 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSifterNet: A Generalized and Model-Agnostic Trigger Purification Approach
May 20, 2025Aiming at resisting backdoor attacks in convolution neural networks and vision Transformer-based large model, this paper proposes a generalized and model-agnostic trigger-purification approach resorting to the classic Ising model. To date, existing trigger detection/removal studies usually require to know the detailed knowledge of target model in advance, access to a large number of clean samples or even model-retraining authorization, which brings the huge inconvenience for practical applications, especially inaccessible to target model. An ideal countermeasure ought to eliminate the implanted trigger without regarding whatever the target models are. To this end, a lightweight and black-box defense approach SifterNet is proposed through leveraging the memorization-association functionality of Hopfield network, by which the triggers of input samples can be effectively purified in a proper manner. The main novelty of our proposed approach lies in the introduction of ideology of Ising model. Extensive experiments also validate the effectiveness of our approach in terms of proper trigger purification and high accuracy achievement, and compared to the state-of-the-art baselines under several commonly-used datasets, our SiferNet has a significant superior performance.
HessianForge: Scalable LiDAR reconstruction with Physics-Informed Neural Representation and Smoothness Energy Constraints
Mar 11, 2025Accurate and efficient 3D mapping of large-scale outdoor environments from LiDAR measurements is a fundamental challenge in robotics, particularly towards ensuring smooth and artifact-free surface reconstructions. Although the state-of-the-art methods focus on memory-efficient neural representations for high-fidelity surface generation, they often fail to produce artifact-free manifolds, with artifacts arising due to noisy and sparse inputs. To address this issue, we frame surface mapping as a physics-informed energy optimization problem, enforcing surface smoothness by optimizing an energy functional that penalizes sharp surface ridges. Specifically, we propose a deep learning based approach that learns the signed distance field (SDF) of the surface manifold from raw LiDAR point clouds using a physics-informed loss function that optimizes the $L_2$-Hessian energy of the surface. Our learning framework includes a hierarchical octree based input feature encoding and a multi-scale neural network to iteratively refine the signed distance field at different scales of resolution. Lastly, we introduce a test-time refinement strategy to correct topological inconsistencies and edge distortions that can arise in the generated mesh. We propose a \texttt{CUDA}-accelerated least-squares optimization that locally adjusts vertex positions to enforce feature-preserving smoothing. We evaluate our approach on large-scale outdoor datasets and demonstrate that our approach outperforms current state-of-the-art methods in terms of improved accuracy and smoothness. Our code is available at \href{https://github.com/HrishikeshVish/HessianForge/}{https://github.com/HrishikeshVish/HessianForge/}
