 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Answers for Visual Questions Asked by Visually Impaired People
Paper and Code

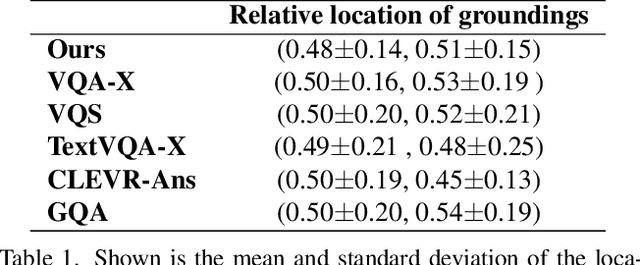
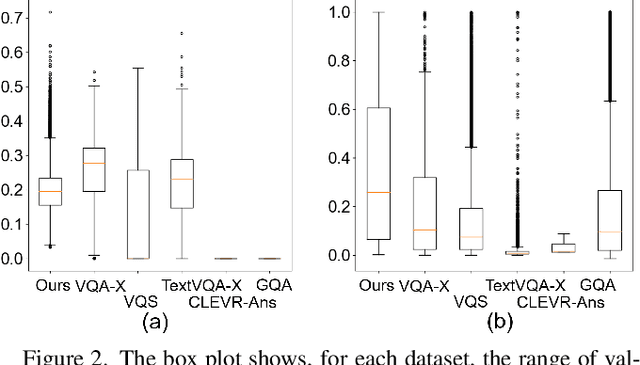

Visual question answering is the task of answering questions about images. We introduce the VizWiz-VQA-Grounding dataset, the first dataset that visually grounds answers to visual questions asked by people with visual impairments. We analyze our dataset and compare it with five VQA-Grounding datasets to demonstrate what makes it similar and different. We then evaluate the SOTA VQA and VQA-Grounding models and demonstrate that current SOTA algorithms often fail to identify the correct visual evidence where the answer is located. These models regularly struggle when the visual evidence occupies a small fraction of the image, for images that are higher quality, as well as for visual questions that require skills in text recognition. The dataset, evaluation server, and leaderboard all can be found at the following link: https://vizwiz.org/tasks-and-datasets/answer-grounding-for-vqa/.