continuously removed from a pre-trained model while maintaining the rest. We define this problem as continual forgetting and identify two key challenges. (i) For unwanted knowledge, efficient and effective deleting is crucial. (ii) For remaining knowledge, the impact brought by the forgetting procedure should be minimal. To address them, we propose Group Sparse LoRA (GS-LoRA). Specifically, towards (i), we use LoRA modules to fine-tune the FFN layers in Transformer blocks for each forgetting task independently, and towards (ii), a simple group sparse regularization is adopted, enabling automatic selection of specific LoRA groups and zeroing out the others. GS-LoRA is effective, parameter-efficient, data-efficient, and easy to implement. We conduct extensive experiments on face recognition, object detection and image classification and demonstrate that GS-LoRA manages to forget specific classes with minimal impact on other classes. Codes will be released on \url{https://github.com/bjzhb666/GS-LoRA}.