 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Statistical Effect of Rubric Modifications on Human-Autorater Agreement
May 07, 2026Autoraters, also referred to as LLM-as-judges, are increasingly used for evaluation and automated content moderation. However, there is limited statistical analysis of how modifications in a rubric presented to both humans and autoraters affect their score agreement. Rubrics that ask for an overall or \emph{holistic} judgment - for example, rating the ``quality'' of an essay - may be inconsistently interpreted due to the complexity or subjectivity of the criteria. Conversely, rubrics can ask for \emph{analytic} judgments, which decompose assessment criteria - for example, ``quality'' into ``fluency'' and ``organization''. While these rubrics can be edited to improve the individual accuracy of both human and automated scoring, this approach may result in disagreement between the two scores, or with the associated holistic judgment. Designing and deploying reliable autoraters requires understanding not just the relationship between human and autorater annotations but how that relationship changes as holistic or analytic judgments are elicited. The results indicate that rubric edits providing representative examples and additional context, and reducing positional bias in the rubric increased human-autorater agreement, while higher rubric complexity and conservative aggregation methods tended to decrease it. The findings from the automatic essay scoring and instruction-following evaluation domains suggest that practitioners should carefully analyze domain- and rubric-specific performance to move towards higher human-autorater agreement.
Efficient Personalization of Generative User Interfaces
Apr 10, 2026Generative user interfaces (UIs) create new opportunities to adapt interfaces to individual users on demand, but personalization remains difficult because desirable UI properties are subjective, hard to articulate, and costly to infer from sparse feedback. We study this problem through a new dataset in which 20 trained designers each provide pairwise judgments over the same 600 generated UIs, enabling direct analysis of preference divergence. We find substantial disagreement across designers (average kappa = 0.25), and written rationales reveal that even when designers appeal to similar concepts such as hierarchy or cleanliness, designers differ in how they define, prioritize, and apply those concepts. Motivated by these findings, we develop a sample-efficient personalization method that represents a new user in terms of prior designers rather than a fixed rubric of design concepts. In a technical evaluation, our preference model outperforms both a pretrained UI evaluator and a larger multimodal model, and scales better with additional feedback. When used to personalize generation, it also produces interfaces preferred by 12 new designers over baseline approaches, including direct user prompting. Our findings suggest that lightweight preference elicitation can serve as a practical foundation for personalized generative UI systems.
"I followed what felt right, not what I was told": Autonomy, Coaching, and Recognizing Bias Through AI-Mediated Dialogue
Mar 11, 2026Ableist microaggressions remain pervasive in everyday interactions, yet interventions to help people recognize them are limited. We present an experiment testing how AI-mediated dialogue influences recognition of ableism. 160 participants completed a pre-test, intervention, and a post-test across four conditions: AI nudges toward bias (Bias-Directed), inclusion (Neutral-Directed), unguided dialogue (Self-Directed), and a text-only non-dialogue (Reading). Participants rated scenarios on standardness of social experience and emotional impact; those in dialogue-based conditions also provided qualitative reflections. Quantitative results showed dialogue-based conditions produced stronger recognition than Reading, though trajectories diverged: biased nudges improved differentiation of bias from neutrality but increased overall negativity. Inclusive or no nudges remained more balanced, while Reading participants showed weaker gains and even declines. Qualitative findings revealed biased nudges were often rejected, while inclusive nudges were adopted as scaffolding. We contribute a validated vignette corpus, an AI-mediated intervention platform, and design implications highlighting trade-offs conversational systems face when integrating bias-related nudges.
Modeling Distinct Human Interaction in Web Agents
Feb 19, 2026Despite rapid progress in autonomous web agents, human involvement remains essential for shaping preferences and correcting agent behavior as tasks unfold. However, current agentic systems lack a principled understanding of when and why humans intervene, often proceeding autonomously past critical decision points or requesting unnecessary confirmation. In this work, we introduce the task of modeling human intervention to support collaborative web task execution. We collect CowCorpus, a dataset of 400 real-user web navigation trajectories containing over 4,200 interleaved human and agent actions. We identify four distinct patterns of user interaction with agents -- hands-off supervision, hands-on oversight, collaborative task-solving, and full user takeover. Leveraging these insights, we train language models (LMs) to anticipate when users are likely to intervene based on their interaction styles, yielding a 61.4-63.4% improvement in intervention prediction accuracy over base LMs. Finally, we deploy these intervention-aware models in live web navigation agents and evaluate them in a user study, finding a 26.5% increase in user-rated agent usefulness. Together, our results show structured modeling of human intervention leads to more adaptive, collaborative agents.
StepWrite: Adaptive Planning for Speech-Driven Text Generation
Aug 06, 2025



