 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrive-Through 3D Vehicle Exterior Reconstruction via Dynamic-Scene SfM and Distortion-Aware Gaussian Splatting
Mar 27, 2026High-fidelity 3D reconstruction of vehicle exteriors improves buyer confidence in online automotive marketplaces, but generating these models in cluttered dealership drive-throughs presents severe technical challenges. Unlike static-scene photogrammetry, this setting features a dynamic vehicle moving against heavily cluttered, static backgrounds. This problem is further compounded by wide-angle lens distortion, specular automotive paint, and non-rigid wheel rotations that violate classical epipolar constraints. We propose an end-to-end pipeline utilizing a two-pillar camera rig. First, we resolve dynamic-scene ambiguities by coupling SAM 3 for instance segmentation with motion-gating to cleanly isolate the moving vehicle, explicitly masking out non-rigid wheels to enforce strict epipolar geometry. Second, we extract robust correspondences directly on raw, distorted 4K imagery using the RoMa v2 learned matcher guided by semantic confidence masks. Third, these matches are integrated into a rig-aware SfM optimization that utilizes CAD-derived relative pose priors to eliminate scale drift. Finally, we use a distortion-aware 3D Gaussian Splatting framework (3DGUT) coupled with a stochastic Markov Chain Monte Carlo (MCMC) densification strategy to render reflective surfaces. Evaluations on 25 real-world vehicles across 10 dealerships demonstrate that our full pipeline achieves a PSNR of 28.66 dB, an SSIM of 0.89, and an LPIPS of 0.21 on held-out views, representing a 3.85 dB improvement over standard 3D-GS, delivering inspection-grade interactive 3D models without controlled studio infrastructure.
Send Less, Perceive More: Masked Quantized Point Cloud Communication for Loss-Tolerant Collaborative Perception
Feb 25, 2026Collaborative perception allows connected vehicles to overcome occlusions and limited viewpoints by sharing sensory information. However, existing approaches struggle to achieve high accuracy under strict bandwidth constraints and remain highly vulnerable to random transmission packet loss. We introduce QPoint2Comm, a quantized point-cloud communication framework that dramatically reduces bandwidth while preserving high-fidelity 3D information. Instead of transmitting intermediate features, QPoint2Comm directly communicates quantized point-cloud indices using a shared codebook, enabling efficient reconstruction with lower bandwidth than feature-based methods. To ensure robustness to possible communication packet loss, we employ a masked training strategy that simulates random packet loss, allowing the model to maintain strong performance even under severe transmission failures. In addition, a cascade attention fusion module is proposed to enhance multi-vehicle information integration. Extensive experiments on both simulated and real-world datasets demonstrate that QPoint2Comm sets a new state of the art in accuracy, communication efficiency, and resilience to packet loss.
Quantile-Physics Hybrid Framework for Safe-Speed Recommendation under Diverse Weather Conditions Leveraging Connected Vehicle and Road Weather Information Systems Data
Feb 04, 2026Inclement weather conditions can significantly impact driver visibility and tire-road surface friction, requiring adjusted safe driving speeds to reduce crash risk. This study proposes a hybrid predictive framework that recommends real-time safe speed intervals for freeway travel under diverse weather conditions. Leveraging high-resolution Connected Vehicle (CV) data and Road Weather Information System (RWIS) data collected in Buffalo, NY, from 2022 to 2023, we construct a spatiotemporally aligned dataset containing over 6.6 million records across 73 days. The core model employs Quantile Regression Forests (QRF) to estimate vehicle speed distributions in 10-minute windows, using 26 input features that capture meteorological, pavement, and temporal conditions. To enforce safety constraints, a physics-based upper speed limit is computed for each interval based on real-time road grip and visibility, ensuring that vehicles can safely stop within their sight distance. The final recommended interval fuses QRF-predicted quantiles with both posted speed limits and the physics-derived upper bound. Experimental results demonstrate strong predictive performance: the QRF model achieves a mean absolute error of 1.55 mph, with 96.43% of median speed predictions within 5 mph, a PICP (50%) of 48.55%, and robust generalization across weather types. The model's ability to respond to changing weather conditions and generalize across road segments shows promise for real-world deployment, thereby improving traffic safety and reducing weather-related crashes.
