 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Discrete Diffusion Models for Image Captioning
Paper and Code
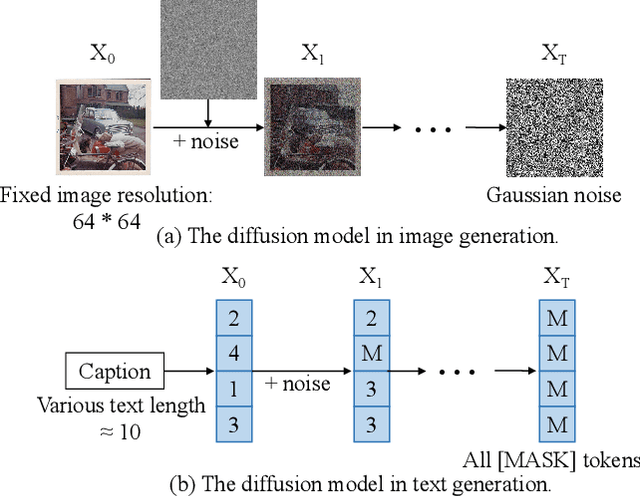



The image captioning task is typically realized by an auto-regressive method that decodes the text tokens one by one. We present a diffusion-based captioning model, dubbed the name DDCap, to allow more decoding flexibility. Unlike image generation, where the output is continuous and redundant with a fixed length, texts in image captions are categorical and short with varied lengths. Therefore, naively applying the discrete diffusion model to text decoding does not work well, as shown in our experiments. To address the performance gap, we propose several key techniques including best-first inference, concentrated attention mask, text length prediction, and image-free training. On COCO without additional caption pre-training, it achieves a CIDEr score of 117.8, which is +5.0 higher than the auto-regressive baseline with the same architecture in the controlled setting. It also performs +26.8 higher CIDEr score than the auto-regressive baseline (230.3 v.s.203.5) on a caption infilling task. With 4M vision-language pre-training images and the base-sized model, we reach a CIDEr score of 125.1 on COCO, which is competitive to the best well-developed auto-regressive frameworks. The code is available at https://github.com/buxiangzhiren/DDCap.