People frequently use speech-to-text systems to compose short texts with voice. However, current voice-based interfaces struggle to support composing more detailed, contextually complex texts, especially in scenarios where users are on the move and cannot visually track progress. Longer-form communication, such as composing structured emails or thoughtful responses, requires persistent context tracking, structured guidance, and adaptability to evolving user intentions--capabilities that conventional dictation tools and voice assistants do not support. We introduce StepWrite, a large language model-driven voice-based interaction system that augments human writing ability by enabling structured, hands-free and eyes-free composition of longer-form texts while on the move. StepWrite decomposes the writing process into manageable subtasks and sequentially guides users with contextually-aware non-visual audio prompts. StepWrite reduces cognitive load by offloading the context-tracking and adaptive planning tasks to the models. Unlike baseline methods like standard dictation features (e.g., Microsoft Word) and conversational voice assistants (e.g., ChatGPT Advanced Voice Mode), StepWrite dynamically adapts its prompts based on the evolving context and user intent, and provides coherent guidance without compromising user autonomy. An empirical evaluation with 25 participants engaging in mobile or stationary hands-occupied activities demonstrated that StepWrite significantly reduces cognitive load, improves usability and user satisfaction compared to baseline methods. Technical evaluations further confirmed StepWrite's capability in dynamic contextual prompt generation, accurate tone alignment, and effective fact checking. This work highlights the potential of structured, context-aware voice interactions in enhancing hands-free and eye-free communication in everyday multitasking scenarios.
CowPilot: A Framework for Autonomous and Human-Agent Collaborative Web Navigation
Jan 28, 2025



While much work on web agents emphasizes the promise of autonomously performing tasks on behalf of users, in reality, agents often fall short on complex tasks in real-world contexts and modeling user preference. This presents an opportunity for humans to collaborate with the agent and leverage the agent's capabilities effectively. We propose CowPilot, a framework supporting autonomous as well as human-agent collaborative web navigation, and evaluation across task success and task efficiency. CowPilot reduces the number of steps humans need to perform by allowing agents to propose next steps, while users are able to pause, reject, or take alternative actions. During execution, users can interleave their actions with the agent by overriding suggestions or resuming agent control when needed. We conducted case studies on five common websites and found that the human-agent collaborative mode achieves the highest success rate of 95% while requiring humans to perform only 15.2% of the total steps. Even with human interventions during task execution, the agent successfully drives up to half of task success on its own. CowPilot can serve as a useful tool for data collection and agent evaluation across websites, which we believe will enable research in how users and agents can work together. Video demonstrations are available at https://oaishi.github.io/cowpilot.html
AI Policy Projector: Grounding LLM Policy Design in Iterative Mapmaking
Sep 26, 2024Whether a large language model policy is an explicit constitution or an implicit reward model, it is challenging to assess coverage over the unbounded set of real-world situations that a policy must contend with. We introduce an AI policy design process inspired by mapmaking, which has developed tactics for visualizing and iterating on maps even when full coverage is not possible. With Policy Projector, policy designers can survey the landscape of model input-output pairs, define custom regions (e.g., "violence"), and navigate these regions with rules that can be applied to LLM outputs (e.g., if output contains "violence" and "graphic details," then rewrite without "graphic details"). Policy Projector supports interactive policy authoring using LLM classification and steering and a map visualization reflecting the policy designer's work. In an evaluation with 12 AI safety experts, our system helps policy designers to address problematic model behaviors extending beyond an existing, comprehensive harm taxonomy.
Towards Bidirectional Human-AI Alignment: A Systematic Review for Clarifications, Framework, and Future Directions
Jun 17, 2024Recent advancements in general-purpose AI have highlighted the importance of guiding AI systems towards the intended goals, ethical principles, and values of individuals and groups, a concept broadly recognized as alignment. However, the lack of clarified definitions and scopes of human-AI alignment poses a significant obstacle, hampering collaborative efforts across research domains to achieve this alignment. In particular, ML- and philosophy-oriented alignment research often views AI alignment as a static, unidirectional process (i.e., aiming to ensure that AI systems' objectives match humans) rather than an ongoing, mutual alignment problem [429]. This perspective largely neglects the long-term interaction and dynamic changes of alignment. To understand these gaps, we introduce a systematic review of over 400 papers published between 2019 and January 2024, spanning multiple domains such as Human-Computer Interaction (HCI), Natural Language Processing (NLP), Machine Learning (ML), and others. We characterize, define and scope human-AI alignment. From this, we present a conceptual framework of "Bidirectional Human-AI Alignment" to organize the literature from a human-centered perspective. This framework encompasses both 1) conventional studies of aligning AI to humans that ensures AI produces the intended outcomes determined by humans, and 2) a proposed concept of aligning humans to AI, which aims to help individuals and society adjust to AI advancements both cognitively and behaviorally. Additionally, we articulate the key findings derived from literature analysis, including discussions about human values, interaction techniques, and evaluations. To pave the way for future studies, we envision three key challenges for future directions and propose examples of potential future solutions.
UICoder: Finetuning Large Language Models to Generate User Interface Code through Automated Feedback
Jun 11, 2024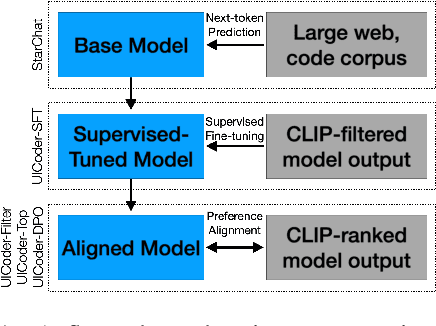

