 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollecting Consistently High Quality Object Tracks with Minimal Human Involvement by Using Self-Supervised Learning to Detect Tracker Errors
May 06, 2024We propose a hybrid framework for consistently producing high-quality object tracks by combining an automated object tracker with little human input. The key idea is to tailor a module for each dataset to intelligently decide when an object tracker is failing and so humans should be brought in to re-localize an object for continued tracking. Our approach leverages self-supervised learning on unlabeled videos to learn a tailored representation for a target object that is then used to actively monitor its tracked region and decide when the tracker fails. Since labeled data is not needed, our approach can be applied to novel object categories. Experiments on three datasets demonstrate our method outperforms existing approaches, especially for small, fast moving, or occluded objects.
VQA Therapy: Exploring Answer Differences by Visually Grounding Answers
Aug 24, 2023Visual question answering is a task of predicting the answer to a question about an image. Given that different people can provide different answers to a visual question, we aim to better understand why with answer groundings. We introduce the first dataset that visually grounds each unique answer to each visual question, which we call VQAAnswerTherapy. We then propose two novel problems of predicting whether a visual question has a single answer grounding and localizing all answer groundings. We benchmark modern algorithms for these novel problems to show where they succeed and struggle. The dataset and evaluation server can be found publicly at https://vizwiz.org/tasks-and-datasets/vqa-answer-therapy/.
Grounding Answers for Visual Questions Asked by Visually Impaired People
Feb 04, 2022
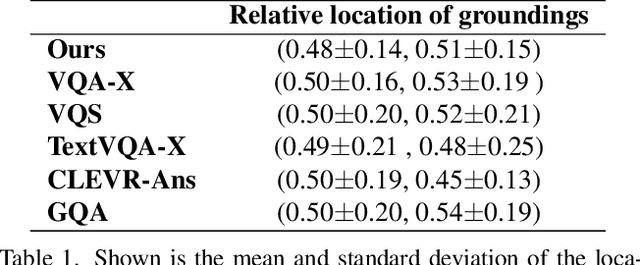
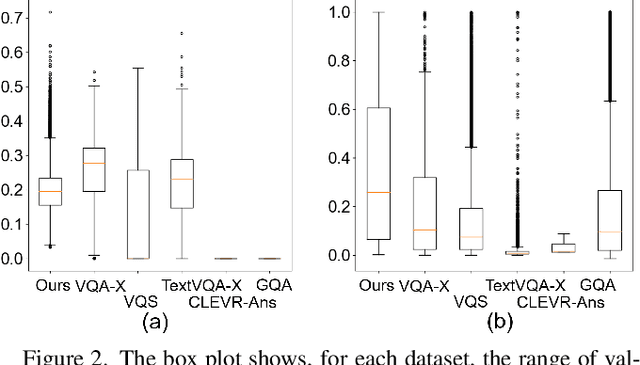

Visual question answering is the task of answering questions about images. We introduce the VizWiz-VQA-Grounding dataset, the first dataset that visually grounds answers to visual questions asked by people with visual impairments. We analyze our dataset and compare it with five VQA-Grounding datasets to demonstrate what makes it similar and different. We then evaluate the SOTA VQA and VQA-Grounding models and demonstrate that current SOTA algorithms often fail to identify the correct visual evidence where the answer is located. These models regularly struggle when the visual evidence occupies a small fraction of the image, for images that are higher quality, as well as for visual questions that require skills in text recognition. The dataset, evaluation server, and leaderboard all can be found at the following link: https://vizwiz.org/tasks-and-datasets/answer-grounding-for-vqa/.
CrowdMOT: Crowdsourcing Strategies for Tracking Multiple Objects in Videos
Sep 29, 2020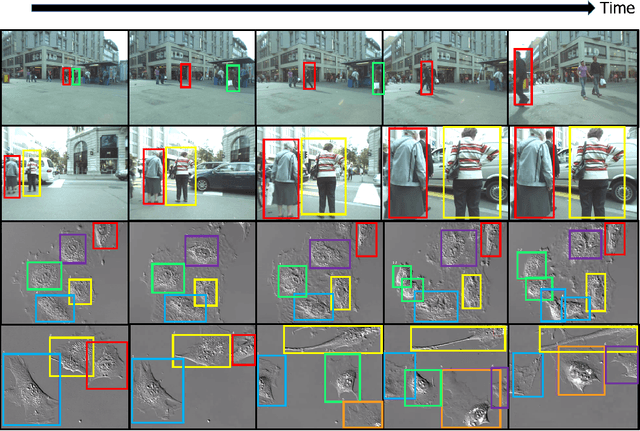
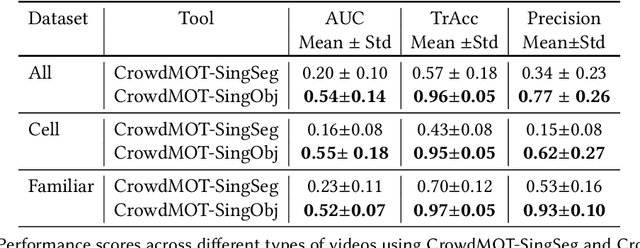
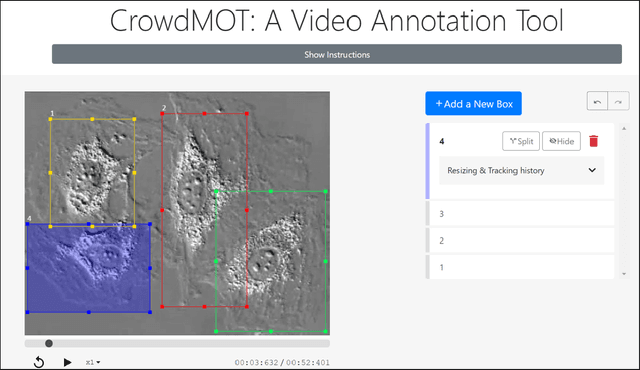
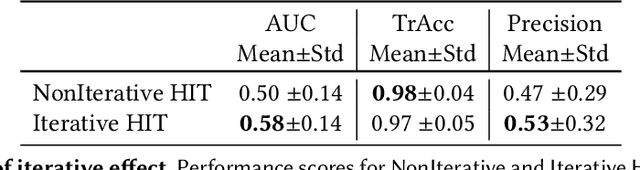
Crowdsourcing is a valuable approach for tracking objects in videos in a more scalable manner than possible with domain experts. However, existing frameworks do not produce high quality results with non-expert crowdworkers, especially for scenarios where objects split. To address this shortcoming, we introduce a crowdsourcing platform called CrowdMOT, and investigate two micro-task design decisions: (1) whether to decompose the task so that each worker is in charge of annotating all objects in a sub-segment of the video versus annotating a single object across the entire video, and (2) whether to show annotations from previous workers to the next individuals working on the task. We conduct experiments on a diversity of videos which show both familiar objects (aka - people) and unfamiliar objects (aka - cells). Our results highlight strategies for efficiently collecting higher quality annotations than observed when using strategies employed by today's state-of-art crowdsourcing system.