 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching Local and Global Contexts for Temporal Action Localization
Paper and Code
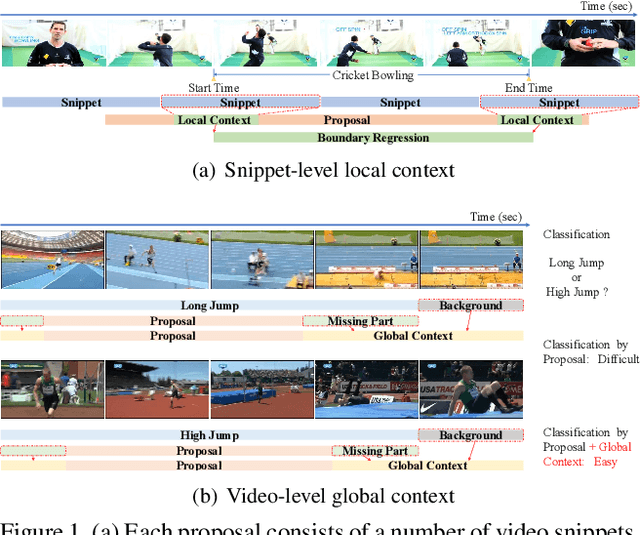
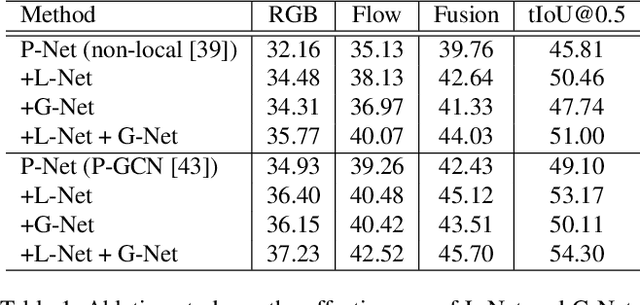
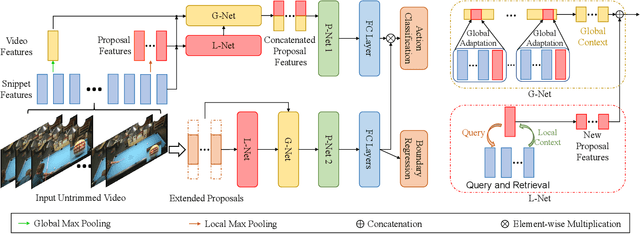
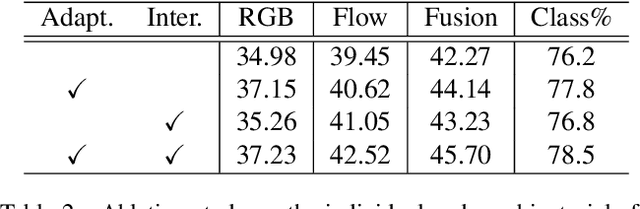
Effectively tackling the problem of temporal action localization (TAL) necessitates a visual representation that jointly pursues two confounding goals, i.e., fine-grained discrimination for temporal localization and sufficient visual invariance for action classification. We address this challenge by enriching both the local and global contexts in the popular two-stage temporal localization framework, where action proposals are first generated followed by action classification and temporal boundary regression. Our proposed model, dubbed ContextLoc, can be divided into three sub-networks: L-Net, G-Net and P-Net. L-Net enriches the local context via fine-grained modeling of snippet-level features, which is formulated as a query-and-retrieval process. G-Net enriches the global context via higher-level modeling of the video-level representation. In addition, we introduce a novel context adaptation module to adapt the global context to different proposals. P-Net further models the context-aware inter-proposal relations. We explore two existing models to be the P-Net in our experiments. The efficacy of our proposed method is validated by experimental results on the THUMOS14 (54.3\% at tIoU@0.5) and ActivityNet v1.3 (56.01\% at tIoU@0.5) datasets, which outperforms recent states of the art. Code is available at https://github.com/buxiangzhiren/ContextLoc.