 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Jan 26, 2026Knowledge distillation improves large language model (LLM) reasoning by compressing the knowledge of a teacher LLM to train smaller LLMs. On-policy distillation advances this approach by having the student sample its own trajectories while a teacher LLM provides dense token-level supervision, addressing the distribution mismatch between training and inference in off-policy distillation methods. However, on-policy distillation typically requires a separate, often larger, teacher LLM and does not explicitly leverage ground-truth solutions available in reasoning datasets. Inspired by the intuition that a sufficiently capable LLM can rationalize external privileged reasoning traces and teach its weaker self (i.e., the version without access to privileged information), we introduce On-Policy Self-Distillation (OPSD), a framework where a single model acts as both teacher and student by conditioning on different contexts. The teacher policy conditions on privileged information (e.g., verified reasoning traces) while the student policy sees only the question; training minimizes the per-token divergence between these distributions over the student's own rollouts. We demonstrate the efficacy of our method on multiple mathematical reasoning benchmarks, achieving 4-8x token efficiency compared to reinforcement learning methods such as GRPO and superior performance over off-policy distillation methods.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
InfoChartQA: A Benchmark for Multimodal Question Answering on Infographic Charts
May 25, 2025Understanding infographic charts with design-driven visual elements (e.g., pictograms, icons) requires both visual recognition and reasoning, posing challenges for multimodal large language models (MLLMs). However, existing visual-question answering benchmarks fall short in evaluating these capabilities of MLLMs due to the lack of paired plain charts and visual-element-based questions. To bridge this gap, we introduce InfoChartQA, a benchmark for evaluating MLLMs on infographic chart understanding. It includes 5,642 pairs of infographic and plain charts, each sharing the same underlying data but differing in visual presentations. We further design visual-element-based questions to capture their unique visual designs and communicative intent. Evaluation of 20 MLLMs reveals a substantial performance decline on infographic charts, particularly for visual-element-based questions related to metaphors. The paired infographic and plain charts enable fine-grained error analysis and ablation studies, which highlight new opportunities for advancing MLLMs in infographic chart understanding. We release InfoChartQA at https://github.com/CoolDawnAnt/InfoChartQA.
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
Benchmarking Large and Small MLLMs
Jan 04, 2025



Large multimodal language models (MLLMs) such as GPT-4V and GPT-4o have achieved remarkable advancements in understanding and generating multimodal content, showcasing superior quality and capabilities across diverse tasks. However, their deployment faces significant challenges, including slow inference, high computational cost, and impracticality for on-device applications. In contrast, the emergence of small MLLMs, exemplified by the LLava-series models and Phi-3-Vision, offers promising alternatives with faster inference, reduced deployment costs, and the ability to handle domain-specific scenarios. Despite their growing presence, the capability boundaries between large and small MLLMs remain underexplored. In this work, we conduct a systematic and comprehensive evaluation to benchmark both small and large MLLMs, spanning general capabilities such as object recognition, temporal reasoning, and multimodal comprehension, as well as real-world applications in domains like industry and automotive. Our evaluation reveals that small MLLMs can achieve comparable performance to large models in specific scenarios but lag significantly in complex tasks requiring deeper reasoning or nuanced understanding. Furthermore, we identify common failure cases in both small and large MLLMs, highlighting domains where even state-of-the-art models struggle. We hope our findings will guide the research community in pushing the quality boundaries of MLLMs, advancing their usability and effectiveness across diverse applications.
ToolBridge: An Open-Source Dataset to Equip LLMs with External Tool Capabilities
Oct 08, 2024

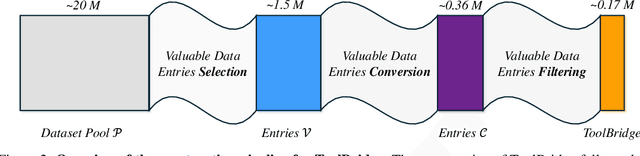

Through the integration of external tools, large language models (LLMs) such as GPT-4o and Llama 3.1 significantly expand their functional capabilities, evolving from elementary conversational agents to general-purpose assistants. We argue that the primary drivers of these advancements are the quality and diversity of the training data. However, the existing LLMs with external tool integration provide only limited transparency regarding their datasets and data collection methods, which has led to the initiation of this research. Specifically, in this paper, our objective is to elucidate the detailed process involved in constructing datasets that empower LLMs to effectively learn how to utilize external tools and make this information available to the public through the introduction of ToolBridge. ToolBridge proposes to employ a collection of general open-access datasets as its raw dataset pool and applies a series of strategies to identify appropriate data entries from the pool for external tool API insertions. By supervised fine-tuning on these curated data entries, LLMs can invoke external tools in appropriate contexts to boost their predictive accuracy, particularly for basic functions including data processing, numerical computation, and factual retrieval. Our experiments rigorously isolates model architectures and training configurations, focusing exclusively on the role of data. The experimental results indicate that LLMs trained on ToolBridge demonstrate consistent performance improvements on both standard benchmarks and custom evaluation datasets. All the associated code and data will be open-source at https://github.com/CharlesPikachu/ToolBridge, promoting transparency and facilitating the broader community to explore approaches for equipping LLMs with external tools capabilities.
SynChart: Synthesizing Charts from Language Models
Sep 25, 2024With the release of GPT-4V(O), its use in generating pseudo labels for multi-modality tasks has gained significant popularity. However, it is still a secret how to build such advanced models from its base large language models (LLMs). This work explores the potential of using LLMs alone for data generation and develop competitive multi-modality models focusing on chart understanding. We construct a large-scale chart dataset, SynChart, which contains approximately 4 million diverse chart images with over 75 million dense annotations, including data tables, code, descriptions, and question-answer sets. We trained a 4.2B chart-expert model using this dataset and achieve near-GPT-4O performance on the ChartQA task, surpassing GPT-4V.
On Pre-training of Multimodal Language Models Customized for Chart Understanding
Jul 19, 2024