CrowdMOT: Crowdsourcing Strategies for Tracking Multiple Objects in Videos
Sep 29, 2020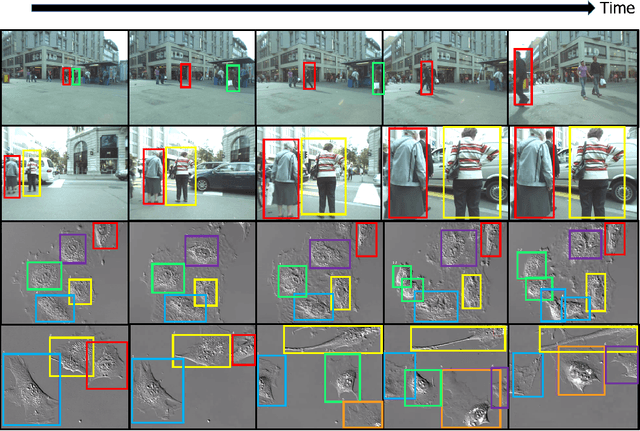
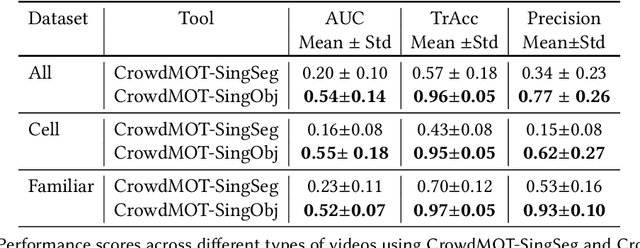
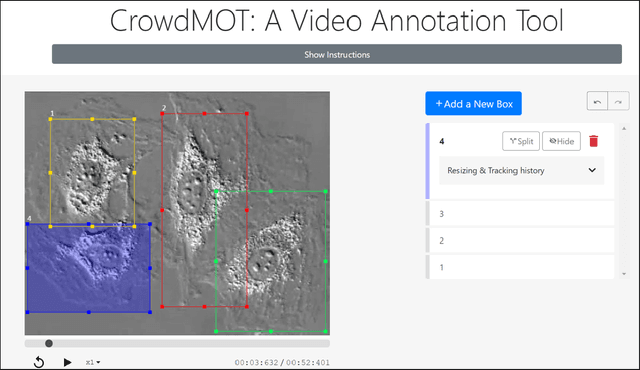
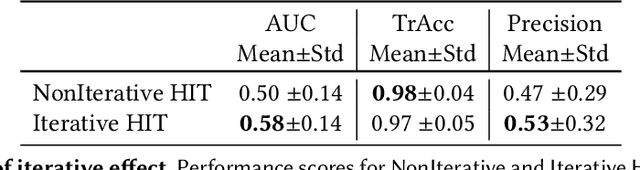
Crowdsourcing is a valuable approach for tracking objects in videos in a more scalable manner than possible with domain experts. However, existing frameworks do not produce high quality results with non-expert crowdworkers, especially for scenarios where objects split. To address this shortcoming, we introduce a crowdsourcing platform called CrowdMOT, and investigate two micro-task design decisions: (1) whether to decompose the task so that each worker is in charge of annotating all objects in a sub-segment of the video versus annotating a single object across the entire video, and (2) whether to show annotations from previous workers to the next individuals working on the task. We conduct experiments on a diversity of videos which show both familiar objects (aka - people) and unfamiliar objects (aka - cells). Our results highlight strategies for efficiently collecting higher quality annotations than observed when using strategies employed by today's state-of-art crowdsourcing system.
ChaLearn Looking at People: IsoGD and ConGD Large-scale RGB-D Gesture Recognition
Jul 29, 2019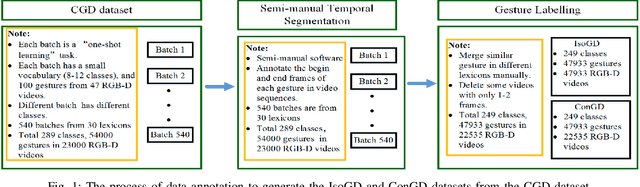


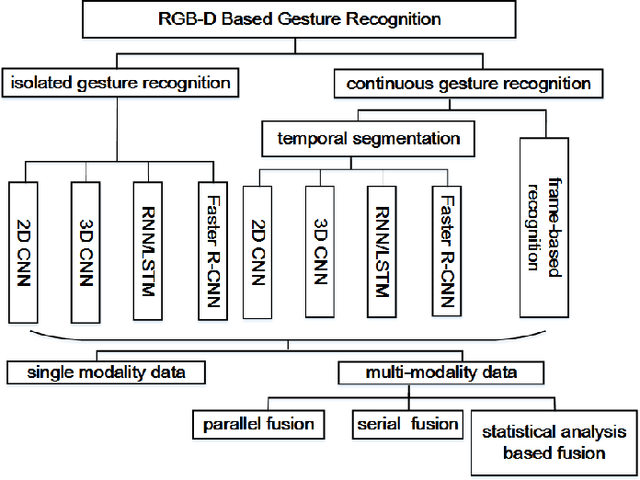
The ChaLearn large-scale gesture recognition challenge has been run twice in two workshops in conjunction with the International Conference on Pattern Recognition (ICPR) 2016 and International Conference on Computer Vision (ICCV) 2017, attracting more than $200$ teams round the world. This challenge has two tracks, focusing on isolated and continuous gesture recognition, respectively. This paper describes the creation of both benchmark datasets and analyzes the advances in large-scale gesture recognition based on these two datasets. We discuss the challenges of collecting large-scale ground-truth annotations of gesture recognition, and provide a detailed analysis of the current state-of-the-art methods for large-scale isolated and continuous gesture recognition based on RGB-D video sequences. In addition to recognition rate and mean jaccard index (MJI) as evaluation metrics used in our previous challenges, we also introduce the corrected segmentation rate (CSR) metric to evaluate the performance of temporal segmentation for continuous gesture recognition. Furthermore, we propose a bidirectional long short-term memory (Bi-LSTM) baseline method, determining the video division points based on the skeleton points extracted by convolutional pose machine (CPM). Experiments demonstrate that the proposed Bi-LSTM outperforms the state-of-the-art methods with an absolute improvement of $8.1\%$ (from $0.8917$ to $0.9639$) of CSR.
