 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccounting for Focus Ambiguity in Visual Questions
Jan 04, 2025



No existing work on visual question answering explicitly accounts for ambiguity regarding where the content described in the question is located in the image. To fill this gap, we introduce VQ-FocusAmbiguity, the first VQA dataset that visually grounds each region described in the question that is necessary to arrive at the answer. We then provide an analysis showing how our dataset for visually grounding `questions' is distinct from visually grounding `answers', and characterize the properties of the questions and segmentations provided in our dataset. Finally, we benchmark modern models for two novel tasks: recognizing whether a visual question has focus ambiguity and localizing all plausible focus regions within the image. Results show that the dataset is challenging for modern models. To facilitate future progress on these tasks, we publicly share the dataset with an evaluation server at https://focusambiguity.github.io/.
Long-Form Answers to Visual Questions from Blind and Low Vision People
Aug 12, 2024



Vision language models can now generate long-form answers to questions about images - long-form visual question answers (LFVQA). We contribute VizWiz-LF, a dataset of long-form answers to visual questions posed by blind and low vision (BLV) users. VizWiz-LF contains 4.2k long-form answers to 600 visual questions, collected from human expert describers and six VQA models. We develop and annotate functional roles of sentences of LFVQA and demonstrate that long-form answers contain information beyond the question answer such as explanations and suggestions. We further conduct automatic and human evaluations with BLV and sighted people to evaluate long-form answers. BLV people perceive both human-written and generated long-form answers to be plausible, but generated answers often hallucinate incorrect visual details, especially for unanswerable visual questions (e.g., blurry or irrelevant images). To reduce hallucinations, we evaluate the ability of VQA models to abstain from answering unanswerable questions across multiple prompting strategies.
An Evaluation of GPT-4V and Gemini in Online VQA
Dec 17, 2023



A comprehensive evaluation is critical to assess the capabilities of large multimodal models (LMM). In this study, we evaluate the state-of-the-art LMMs, namely GPT-4V and Gemini, utilizing the VQAonline dataset. VQAonline is an end-to-end authentic VQA dataset sourced from a diverse range of everyday users. Compared previous benchmarks, VQAonline well aligns with real-world tasks. It enables us to effectively evaluate the generality of an LMM, and facilitates a direct comparison with human performance. To comprehensively evaluate GPT-4V and Gemini, we generate seven types of metadata for around 2,000 visual questions, such as image type and the required image processing capabilities. Leveraging this array of metadata, we analyze the zero-shot performance of GPT-4V and Gemini, and identify the most challenging questions for both models.
Fully Authentic Visual Question Answering Dataset from Online Communities
Nov 27, 2023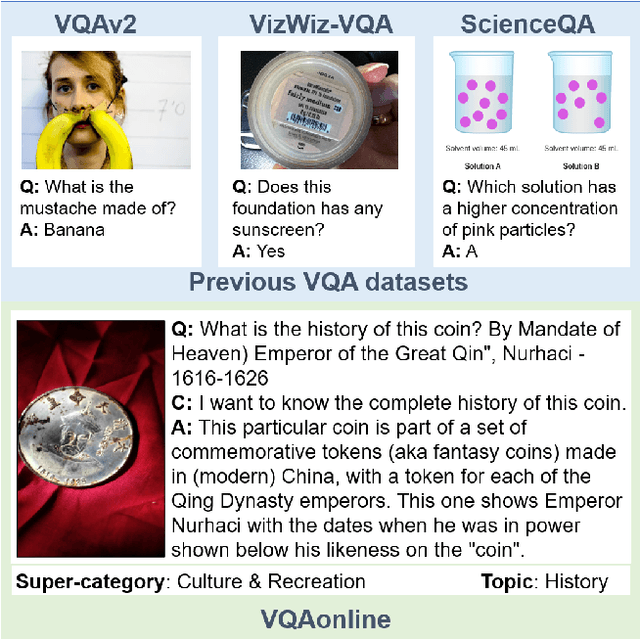
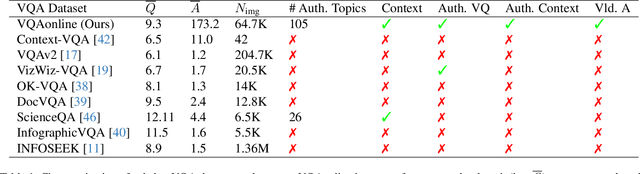
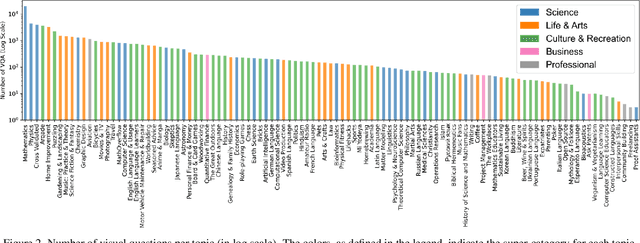
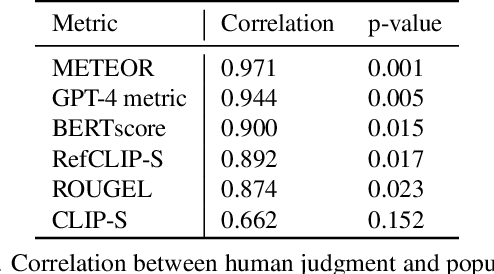
Visual Question Answering (VQA) entails answering questions about images. We introduce the first VQA dataset in which all contents originate from an authentic use case. Sourced from online question answering community forums, we call it VQAonline. We then characterize our dataset and how it relates to eight other VQA datasets. Observing that answers in our dataset tend to be much longer (e.g., with a mean of 173 words) and thus incompatible with standard VQA evaluation metrics, we next analyze which of the six popular metrics for longer text evaluation align best with human judgments. We then use the best-suited metrics to evaluate six state-of-the-art vision and language foundation models on VQAonline and reveal where they struggle most. We will release the dataset soon to facilitate future extensions.