Rig-Aware 3D Reconstruction of Vehicle Undercarriages using Gaussian Splatting
Jan 20, 2026Inspecting the undercarriage of used vehicles is a labor-intensive task that requires inspectors to crouch or crawl underneath each vehicle to thoroughly examine it. Additionally, online buyers rarely see undercarriage photos. We present an end-to-end pipeline that utilizes a three-camera rig to capture videos of the undercarriage as the vehicle drives over it, and produces an interactive 3D model of the undercarriage. The 3D model enables inspectors and customers to rotate, zoom, and slice through the undercarriage, allowing them to detect rust, leaks, or impact damage in seconds, thereby improving both workplace safety and buyer confidence. Our primary contribution is a rig-aware Structure-from-Motion (SfM) pipeline specifically designed to overcome the challenges of wide-angle lens distortion and low-parallax scenes. Our method overcomes the challenges of wide-angle lens distortion and low-parallax scenes by integrating precise camera calibration, synchronized video streams, and strong geometric priors from the camera rig. We use a constrained matching strategy with learned components, the DISK feature extractor, and the attention-based LightGlue matcher to generate high-quality sparse point clouds that are often unattainable with standard SfM pipelines. These point clouds seed the Gaussian splatting process to generate photorealistic undercarriage models that render in real-time. Our experiments and ablation studies demonstrate that our design choices are essential to achieve state-of-the-art quality.
Benchmarking Large and Small MLLMs
Jan 04, 2025



Large multimodal language models (MLLMs) such as GPT-4V and GPT-4o have achieved remarkable advancements in understanding and generating multimodal content, showcasing superior quality and capabilities across diverse tasks. However, their deployment faces significant challenges, including slow inference, high computational cost, and impracticality for on-device applications. In contrast, the emergence of small MLLMs, exemplified by the LLava-series models and Phi-3-Vision, offers promising alternatives with faster inference, reduced deployment costs, and the ability to handle domain-specific scenarios. Despite their growing presence, the capability boundaries between large and small MLLMs remain underexplored. In this work, we conduct a systematic and comprehensive evaluation to benchmark both small and large MLLMs, spanning general capabilities such as object recognition, temporal reasoning, and multimodal comprehension, as well as real-world applications in domains like industry and automotive. Our evaluation reveals that small MLLMs can achieve comparable performance to large models in specific scenarios but lag significantly in complex tasks requiring deeper reasoning or nuanced understanding. Furthermore, we identify common failure cases in both small and large MLLMs, highlighting domains where even state-of-the-art models struggle. We hope our findings will guide the research community in pushing the quality boundaries of MLLMs, advancing their usability and effectiveness across diverse applications.
A Robust Federated Learning Framework for Undependable Devices at Scale
Dec 28, 2024
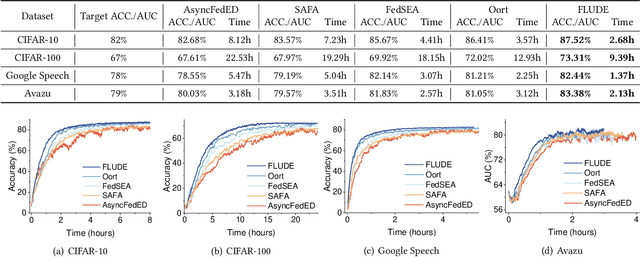
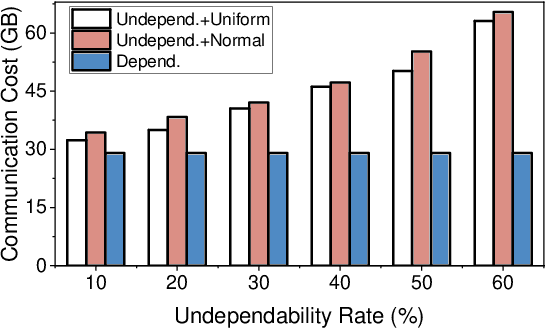
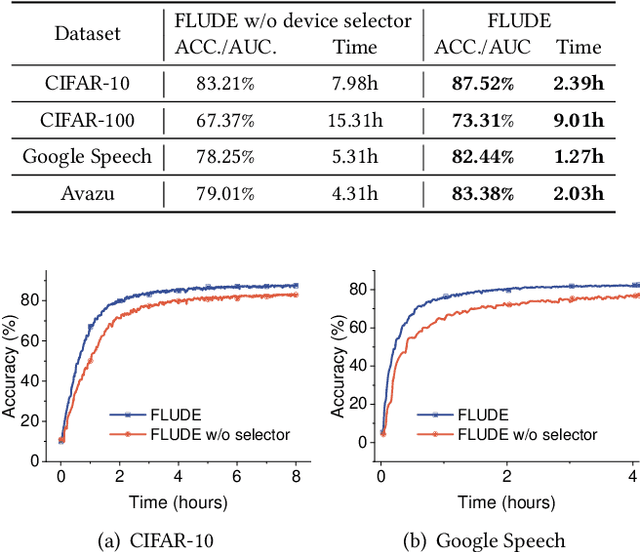
In a federated learning (FL) system, many devices, such as smartphones, are often undependable (e.g., frequently disconnected from WiFi) during training. Existing FL frameworks always assume a dependable environment and exclude undependable devices from training, leading to poor model performance and resource wastage. In this paper, we propose FLUDE to effectively deal with undependable environments. First, FLUDE assesses the dependability of devices based on the probability distribution of their historical behaviors (e.g., the likelihood of successfully completing training). Based on this assessment, FLUDE adaptively selects devices with high dependability for training. To mitigate resource wastage during the training phase, FLUDE maintains a model cache on each device, aiming to preserve the latest training state for later use in case local training on an undependable device is interrupted. Moreover, FLUDE proposes a staleness-aware strategy to judiciously distribute the global model to a subset of devices, thus significantly reducing resource wastage while maintaining model performance. We have implemented FLUDE on two physical platforms with 120 smartphones and NVIDIA Jetson devices. Extensive experimental results demonstrate that FLUDE can effectively improve model performance and resource efficiency of FL training in undependable environments.
