 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering LLMs for Culturally Localized Generation
Mar 24, 2026LLMs are deployed globally, yet produce responses biased towards cultures with abundant training data. Existing cultural localization approaches such as prompting or post-training alignment are black-box, hard to control, and do not reveal whether failures reflect missing knowledge or poor elicitation. In this paper, we address these gaps using mechanistic interpretability to uncover and manipulate cultural representations in LLMs. Leveraging sparse autoencoders, we identify interpretable features that encode culturally salient information and aggregate them into Cultural Embeddings (CuE). We use CuE both to analyze implicit cultural biases under underspecified prompts and to construct white-box steering interventions. Across multiple models, we show that CuE-based steering increases cultural faithfulness and elicits significantly rarer, long-tail cultural concepts than prompting alone. Notably, CuE-based steering is complementary to black-box localization methods, offering gains when applied on top of prompt-augmented inputs. This also suggests that models do benefit from better elicitation strategies, and don't necessarily lack long-tail knowledge representation, though this varies across cultures. Our results provide both diagnostic insight into cultural representations in LLMs and a controllable method to steer towards desired cultures.
OpenSage: Self-programming Agent Generation Engine
Feb 18, 2026Agent development kits (ADKs) provide effective platforms and tooling for constructing agents, and their designs are critical to the constructed agents' performance, especially the functionality for agent topology, tools, and memory. However, current ADKs either lack sufficient functional support or rely on humans to manually design these components, limiting agents' generalizability and overall performance. We propose OpenSage, the first ADK that enables LLMs to automatically create agents with self-generated topology and toolsets while providing comprehensive and structured memory support. OpenSage offers effective functionality for agents to create and manage their own sub-agents and toolkits. It also features a hierarchical, graph-based memory system for efficient management and a specialized toolkit tailored to software engineering tasks. Extensive experiments across three state-of-the-art benchmarks with various backbone models demonstrate the advantages of OpenSage over existing ADKs. We also conduct rigorous ablation studies to demonstrate the effectiveness of our design for each component. We believe OpenSage can pave the way for the next generation of agent development, shifting the focus from human-centered to AI-centered paradigms.
rePIRL: Learn PRM with Inverse RL for LLM Reasoning
Feb 08, 2026Process rewards have been widely used in deep reinforcement learning to improve training efficiency, reduce variance, and prevent reward hacking. In LLM reasoning, existing works also explore various solutions for learning effective process reward models (PRM) with or without the help of an expert policy. However, existing methods either rely on strong assumptions about the expert policies (e.g., requiring their reward functions) or suffer intrinsic limitations (e.g., entropy collapse), resulting in weak PRMs or limited generalizability. In this paper, we introduce rePIRL, an inverse RL-inspired framework that learns effective PRMs with minimal assumptions about expert policies. Specifically, we design a dual learning process that updates the policy and the PRM interchangeably. Our learning algorithm has customized techniques to address the challenges of scaling traditional inverse RL to LLMs. We theoretically show that our proposed learning framework can unify both online and offline PRM learning methods, justifying that rePIRL can learn PRMs with minimal assumptions. Empirical evaluations on standardized math and coding reasoning datasets demonstrate the effectiveness of rePIRL over existing methods. We further show the application of our trained PRM in test-time training, test-time scaling, and providing an early signal for training hard problems. Finally, we validate our training recipe and key design choices via a detailed ablation study.
TermiGen: High-Fidelity Environment and Robust Trajectory Synthesis for Terminal Agents
Feb 06, 2026Executing complex terminal tasks remains a significant challenge for open-weight LLMs, constrained by two fundamental limitations. First, high-fidelity, executable training environments are scarce: environments synthesized from real-world repositories are not diverse and scalable, while trajectories synthesized by LLMs suffer from hallucinations. Second, standard instruction tuning uses expert trajectories that rarely exhibit simple mistakes common to smaller models. This creates a distributional mismatch, leaving student models ill-equipped to recover from their own runtime failures. To bridge these gaps, we introduce TermiGen, an end-to-end pipeline for synthesizing verifiable environments and resilient expert trajectories. Termi-Gen first generates functionally valid tasks and Docker containers via an iterative multi-agent refinement loop. Subsequently, we employ a Generator-Critic protocol that actively injects errors during trajectory collection, synthesizing data rich in error-correction cycles. Fine-tuned on this TermiGen-generated dataset, our TermiGen-Qwen2.5-Coder-32B achieves a 31.3% pass rate on TerminalBench. This establishes a new open-weights state-of-the-art, outperforming existing baselines and notably surpassing capable proprietary models such as o4-mini. Dataset is avaiable at https://github.com/ucsb-mlsec/terminal-bench-env.