VQA Therapy: Exploring Answer Differences by Visually Grounding Answers
Aug 24, 2023Visual question answering is a task of predicting the answer to a question about an image. Given that different people can provide different answers to a visual question, we aim to better understand why with answer groundings. We introduce the first dataset that visually grounds each unique answer to each visual question, which we call VQAAnswerTherapy. We then propose two novel problems of predicting whether a visual question has a single answer grounding and localizing all answer groundings. We benchmark modern algorithms for these novel problems to show where they succeed and struggle. The dataset and evaluation server can be found publicly at https://vizwiz.org/tasks-and-datasets/vqa-answer-therapy/.
Grounding Answers for Visual Questions Asked by Visually Impaired People
Feb 04, 2022
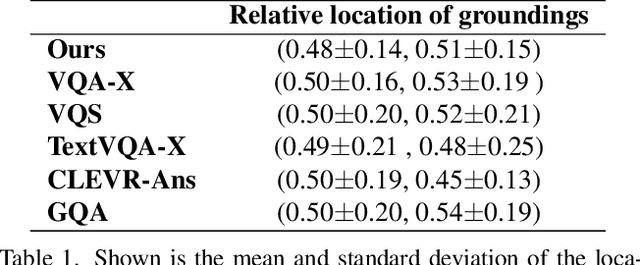
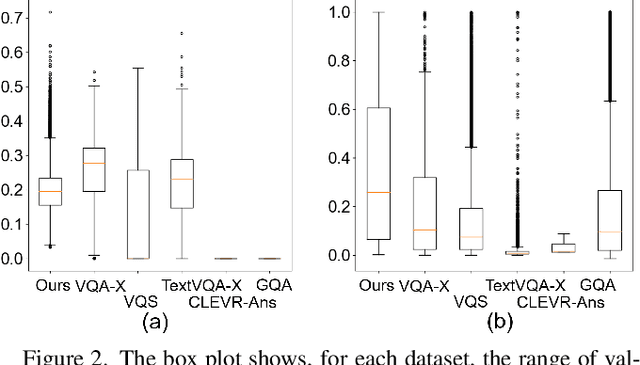

Visual question answering is the task of answering questions about images. We introduce the VizWiz-VQA-Grounding dataset, the first dataset that visually grounds answers to visual questions asked by people with visual impairments. We analyze our dataset and compare it with five VQA-Grounding datasets to demonstrate what makes it similar and different. We then evaluate the SOTA VQA and VQA-Grounding models and demonstrate that current SOTA algorithms often fail to identify the correct visual evidence where the answer is located. These models regularly struggle when the visual evidence occupies a small fraction of the image, for images that are higher quality, as well as for visual questions that require skills in text recognition. The dataset, evaluation server, and leaderboard all can be found at the following link: https://vizwiz.org/tasks-and-datasets/answer-grounding-for-vqa/.