Pluralistic Salient Object Detection
Sep 04, 2024



We introduce pluralistic salient object detection (PSOD), a novel task aimed at generating multiple plausible salient segmentation results for a given input image. Unlike conventional SOD methods that produce a single segmentation mask for salient objects, this new setting recognizes the inherent complexity of real-world images, comprising multiple objects, and the ambiguity in defining salient objects due to different user intentions. To study this task, we present two new SOD datasets "DUTS-MM" and "DUS-MQ", along with newly designed evaluation metrics. DUTS-MM builds upon the DUTS dataset but enriches the ground-truth mask annotations from three aspects which 1) improves the mask quality especially for boundary and fine-grained structures; 2) alleviates the annotation inconsistency issue; and 3) provides multiple ground-truth masks for images with saliency ambiguity. DUTS-MQ consists of approximately 100K image-mask pairs with human-annotated preference scores, enabling the learning of real human preferences in measuring mask quality. Building upon these two datasets, we propose a simple yet effective pluralistic SOD baseline based on a Mixture-of-Experts (MOE) design. Equipped with two prediction heads, it simultaneously predicts multiple masks using different query prompts and predicts human preference scores for each mask candidate. Extensive experiments and analyses underscore the significance of our proposed datasets and affirm the effectiveness of our PSOD framework.
A First Physical-World Trajectory Prediction Attack via LiDAR-induced Deceptions in Autonomous Driving
Jun 17, 2024



Trajectory prediction forecasts nearby agents' moves based on their historical trajectories. Accurate trajectory prediction is crucial for autonomous vehicles. Existing attacks compromise the prediction model of a victim AV by directly manipulating the historical trajectory of an attacker AV, which has limited real-world applicability. This paper, for the first time, explores an indirect attack approach that induces prediction errors via attacks against the perception module of a victim AV. Although it has been shown that physically realizable attacks against LiDAR-based perception are possible by placing a few objects at strategic locations, it is still an open challenge to find an object location from the vast search space in order to launch effective attacks against prediction under varying victim AV velocities. Through analysis, we observe that a prediction model is prone to an attack focusing on a single point in the scene. Consequently, we propose a novel two-stage attack framework to realize the single-point attack. The first stage of prediction-side attack efficiently identifies, guided by the distribution of detection results under object-based attacks against perception, the state perturbations for the prediction model that are effective and velocity-insensitive. In the second stage of location matching, we match the feasible object locations with the found state perturbations. Our evaluation using a public autonomous driving dataset shows that our attack causes a collision rate of up to 63% and various hazardous responses of the victim AV. The effectiveness of our attack is also demonstrated on a real testbed car. To the best of our knowledge, this study is the first security analysis spanning from LiDAR-based perception to prediction in autonomous driving, leading to a realistic attack on prediction. To counteract the proposed attack, potential defenses are discussed.