VizWiz Grand Challenge: Answering Visual Questions from Blind People
May 09, 2018
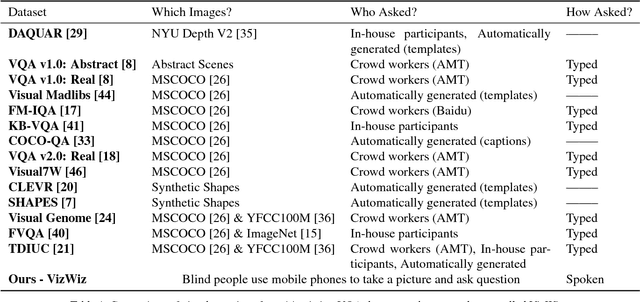

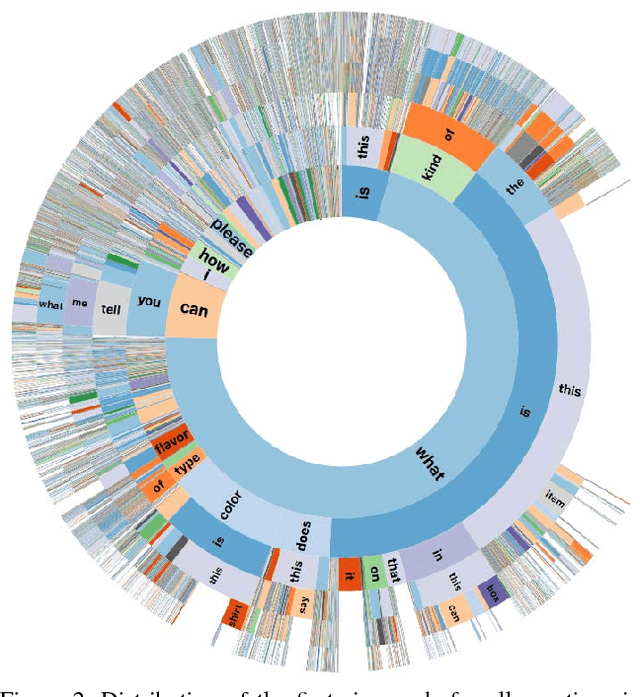
The study of algorithms to automatically answer visual questions currently is motivated by visual question answering (VQA) datasets constructed in artificial VQA settings. We propose VizWiz, the first goal-oriented VQA dataset arising from a natural VQA setting. VizWiz consists of over 31,000 visual questions originating from blind people who each took a picture using a mobile phone and recorded a spoken question about it, together with 10 crowdsourced answers per visual question. VizWiz differs from the many existing VQA datasets because (1) images are captured by blind photographers and so are often poor quality, (2) questions are spoken and so are more conversational, and (3) often visual questions cannot be answered. Evaluation of modern algorithms for answering visual questions and deciding if a visual question is answerable reveals that VizWiz is a challenging dataset. We introduce this dataset to encourage a larger community to develop more generalized algorithms that can assist blind people.