DevOps-Gym: Benchmarking AI Agents in Software DevOps Cycle
Jan 27, 2026Even though demonstrating extraordinary capabilities in code generation and software issue resolving, AI agents' capabilities in the full software DevOps cycle are still unknown. Different from pure code generation, handling the DevOps cycle in real-world software, including developing, deploying, and managing, requires analyzing large-scale projects, understanding dynamic program behaviors, leveraging domain-specific tools, and making sequential decisions. However, existing benchmarks focus on isolated problems and lack environments and tool interfaces for DevOps. We introduce DevOps-Gym, the first end-to-end benchmark for evaluating AI agents across core DevOps workflows: build and configuration, monitoring, issue resolving, and test generation. DevOps-Gym includes 700+ real-world tasks collected from 30+ projects in Java and Go. We develop a semi-automated data collection mechanism with rigorous and non-trivial expert efforts in ensuring the task coverage and quality. Our evaluation of state-of-the-art models and agents reveals fundamental limitations: they struggle with issue resolving and test generation in Java and Go, and remain unable to handle new tasks such as monitoring and build and configuration. These results highlight the need for essential research in automating the full DevOps cycle with AI agents.
MUSIC: MUlti-Step Instruction Contrast for Multi-Turn Reward Models
Dec 31, 2025Evaluating the quality of multi-turn conversations is crucial for developing capable Large Language Models (LLMs), yet remains a significant challenge, often requiring costly human evaluation. Multi-turn reward models (RMs) offer a scalable alternative and can provide valuable signals for guiding LLM training. While recent work has advanced multi-turn \textit{training} techniques, effective automated \textit{evaluation} specifically for multi-turn interactions lags behind. We observe that standard preference datasets, typically contrasting responses based only on the final conversational turn, provide insufficient signal to capture the nuances of multi-turn interactions. Instead, we find that incorporating contrasts spanning \textit{multiple} turns is critical for building robust multi-turn RMs. Motivated by this finding, we propose \textbf{MU}lti-\textbf{S}tep \textbf{I}nstruction \textbf{C}ontrast (MUSIC), an unsupervised data augmentation strategy that synthesizes contrastive conversation pairs exhibiting differences across multiple turns. Leveraging MUSIC on the Skywork preference dataset, we train a multi-turn RM based on the Gemma-2-9B-Instruct model. Empirical results demonstrate that our MUSIC-augmented RM outperforms baseline methods, achieving higher alignment with judgments from advanced proprietary LLM judges on multi-turn conversations, crucially, without compromising performance on standard single-turn RM benchmarks.
Fantastic Reasoning Behaviors and Where to Find Them: Unsupervised Discovery of the Reasoning Process
Dec 30, 2025Despite the growing reasoning capabilities of recent large language models (LLMs), their internal mechanisms during the reasoning process remain underexplored. Prior approaches often rely on human-defined concepts (e.g., overthinking, reflection) at the word level to analyze reasoning in a supervised manner. However, such methods are limited, as it is infeasible to capture the full spectrum of potential reasoning behaviors, many of which are difficult to define in token space. In this work, we propose an unsupervised framework (namely, RISE: Reasoning behavior Interpretability via Sparse auto-Encoder) for discovering reasoning vectors, which we define as directions in the activation space that encode distinct reasoning behaviors. By segmenting chain-of-thought traces into sentence-level 'steps' and training sparse auto-encoders (SAEs) on step-level activations, we uncover disentangled features corresponding to interpretable behaviors such as reflection and backtracking. Visualization and clustering analyses show that these behaviors occupy separable regions in the decoder column space. Moreover, targeted interventions on SAE-derived vectors can controllably amplify or suppress specific reasoning behaviors, altering inference trajectories without retraining. Beyond behavior-specific disentanglement, SAEs capture structural properties such as response length, revealing clusters of long versus short reasoning traces. More interestingly, SAEs enable the discovery of novel behaviors beyond human supervision. We demonstrate the ability to control response confidence by identifying confidence-related vectors in the SAE decoder space. These findings underscore the potential of unsupervised latent discovery for both interpreting and controllably steering reasoning in LLMs.
