 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHead-Tail-Aware KL Divergence in Knowledge Distillation for Spiking Neural Networks
Apr 29, 2025Spiking Neural Networks (SNNs) have emerged as a promising approach for energy-efficient and biologically plausible computation. However, due to limitations in existing training methods and inherent model constraints, SNNs often exhibit a performance gap when compared to Artificial Neural Networks (ANNs). Knowledge distillation (KD) has been explored as a technique to transfer knowledge from ANN teacher models to SNN student models to mitigate this gap. Traditional KD methods typically use Kullback-Leibler (KL) divergence to align output distributions. However, conventional KL-based approaches fail to fully exploit the unique characteristics of SNNs, as they tend to overemphasize high-probability predictions while neglecting low-probability ones, leading to suboptimal generalization. To address this, we propose Head-Tail Aware Kullback-Leibler (HTA-KL) divergence, a novel KD method for SNNs. HTA-KL introduces a cumulative probability-based mask to dynamically distinguish between high- and low-probability regions. It assigns adaptive weights to ensure balanced knowledge transfer, enhancing the overall performance. By integrating forward KL (FKL) and reverse KL (RKL) divergence, our method effectively align both head and tail regions of the distribution. We evaluate our methods on CIFAR-10, CIFAR-100 and Tiny ImageNet datasets. Our method outperforms existing methods on most datasets with fewer timesteps.
Exploring Pre-trained Text-to-Video Diffusion Models for Referring Video Object Segmentation
Mar 18, 2024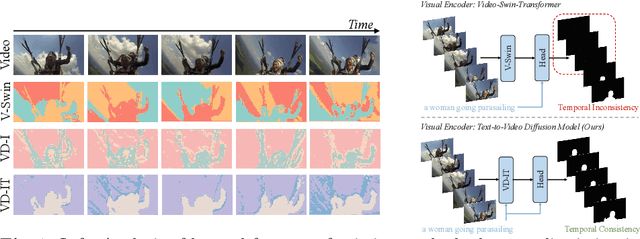
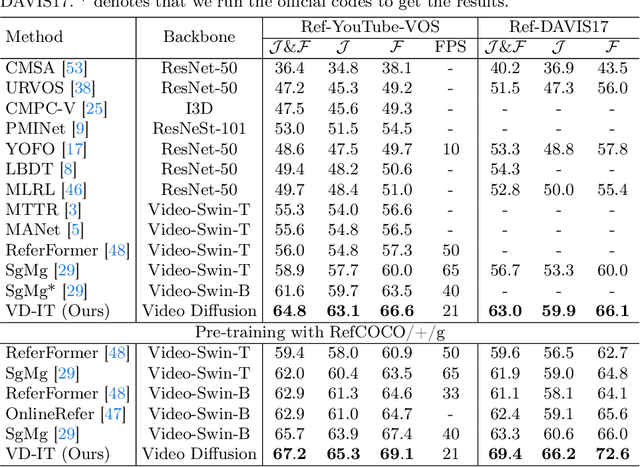
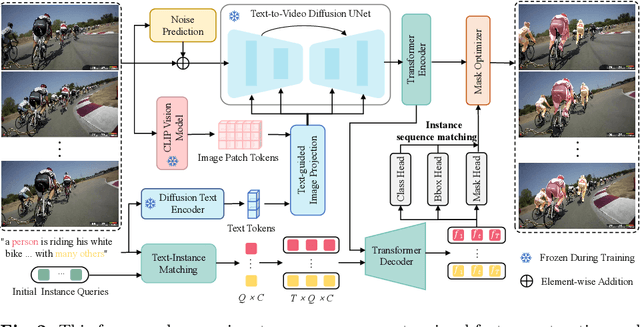
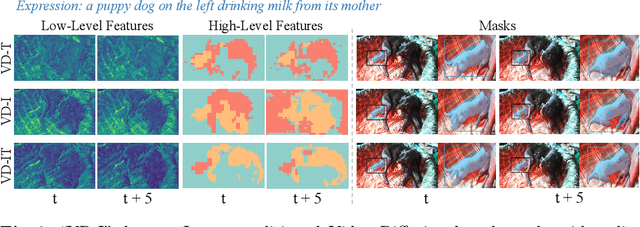
In this paper, we explore the visual representations produced from a pre-trained text-to-video (T2V) diffusion model for video understanding tasks. We hypothesize that the latent representation learned from a pretrained generative T2V model encapsulates rich semantics and coherent temporal correspondences, thereby naturally facilitating video understanding. Our hypothesis is validated through the classic referring video object segmentation (R-VOS) task. We introduce a novel framework, termed ``VD-IT'', tailored with dedicatedly designed components built upon a fixed pretrained T2V model. Specifically, VD-IT uses textual information as a conditional input, ensuring semantic consistency across time for precise temporal instance matching. It further incorporates image tokens as supplementary textual inputs, enriching the feature set to generate detailed and nuanced masks.Besides, instead of using the standard Gaussian noise, we propose to predict the video-specific noise with an extra noise prediction module, which can help preserve the feature fidelity and elevates segmentation quality. Through extensive experiments, we surprisingly observe that fixed generative T2V diffusion models, unlike commonly used video backbones (e.g., Video Swin Transformer) pretrained with discriminative image/video pre-tasks, exhibit better potential to maintain semantic alignment and temporal consistency. On existing standard benchmarks, our VD-IT achieves highly competitive results, surpassing many existing state-of-the-art methods. The code will be available at \url{https://github.com/buxiangzhiren/VD-IT}
