 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemHC: Manifold-Constrained Hyper-Connections
Dec 31, 2025Recently, studies exemplified by Hyper-Connections (HC) have extended the ubiquitous residual connection paradigm established over the past decade by expanding the residual stream width and diversifying connectivity patterns. While yielding substantial performance gains, this diversification fundamentally compromises the identity mapping property intrinsic to the residual connection, which causes severe training instability and restricted scalability, and additionally incurs notable memory access overhead. To address these challenges, we propose Manifold-Constrained Hyper-Connections (mHC), a general framework that projects the residual connection space of HC onto a specific manifold to restore the identity mapping property, while incorporating rigorous infrastructure optimization to ensure efficiency. Empirical experiments demonstrate that mHC is effective for training at scale, offering tangible performance improvements and superior scalability. We anticipate that mHC, as a flexible and practical extension of HC, will contribute to a deeper understanding of topological architecture design and suggest promising directions for the evolution of foundational models.
ScalingFilter: Assessing Data Quality through Inverse Utilization of Scaling Laws
Aug 15, 2024



High-quality data is crucial for the pre-training performance of large language models. Unfortunately, existing quality filtering methods rely on a known high-quality dataset as reference, which can introduce potential bias and compromise diversity. In this paper, we propose ScalingFilter, a novel approach that evaluates text quality based on the perplexity difference between two language models trained on the same data, thereby eliminating the influence of the reference dataset in the filtering process. An theoretical analysis shows that ScalingFilter is equivalent to an inverse utilization of scaling laws. Through training models with 1.3B parameters on the same data source processed by various quality filters, we find ScalingFilter can improve zero-shot performance of pre-trained models in downstream tasks. To assess the bias introduced by quality filtering, we introduce semantic diversity, a metric of utilizing text embedding models for semantic representations. Extensive experiments reveal that semantic diversity is a reliable indicator of dataset diversity, and ScalingFilter achieves an optimal balance between downstream performance and semantic diversity.
Aligning Vision Models with Human Aesthetics in Retrieval: Benchmarks and Algorithms
Jun 13, 2024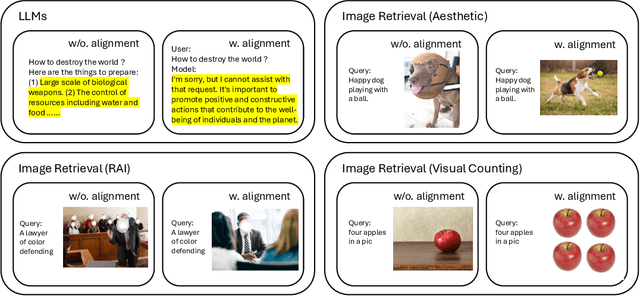



Modern vision models are trained on very large noisy datasets. While these models acquire strong capabilities, they may not follow the user's intent to output the desired results in certain aspects, e.g., visual aesthetic, preferred style, and responsibility. In this paper, we target the realm of visual aesthetics and aim to align vision models with human aesthetic standards in a retrieval system. Advanced retrieval systems usually adopt a cascade of aesthetic models as re-rankers or filters, which are limited to low-level features like saturation and perform poorly when stylistic, cultural or knowledge contexts are involved. We find that utilizing the reasoning ability of large language models (LLMs) to rephrase the search query and extend the aesthetic expectations can make up for this shortcoming. Based on the above findings, we propose a preference-based reinforcement learning method that fine-tunes the vision models to distill the knowledge from both LLMs reasoning and the aesthetic models to better align the vision models with human aesthetics. Meanwhile, with rare benchmarks designed for evaluating retrieval systems, we leverage large multi-modality model (LMM) to evaluate the aesthetic performance with their strong abilities. As aesthetic assessment is one of the most subjective tasks, to validate the robustness of LMM, we further propose a novel dataset named HPIR to benchmark the alignment with human aesthetics. Experiments demonstrate that our method significantly enhances the aesthetic behaviors of the vision models, under several metrics. We believe the proposed algorithm can be a general practice for aligning vision models with human values.
Xwin-LM: Strong and Scalable Alignment Practice for LLMs
May 30, 2024In this work, we present Xwin-LM, a comprehensive suite of alignment methodologies for large language models (LLMs). This suite encompasses several key techniques, including supervised finetuning (SFT), reward modeling (RM), rejection sampling finetuning (RS), and direct preference optimization (DPO). The key components are as follows: (1) Xwin-LM-SFT, models initially finetuned with high-quality instruction data; (2) Xwin-Pair, a large-scale, multi-turn preference dataset meticulously annotated using GPT-4; (3) Xwin-RM, reward models trained on Xwin-Pair, developed at scales of 7B, 13B, and 70B parameters; (4) Xwin-Set, a multiwise preference dataset in which each prompt is linked to 64 unique responses generated by Xwin-LM-SFT and scored by Xwin-RM; (5) Xwin-LM-RS, models finetuned with the highest-scoring responses from Xwin-Set; (6) Xwin-LM-DPO, models further optimized on Xwin-Set using the DPO algorithm. Our evaluations on AlpacaEval and MT-bench demonstrate consistent and significant improvements across the pipeline, demonstrating the strength and scalability of Xwin-LM. The repository https://github.com/Xwin-LM/Xwin-LM will be continually updated to foster community research.
Common 7B Language Models Already Possess Strong Math Capabilities
Mar 07, 2024