Cross-Modal Contrastive Learning for Abnormality Classification and Localization in Chest X-rays with Radiomics using a Feedback Loop
Apr 19, 2021
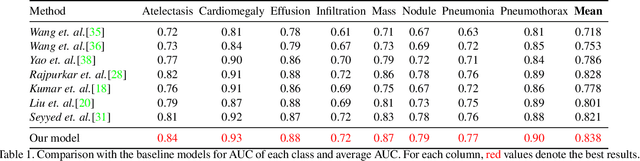
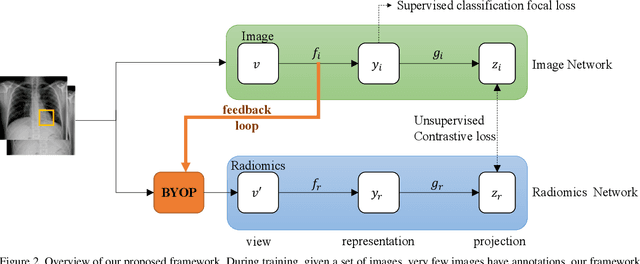
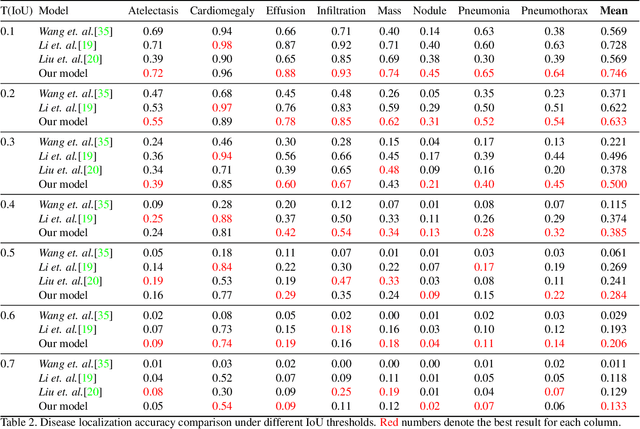
Building a highly accurate predictive model for these tasks usually requires a large number of manually annotated labels and pixel regions (bounding boxes) of abnormalities. However, it is expensive to acquire such annotations, especially the bounding boxes. Recently, contrastive learning has shown strong promise in leveraging unlabeled natural images to produce highly generalizable and discriminative features. However, extending its power to the medical image domain is under-explored and highly non-trivial, since medical images are much less amendable to data augmentations. In contrast, their domain knowledge, as well as multi-modality information, is often crucial. To bridge this gap, we propose an end-to-end semi-supervised cross-modal contrastive learning framework, that simultaneously performs disease classification and localization tasks. The key knob of our framework is a unique positive sampling approach tailored for the medical images, by seamlessly integrating radiomic features as an auxiliary modality. Specifically, we first apply an image encoder to classify the chest X-rays and to generate the image features. We next leverage Grad-CAM to highlight the crucial (abnormal) regions for chest X-rays (even when unannotated), from which we extract radiomic features. The radiomic features are then passed through another dedicated encoder to act as the positive sample for the image features generated from the same chest X-ray. In this way, our framework constitutes a feedback loop for image and radiomic modality features to mutually reinforce each other. Their contrasting yields cross-modality representations that are both robust and interpretable. Extensive experiments on the NIH Chest X-ray dataset demonstrate that our approach outperforms existing baselines in both classification and localization tasks.
Pneumonia Detection on Chest X-ray using Radiomic Features and Contrastive Learning
Jan 12, 2021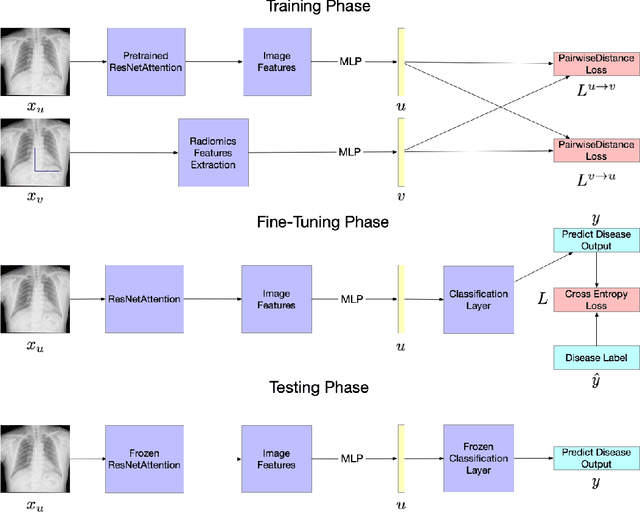
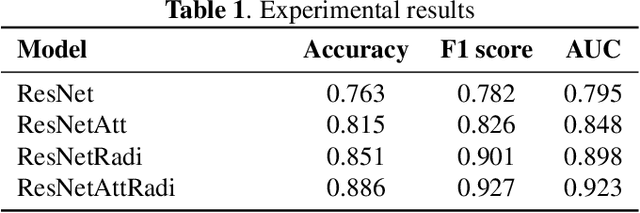
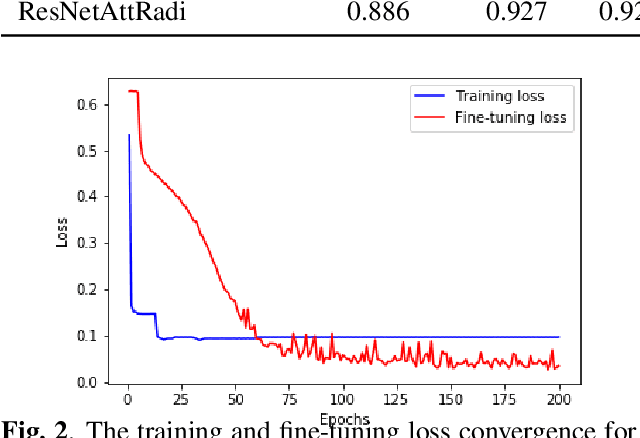