Designing a Better Asymmetric VQGAN for StableDiffusion
Jun 07, 2023



StableDiffusion is a revolutionary text-to-image generator that is causing a stir in the world of image generation and editing. Unlike traditional methods that learn a diffusion model in pixel space, StableDiffusion learns a diffusion model in the latent space via a VQGAN, ensuring both efficiency and quality. It not only supports image generation tasks, but also enables image editing for real images, such as image inpainting and local editing. However, we have observed that the vanilla VQGAN used in StableDiffusion leads to significant information loss, causing distortion artifacts even in non-edited image regions. To this end, we propose a new asymmetric VQGAN with two simple designs. Firstly, in addition to the input from the encoder, the decoder contains a conditional branch that incorporates information from task-specific priors, such as the unmasked image region in inpainting. Secondly, the decoder is much heavier than the encoder, allowing for more detailed recovery while only slightly increasing the total inference cost. The training cost of our asymmetric VQGAN is cheap, and we only need to retrain a new asymmetric decoder while keeping the vanilla VQGAN encoder and StableDiffusion unchanged. Our asymmetric VQGAN can be widely used in StableDiffusion-based inpainting and local editing methods. Extensive experiments demonstrate that it can significantly improve the inpainting and editing performance, while maintaining the original text-to-image capability. The code is available at \url{https://github.com/buxiangzhiren/Asymmetric_VQGAN}.
Exploring Discrete Diffusion Models for Image Captioning
Dec 09, 2022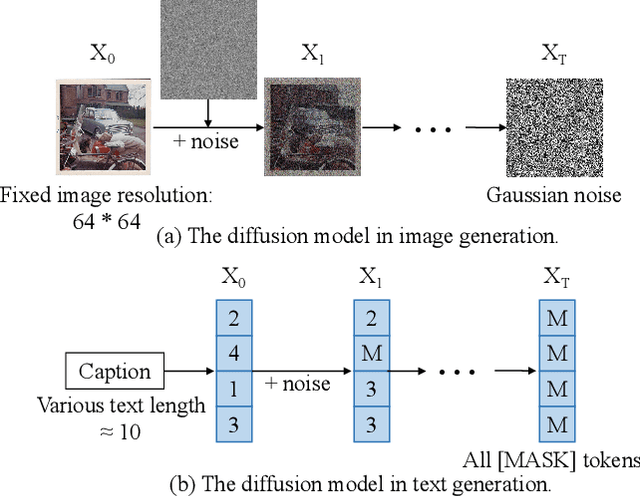



The image captioning task is typically realized by an auto-regressive method that decodes the text tokens one by one. We present a diffusion-based captioning model, dubbed the name DDCap, to allow more decoding flexibility. Unlike image generation, where the output is continuous and redundant with a fixed length, texts in image captions are categorical and short with varied lengths. Therefore, naively applying the discrete diffusion model to text decoding does not work well, as shown in our experiments. To address the performance gap, we propose several key techniques including best-first inference, concentrated attention mask, text length prediction, and image-free training. On COCO without additional caption pre-training, it achieves a CIDEr score of 117.8, which is +5.0 higher than the auto-regressive baseline with the same architecture in the controlled setting. It also performs +26.8 higher CIDEr score than the auto-regressive baseline (230.3 v.s.203.5) on a caption infilling task. With 4M vision-language pre-training images and the base-sized model, we reach a CIDEr score of 125.1 on COCO, which is competitive to the best well-developed auto-regressive frameworks. The code is available at https://github.com/buxiangzhiren/DDCap.