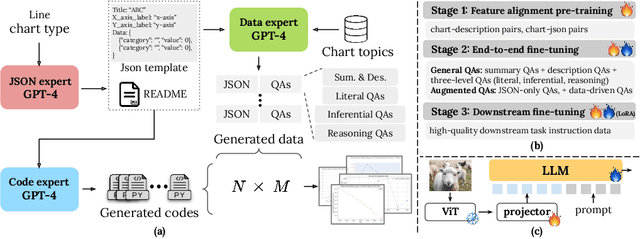

Recent studies customizing Multimodal Large Language Models (MLLMs) for domain-specific tasks have yielded promising results, especially in the field of scientific chart comprehension. These studies generally utilize visual instruction tuning with specialized datasets to enhance question and answer (QA) accuracy within the chart domain. However, they often neglect the fundamental discrepancy between natural image-caption pre-training data and digital chart image-QA data, particularly in the models' capacity to extract underlying numeric values from charts. This paper tackles this oversight by exploring the training processes necessary to improve MLLMs' comprehension of charts. We present three key findings: (1) Incorporating raw data values in alignment pre-training markedly improves comprehension of chart data. (2) Replacing images with their textual representation randomly during end-to-end fine-tuning transfer the language reasoning capability to chart interpretation skills. (3) Requiring the model to first extract the underlying chart data and then answer the question in the fine-tuning can further improve the accuracy. Consequently, we introduce CHOPINLLM, an MLLM tailored for in-depth chart comprehension. CHOPINLLM effectively interprets various types of charts, including unannotated ones, while maintaining robust reasoning abilities. Furthermore, we establish a new benchmark to evaluate MLLMs' understanding of different chart types across various comprehension levels. Experimental results show that CHOPINLLM exhibits strong performance in understanding both annotated and unannotated charts across a wide range of types.
Real-Time Image Segmentation via Hybrid Convolutional-Transformer Architecture Search
Mar 15, 2024



Image segmentation is one of the most fundamental problems in computer vision and has drawn a lot of attentions due to its vast applications in image understanding and autonomous driving. However, designing effective and efficient segmentation neural architectures is a labor-intensive process that may require lots of trials by human experts. In this paper, we address the challenge of integrating multi-head self-attention into high resolution representation CNNs efficiently, by leveraging architecture search. Manually replacing convolution layers with multi-head self-attention is non-trivial due to the costly overhead in memory to maintain high resolution. By contrast, we develop a multi-target multi-branch supernet method, which not only fully utilizes the advantages of high-resolution features, but also finds the proper location for placing multi-head self-attention module. Our search algorithm is optimized towards multiple objective s (e.g., latency and mIoU) and capable of finding architectures on Pareto frontier with arbitrary number of branches in a single search. We further present a series of model via Hybrid Convolutional-Transformer Architecture Search (HyCTAS) method that searched for the best hybrid combination of light-weight convolution layers and memory-efficient self-attention layers between branches from different resolutions and fuse to high resolution for both efficiency and effectiveness. Extensive experiments demonstrate that HyCTAS outperforms previous methods on semantic segmentation task. Code and models are available at \url{https://github.com/MarvinYu1995/HyCTAS}.
An Evaluation of GPT-4V and Gemini in Online VQA
Dec 17, 2023



A comprehensive evaluation is critical to assess the capabilities of large multimodal models (LMM). In this study, we evaluate the state-of-the-art LMMs, namely GPT-4V and Gemini, utilizing the VQAonline dataset. VQAonline is an end-to-end authentic VQA dataset sourced from a diverse range of everyday users. Compared previous benchmarks, VQAonline well aligns with real-world tasks. It enables us to effectively evaluate the generality of an LMM, and facilitates a direct comparison with human performance. To comprehensively evaluate GPT-4V and Gemini, we generate seven types of metadata for around 2,000 visual questions, such as image type and the required image processing capabilities. Leveraging this array of metadata, we analyze the zero-shot performance of GPT-4V and Gemini, and identify the most challenging questions for both models.