Chest X-ray becomes one of the most common medical diagnoses due to its noninvasiveness. The number of chest X-ray images has skyrocketed, but reading chest X-rays still have been manually performed by radiologists, which creates huge burnouts and delays. Traditionally, radiomics, as a subfield of radiology that can extract a large number of quantitative features from medical images, demonstrates its potential to facilitate medical imaging diagnosis before the deep learning era. With the rise of deep learning, the explainability of deep neural networks on chest X-ray diagnosis remains opaque. In this study, we proposed a novel framework that leverages radiomics features and contrastive learning to detect pneumonia in chest X-ray. Experiments on the RSNA Pneumonia Detection Challenge dataset show that our model achieves superior results to several state-of-the-art models (> 10% in F1-score) and increases the model's interpretability.
Using Radiomics as Prior Knowledge for Abnormality Classification and Localization in Chest X-rays
Nov 25, 2020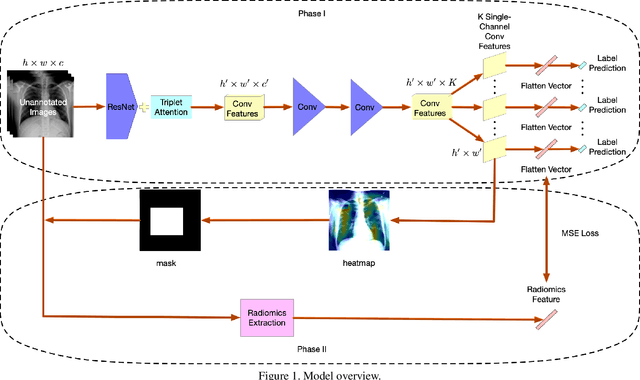


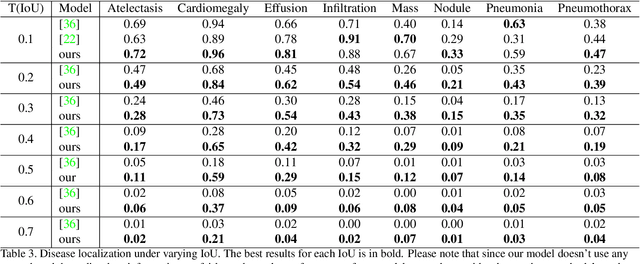
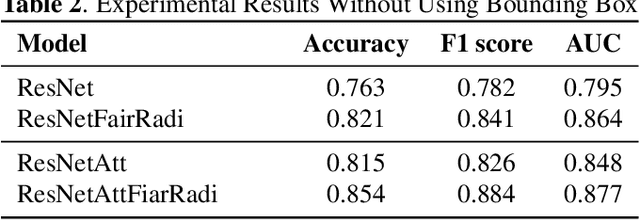
Chest X-rays become one of the most common medical diagnoses due to its noninvasiveness. The number of chest X-ray images has skyrocketed, but reading chest X-rays still have been manually performed by radiologists, which creates huge burnouts and delays. Traditionally, radiomics, as a subfield of radiology that can extract a large number of quantitative features from medical images, demonstrates its potential to facilitate medical imaging diagnosis before the deep learning era. In this paper, we develop an algorithm that can utilize the radiomics features to improve the abnormality classification performance. Our algorithm, ChexRadiNet, applies a light-weight but efficient triplet-attention mechanism for highlighting the meaningful image regions to improve localization accuracy. We first apply ChexRadiNet to classify the chest X-rays by using only image features. Then we use the generated heatmaps of chest X-rays to extract radiomics features. Finally, the extracted radiomics features could be used to guide our model to learn more robust accurate image features. After a number of iterations, our model could focus on more accurate image regions and extract more robust features. The empirical evaluation of our method supports our intuition and outperforms other state-of-the-art methods.