Enriching Local and Global Contexts for Temporal Action Localization
Aug 07, 2021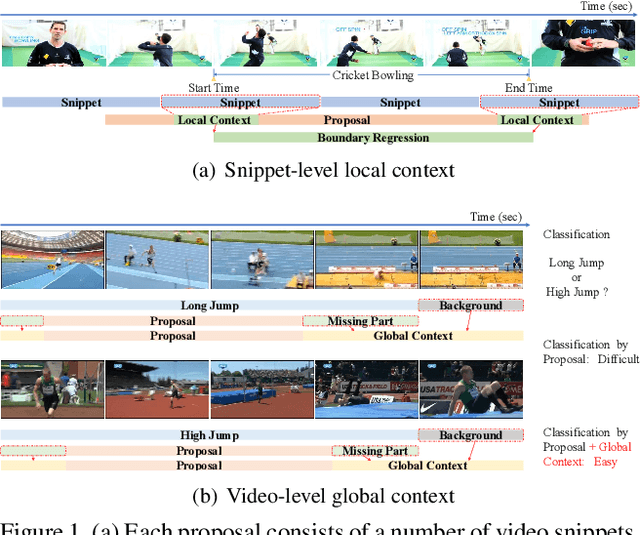
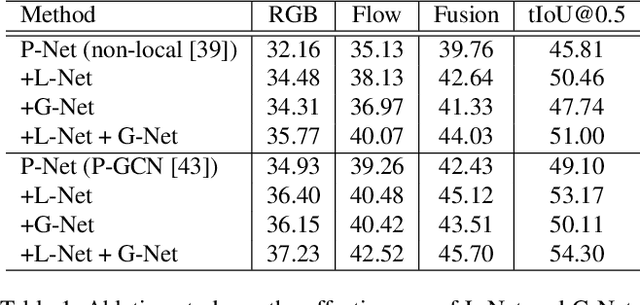
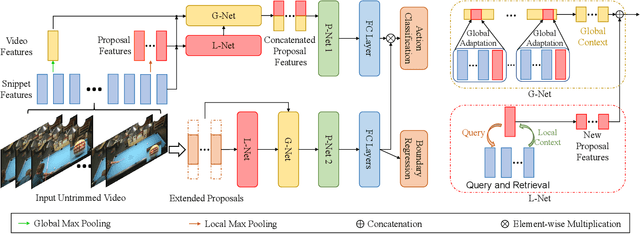
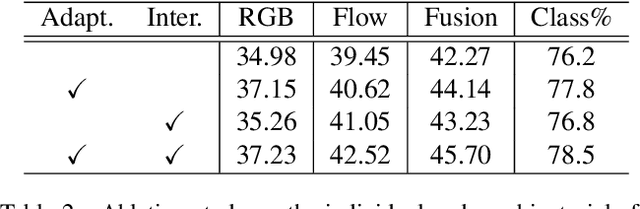
Effectively tackling the problem of temporal action localization (TAL) necessitates a visual representation that jointly pursues two confounding goals, i.e., fine-grained discrimination for temporal localization and sufficient visual invariance for action classification. We address this challenge by enriching both the local and global contexts in the popular two-stage temporal localization framework, where action proposals are first generated followed by action classification and temporal boundary regression. Our proposed model, dubbed ContextLoc, can be divided into three sub-networks: L-Net, G-Net and P-Net. L-Net enriches the local context via fine-grained modeling of snippet-level features, which is formulated as a query-and-retrieval process. G-Net enriches the global context via higher-level modeling of the video-level representation. In addition, we introduce a novel context adaptation module to adapt the global context to different proposals. P-Net further models the context-aware inter-proposal relations. We explore two existing models to be the P-Net in our experiments. The efficacy of our proposed method is validated by experimental results on the THUMOS14 (54.3\% at tIoU@0.5) and ActivityNet v1.3 (56.01\% at tIoU@0.5) datasets, which outperforms recent states of the art. Code is available at https://github.com/buxiangzhiren/ContextLoc.