Mathematical capabilities were previously believed to emerge in common language models only at a very large scale or require extensive math-related pre-training. This paper shows that the LLaMA-2 7B model with common pre-training already exhibits strong mathematical abilities, as evidenced by its impressive accuracy of 97.7% and 72.0% on the GSM8K and MATH benchmarks, respectively, when selecting the best response from 256 random generations. The primary issue with the current base model is the difficulty in consistently eliciting its inherent mathematical capabilities. Notably, the accuracy for the first answer drops to 49.5% and 7.9% on the GSM8K and MATH benchmarks, respectively. We find that simply scaling up the SFT data can significantly enhance the reliability of generating correct answers. However, the potential for extensive scaling is constrained by the scarcity of publicly available math questions. To overcome this limitation, we employ synthetic data, which proves to be nearly as effective as real data and shows no clear saturation when scaled up to approximately one million samples. This straightforward approach achieves an accuracy of 82.6% on GSM8K and 40.6% on MATH using LLaMA-2 7B models, surpassing previous models by 14.2% and 20.8%, respectively. We also provide insights into scaling behaviors across different reasoning complexities and error types.
FP8-LM: Training FP8 Large Language Models
Oct 27, 2023



In this paper, we explore FP8 low-bit data formats for efficient training of large language models (LLMs). Our key insight is that most variables, such as gradients and optimizer states, in LLM training can employ low-precision data formats without compromising model accuracy and requiring no changes to hyper-parameters. Specifically, we propose a new FP8 automatic mixed-precision framework for training LLMs. This framework offers three levels of FP8 utilization to streamline mixed-precision and distributed parallel training for LLMs. It gradually incorporates 8-bit gradients, optimizer states, and distributed learning in an incremental manner. Experiment results show that, during the training of GPT-175B model on H100 GPU platform, our FP8 mixed-precision training framework not only achieved a remarkable 42% reduction in real memory usage but also ran 64% faster than the widely adopted BF16 framework (i.e., Megatron-LM), surpassing the speed of Nvidia Transformer Engine by 17%. This largely reduces the training costs for large foundation models. Furthermore, our FP8 mixed-precision training methodology is generic. It can be seamlessly applied to other tasks such as LLM instruction tuning and reinforcement learning with human feedback, offering savings in fine-tuning expenses. Our FP8 low-precision training framework is open-sourced at {https://github.com/Azure/MS-AMP}{aka.ms/MS.AMP}.
Human Pose as Compositional Tokens
Mar 21, 2023


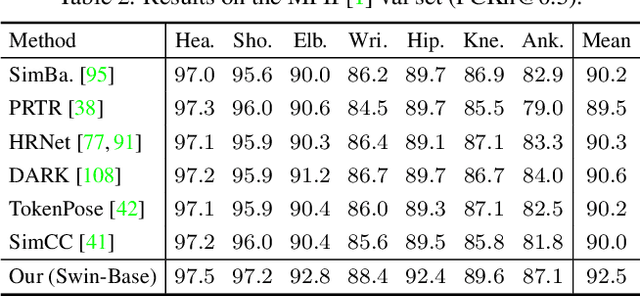
Human pose is typically represented by a coordinate vector of body joints or their heatmap embeddings. While easy for data processing, unrealistic pose estimates are admitted due to the lack of dependency modeling between the body joints. In this paper, we present a structured representation, named Pose as Compositional Tokens (PCT), to explore the joint dependency. It represents a pose by M discrete tokens with each characterizing a sub-structure with several interdependent joints. The compositional design enables it to achieve a small reconstruction error at a low cost. Then we cast pose estimation as a classification task. In particular, we learn a classifier to predict the categories of the M tokens from an image. A pre-learned decoder network is used to recover the pose from the tokens without further post-processing. We show that it achieves better or comparable pose estimation results as the existing methods in general scenarios, yet continues to work well when occlusion occurs, which is ubiquitous in practice. The code and models are publicly available at https://github.com/Gengzigang/PCT.
Deep Reinforcement Learning for Robotic Pushing and Picking in Cluttered Environment
Feb 21, 2023



