 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-Efficient Federated Fine-Tuning Large Language Models for Heterogeneous Data
Mar 27, 2025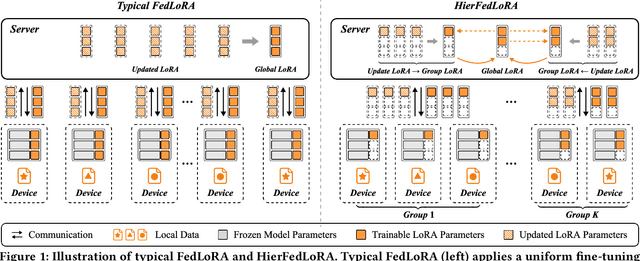
Fine-tuning large language models (LLMs) via federated learning, i.e., FedLLM, has been proposed to adapt LLMs for various downstream applications in a privacy-preserving way. To reduce the fine-tuning costs on resource-constrained devices, FedLoRA is proposed to fine-tune only a small subset of model parameters by integrating low-rank adaptation (LoRA) into FedLLM. However, apart from resource constraints, there is still another critical challenge, i.e., data heterogeneity, severely hindering the implementation of FedLoRA in practical applications. Herein, inspired by the previous group-based federated learning paradigm, we propose a hierarchical FedLoRA framework, termed HierFedLoRA, to address these challenges. Specifically, HierFedLoRA partitions all devices into multiple near-IID groups and adjusts the intra-group aggregation frequency for each group to eliminate the negative effects of non-IID data. Meanwhile, to reduce the computation and communication cost, HierFedLoRA dynamically assigns diverse and suitable fine-tuning depth (i.e., the number of continuous fine-tuning layers from the output) for each group. HierFedLoRA explores jointly optimizing aggregation frequency and depth upon their coupled relationship to better enhance the performance of FedLoRA. Extensive experiments are conducted on a physical platform with 80 commercial devices. The results show that HierFedLoRA improves the final model accuracy by 1.6% to 4.2%, speeding up the fine-tuning process by at least 2.1$\times$, compared to the strong baselines.
Lightweight and Post-Training Structured Pruning for On-Device Large Lanaguage Models
Jan 25, 2025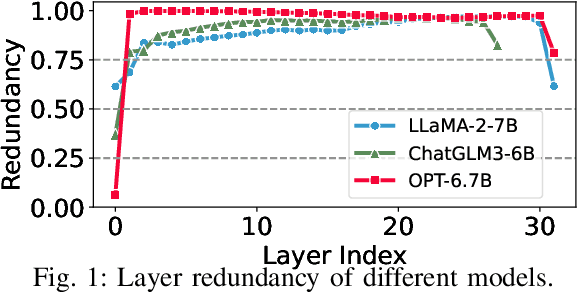



Considering the hardware-friendly characteristics and broad applicability, structured pruning has emerged as an efficient solution to reduce the resource demands of large language models (LLMs) on resource-constrained devices. Traditional structured pruning methods often need fine-tuning to recover performance loss, which incurs high memory overhead and substantial data requirements, rendering them unsuitable for on-device applications. Additionally, post-training structured pruning techniques typically necessitate specific activation functions or architectural modifications, thereby limiting their scope of applications. Herein, we introduce COMP, a lightweight post-training structured pruning method that employs a hybrid-granularity pruning strategy. COMP initially prunes selected model layers based on their importance at a coarse granularity, followed by fine-grained neuron pruning within the dense layers of each remaining model layer. To more accurately evaluate neuron importance, COMP introduces a new matrix condition-based metric. Subsequently, COMP utilizes mask tuning to recover accuracy without the need for fine-tuning, significantly reducing memory consumption. Experimental results demonstrate that COMP improves performance by 6.13\% on the LLaMA-2-7B model with a 20\% pruning ratio compared to LLM-Pruner, while simultaneously reducing memory overhead by 80\%.
Efficient Deployment of Large Language Models on Resource-constrained Devices
Jan 05, 2025Deploying Large Language Models (LLMs) on resource-constrained (or weak) devices presents significant challenges due to limited resources and heterogeneous data distribution. To address the data concern, it is necessary to fine-tune LLMs using on-device private data for various downstream tasks. While Federated Learning (FL) offers a promising privacy-preserving solution, existing fine-tuning methods retain the original LLM size, leaving issues of high inference latency and excessive memory demands unresolved. Hence, we design FedSpine, an FL framework that combines Parameter- Efficient Fine-Tuning (PEFT) with structured pruning for efficient deployment of LLMs on resource-constrained devices. Specifically, FedSpine introduces an iterative process to prune and tune the parameters of LLMs. To mitigate the impact of device heterogeneity, an online Multi-Armed Bandit (MAB) algorithm is employed to adaptively determine different pruning ratios and LoRA ranks for heterogeneous devices without any prior knowledge of their computing and communication capabilities. As a result, FedSpine maintains higher inference accuracy while improving fine-tuning efficiency. Experimental results conducted on a physical platform with 80 devices demonstrate that FedSpine can speed up fine-tuning by 1.4$\times$-6.9$\times$ and improve final accuracy by 0.4%-4.5% under the same sparsity level compared to other baselines.
Adaptive Parameter-Efficient Federated Fine-Tuning on Heterogeneous Devices
Dec 28, 2024Federated fine-tuning (FedFT) has been proposed to fine-tune the pre-trained language models in a distributed manner. However, there are two critical challenges for efficient FedFT in practical applications, i.e., resource constraints and system heterogeneity. Existing works rely on parameter-efficient fine-tuning methods, e.g., low-rank adaptation (LoRA), but with major limitations. Herein, based on the inherent characteristics of FedFT, we observe that LoRA layers with higher ranks added close to the output help to save resource consumption while achieving comparable fine-tuning performance. Then we propose a novel LoRA-based FedFT framework, termed LEGEND, which faces the difficulty of determining the number of LoRA layers (called, LoRA depth) and the rank of each LoRA layer (called, rank distribution). We analyze the coupled relationship between LoRA depth and rank distribution, and design an efficient LoRA configuration algorithm for heterogeneous devices, thereby promoting fine-tuning efficiency. Extensive experiments are conducted on a physical platform with 80 commercial devices. The results show that LEGEND can achieve a speedup of 1.5-2.8$\times$ and save communication costs by about 42.3% when achieving the target accuracy, compared to the advanced solutions.
MergeSFL: Split Federated Learning with Feature Merging and Batch Size Regulation
Nov 22, 2023Recently, federated learning (FL) has emerged as a popular technique for edge AI to mine valuable knowledge in edge computing (EC) systems. To mitigate the computing/communication burden on resource-constrained workers and protect model privacy, split federated learning (SFL) has been released by integrating both data and model parallelism. Despite resource limitations, SFL still faces two other critical challenges in EC, i.e., statistical heterogeneity and system heterogeneity. To address these challenges, we propose a novel SFL framework, termed MergeSFL, by incorporating feature merging and batch size regulation in SFL. Concretely, feature merging aims to merge the features from workers into a mixed feature sequence, which is approximately equivalent to the features derived from IID data and is employed to promote model accuracy. While batch size regulation aims to assign diverse and suitable batch sizes for heterogeneous workers to improve training efficiency. Moreover, MergeSFL explores to jointly optimize these two strategies upon their coupled relationship to better enhance the performance of SFL. Extensive experiments are conducted on a physical platform with 80 NVIDIA Jetson edge devices, and the experimental results show that MergeSFL can improve the final model accuracy by 5.82% to 26.22%, with a speedup by about 1.74x to 4.14x, compared to the baselines.