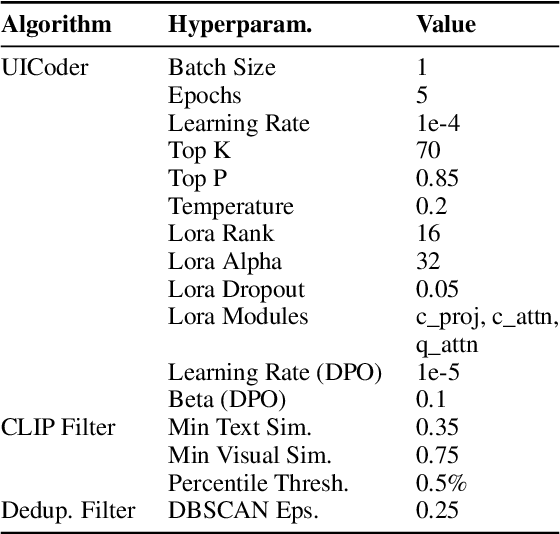

Large language models (LLMs) struggle to consistently generate UI code that compiles and produces visually relevant designs. Existing approaches to improve generation rely on expensive human feedback or distilling a proprietary model. In this paper, we explore the use of automated feedback (compilers and multi-modal models) to guide LLMs to generate high-quality UI code. Our method starts with an existing LLM and iteratively produces improved models by self-generating a large synthetic dataset using an original model, applying automated tools to aggressively filter, score, and de-duplicate the data into a refined higher quality dataset. The original LLM is improved by finetuning on this refined dataset. We applied our approach to several open-source LLMs and compared the resulting performance to baseline models with both automated metrics and human preferences. Our evaluation shows the resulting models outperform all other downloadable baselines and approach the performance of larger proprietary models.
"This really lets us see the entire world:" Designing a conversational telepresence robot for homebound older adults
May 23, 2024



In this paper, we explore the design and use of conversational telepresence robots to help homebound older adults interact with the external world. An initial needfinding study (N=8) using video vignettes revealed older adults' experiential needs for robot-mediated remote experiences such as exploration, reminiscence and social participation. We then designed a prototype system to support these goals and conducted a technology probe study (N=11) to garner a deeper understanding of user preferences for remote experiences. The study revealed user interactive patterns in each desired experience, highlighting the need of robot guidance, social engagements with the robot and the remote bystanders. Our work identifies a novel design space where conversational telepresence robots can be used to foster meaningful interactions in the remote physical environment. We offer design insights into the robot's proactive role in providing guidance and using dialogue to create personalized, contextualized and meaningful experiences.