Exploring Pre-trained Text-to-Video Diffusion Models for Referring Video Object Segmentation
Mar 18, 2024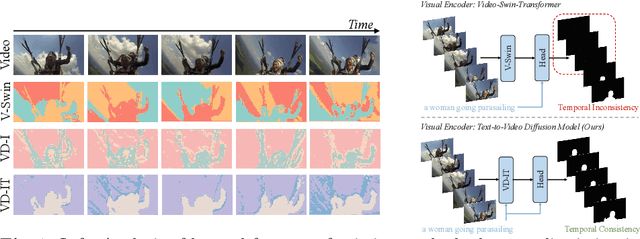
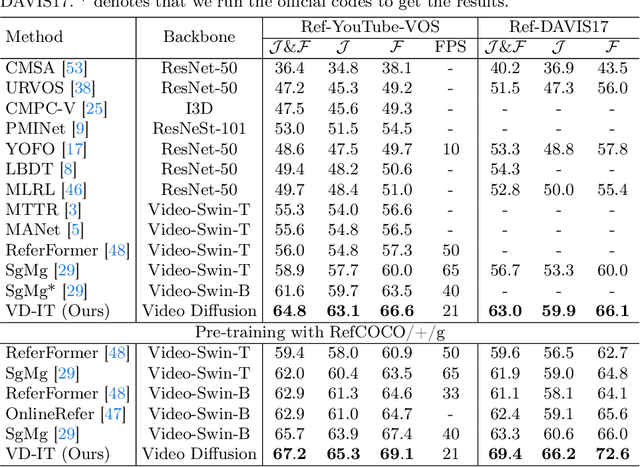
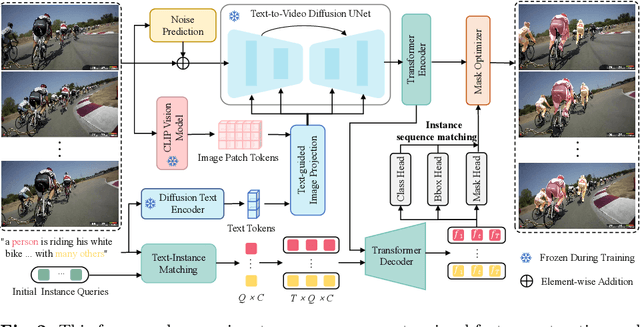
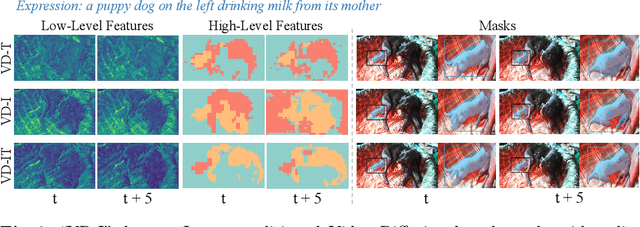
In this paper, we explore the visual representations produced from a pre-trained text-to-video (T2V) diffusion model for video understanding tasks. We hypothesize that the latent representation learned from a pretrained generative T2V model encapsulates rich semantics and coherent temporal correspondences, thereby naturally facilitating video understanding. Our hypothesis is validated through the classic referring video object segmentation (R-VOS) task. We introduce a novel framework, termed ``VD-IT'', tailored with dedicatedly designed components built upon a fixed pretrained T2V model. Specifically, VD-IT uses textual information as a conditional input, ensuring semantic consistency across time for precise temporal instance matching. It further incorporates image tokens as supplementary textual inputs, enriching the feature set to generate detailed and nuanced masks.Besides, instead of using the standard Gaussian noise, we propose to predict the video-specific noise with an extra noise prediction module, which can help preserve the feature fidelity and elevates segmentation quality. Through extensive experiments, we surprisingly observe that fixed generative T2V diffusion models, unlike commonly used video backbones (e.g., Video Swin Transformer) pretrained with discriminative image/video pre-tasks, exhibit better potential to maintain semantic alignment and temporal consistency. On existing standard benchmarks, our VD-IT achieves highly competitive results, surpassing many existing state-of-the-art methods. The code will be available at \url{https://github.com/buxiangzhiren/VD-IT}
MergeSFL: Split Federated Learning with Feature Merging and Batch Size Regulation
Nov 22, 2023Recently, federated learning (FL) has emerged as a popular technique for edge AI to mine valuable knowledge in edge computing (EC) systems. To mitigate the computing/communication burden on resource-constrained workers and protect model privacy, split federated learning (SFL) has been released by integrating both data and model parallelism. Despite resource limitations, SFL still faces two other critical challenges in EC, i.e., statistical heterogeneity and system heterogeneity. To address these challenges, we propose a novel SFL framework, termed MergeSFL, by incorporating feature merging and batch size regulation in SFL. Concretely, feature merging aims to merge the features from workers into a mixed feature sequence, which is approximately equivalent to the features derived from IID data and is employed to promote model accuracy. While batch size regulation aims to assign diverse and suitable batch sizes for heterogeneous workers to improve training efficiency. Moreover, MergeSFL explores to jointly optimize these two strategies upon their coupled relationship to better enhance the performance of SFL. Extensive experiments are conducted on a physical platform with 80 NVIDIA Jetson edge devices, and the experimental results show that MergeSFL can improve the final model accuracy by 5.82% to 26.22%, with a speedup by about 1.74x to 4.14x, compared to the baselines.