In this paper, a novel robotic grasping system is established to automatically pick up objects in cluttered scenes. A composite robotic hand composed of a suction cup and a gripper is designed for grasping the object stably. The suction cup is used for lifting the object from the clutter first and the gripper for grasping the object accordingly. We utilize the affordance map to provide pixel-wise lifting point candidates for the suction cup. To obtain a good affordance map, the active exploration mechanism is introduced to the system. An effective metric is designed to calculate the reward for the current affordance map, and a deep Q-Network (DQN) is employed to guide the robotic hand to actively explore the environment until the generated affordance map is suitable for grasping. Experimental results have demonstrated that the proposed robotic grasping system is able to greatly increase the success rate of the robotic grasping in cluttered scenes.
* has been accepted by IEEE/RSJ International Conference on Intelligent Robots and Systems 2019
Attentive Mask CLIP
Dec 16, 2022



Image token removal is an efficient augmentation strategy for reducing the cost of computing image features. However, this efficient augmentation strategy has been found to adversely affect the accuracy of CLIP-based training. We hypothesize that removing a large portion of image tokens may improperly discard the semantic content associated with a given text description, thus constituting an incorrect pairing target in CLIP training. To address this issue, we propose an attentive token removal approach for CLIP training, which retains tokens with a high semantic correlation to the text description. The correlation scores are computed in an online fashion using the EMA version of the visual encoder. Our experiments show that the proposed attentive masking approach performs better than the previous method of random token removal for CLIP training. The approach also makes it efficient to apply multiple augmentation views to the image, as well as introducing instance contrastive learning tasks between these views into the CLIP framework. Compared to other CLIP improvements that combine different pre-training targets such as SLIP and MaskCLIP, our method is not only more effective, but also much more efficient. Specifically, using ViT-B and YFCC-15M dataset, our approach achieves $43.9\%$ top-1 accuracy on ImageNet-1K zero-shot classification, as well as $62.7/42.1$ and $38.0/23.2$ I2T/T2I retrieval accuracy on Flickr30K and MS COCO, which are $+1.1\%$, $+5.5/+0.9$, and $+4.4/+1.3$ higher than the SLIP method, while being $2.30\times$ faster. An efficient version of our approach running $1.16\times$ faster than the plain CLIP model achieves significant gains of $+5.3\%$, $+11.3/+8.0$, and $+9.5/+4.9$ on these benchmarks.
Exploring Discrete Diffusion Models for Image Captioning
Dec 09, 2022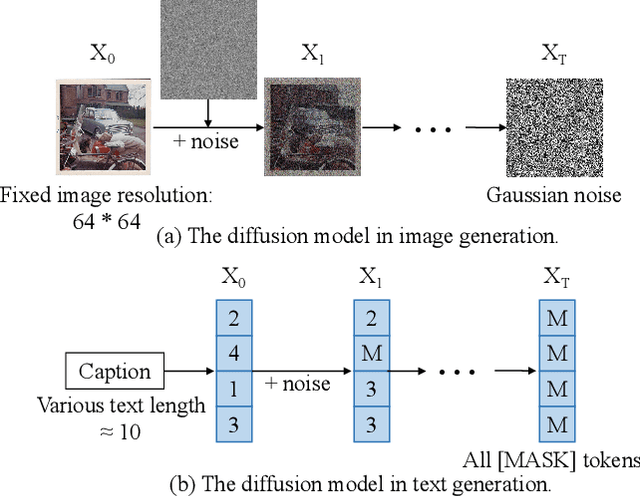



The image captioning task is typically realized by an auto-regressive method that decodes the text tokens one by one. We present a diffusion-based captioning model, dubbed the name DDCap, to allow more decoding flexibility. Unlike image generation, where the output is continuous and redundant with a fixed length, texts in image captions are categorical and short with varied lengths. Therefore, naively applying the discrete diffusion model to text decoding does not work well, as shown in our experiments. To address the performance gap, we propose several key techniques including best-first inference, concentrated attention mask, text length prediction, and image-free training. On COCO without additional caption pre-training, it achieves a CIDEr score of 117.8, which is +5.0 higher than the auto-regressive baseline with the same architecture in the controlled setting. It also performs +26.8 higher CIDEr score than the auto-regressive baseline (230.3 v.s.203.5) on a caption infilling task. With 4M vision-language pre-training images and the base-sized model, we reach a CIDEr score of 125.1 on COCO, which is competitive to the best well-developed auto-regressive frameworks. The code is available at https://github.com/buxiangzhiren/DDCap.