Eliciting Behaviors in Multi-Turn Conversations
Dec 29, 2025Identifying specific and often complex behaviors from large language models (LLMs) in conversational settings is crucial for their evaluation. Recent work proposes novel techniques to find natural language prompts that induce specific behaviors from a target model, yet they are mainly studied in single-turn settings. In this work, we study behavior elicitation in the context of multi-turn conversations. We first offer an analytical framework that categorizes existing methods into three families based on their interactions with the target model: those that use only prior knowledge, those that use offline interactions, and those that learn from online interactions. We then introduce a generalized multi-turn formulation of the online method, unifying single-turn and multi-turn elicitation. We evaluate all three families of methods on automatically generating multi-turn test cases. We investigate the efficiency of these approaches by analyzing the trade-off between the query budget, i.e., the number of interactions with the target model, and the success rate, i.e., the discovery rate of behavior-eliciting inputs. We find that online methods can achieve an average success rate of 45/19/77% with just a few thousand queries over three tasks where static methods from existing multi-turn conversation benchmarks find few or even no failure cases. Our work highlights a novel application of behavior elicitation methods in multi-turn conversation evaluation and the need for the community to move towards dynamic benchmarks.
Comparative Analysis of Large Language Models for Context-Aware Code Completion using SAFIM Framework
Feb 21, 2025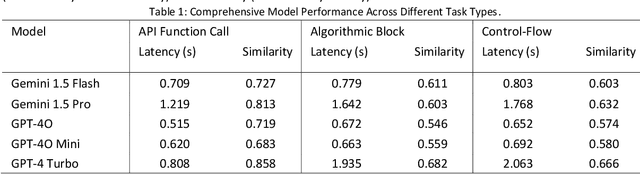
The advent of Large Language Models (LLMs) has revolutionized code completion, transforming it into a more intelligent and context-aware feature in modern integrated development environments. These advancements have significantly enhanced developers' ability to write efficient and error-free code. This study evaluates the performance of several chat-based LLMs, including Gemini 1.5 Flash, Gemini 1.5 Pro, GPT-4o, GPT-4o-mini, and GPT-4 Turbo, using the Syntax-Aware Fill-in-the-Middle (SAFIM) dataset. This benchmark is specifically designed to assess models' capabilities in syntax-sensitive code generation. Performance metrics, such as cosine similarity with ground-truth completions and latency, were employed to measure both accuracy and efficiency. The findings reveal substantial differences in the models' code completion abilities, offering valuable insights into their respective strengths and weaknesses. This work provides a comparative analysis that underscores the trade-offs between accuracy and speed, establishing a benchmark for future advancements in LLM-based code completion.
Deep Semantic Graph Learning via LLM based Node Enhancement
Feb 11, 2025Graph learning has attracted significant attention due to its widespread real-world applications. Current mainstream approaches rely on text node features and obtain initial node embeddings through shallow embedding learning using GNNs, which shows limitations in capturing deep textual semantics. Recent advances in Large Language Models (LLMs) have demonstrated superior capabilities in understanding text semantics, transforming traditional text feature processing. This paper proposes a novel framework that combines Graph Transformer architecture with LLM-enhanced node features. Specifically, we leverage LLMs to generate rich semantic representations of text nodes, which are then processed by a multi-head self-attention mechanism in the Graph Transformer to capture both local and global graph structural information. Our model utilizes the Transformer's attention mechanism to dynamically aggregate neighborhood information while preserving the semantic richness provided by LLM embeddings. Experimental results demonstrate that the LLM-enhanced node features significantly improve the performance of graph learning models on node classification tasks. This approach shows promising results across multiple graph learning tasks, offering a practical direction for combining graph networks with language models.