 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Distinct Human Interaction in Web Agents
Feb 19, 2026Despite rapid progress in autonomous web agents, human involvement remains essential for shaping preferences and correcting agent behavior as tasks unfold. However, current agentic systems lack a principled understanding of when and why humans intervene, often proceeding autonomously past critical decision points or requesting unnecessary confirmation. In this work, we introduce the task of modeling human intervention to support collaborative web task execution. We collect CowCorpus, a dataset of 400 real-user web navigation trajectories containing over 4,200 interleaved human and agent actions. We identify four distinct patterns of user interaction with agents -- hands-off supervision, hands-on oversight, collaborative task-solving, and full user takeover. Leveraging these insights, we train language models (LMs) to anticipate when users are likely to intervene based on their interaction styles, yielding a 61.4-63.4% improvement in intervention prediction accuracy over base LMs. Finally, we deploy these intervention-aware models in live web navigation agents and evaluate them in a user study, finding a 26.5% increase in user-rated agent usefulness. Together, our results show structured modeling of human intervention leads to more adaptive, collaborative agents.
CowPilot: A Framework for Autonomous and Human-Agent Collaborative Web Navigation
Jan 28, 2025



While much work on web agents emphasizes the promise of autonomously performing tasks on behalf of users, in reality, agents often fall short on complex tasks in real-world contexts and modeling user preference. This presents an opportunity for humans to collaborate with the agent and leverage the agent's capabilities effectively. We propose CowPilot, a framework supporting autonomous as well as human-agent collaborative web navigation, and evaluation across task success and task efficiency. CowPilot reduces the number of steps humans need to perform by allowing agents to propose next steps, while users are able to pause, reject, or take alternative actions. During execution, users can interleave their actions with the agent by overriding suggestions or resuming agent control when needed. We conducted case studies on five common websites and found that the human-agent collaborative mode achieves the highest success rate of 95% while requiring humans to perform only 15.2% of the total steps. Even with human interventions during task execution, the agent successfully drives up to half of task success on its own. CowPilot can serve as a useful tool for data collection and agent evaluation across websites, which we believe will enable research in how users and agents can work together. Video demonstrations are available at https://oaishi.github.io/cowpilot.html
"This really lets us see the entire world:" Designing a conversational telepresence robot for homebound older adults
May 23, 2024



In this paper, we explore the design and use of conversational telepresence robots to help homebound older adults interact with the external world. An initial needfinding study (N=8) using video vignettes revealed older adults' experiential needs for robot-mediated remote experiences such as exploration, reminiscence and social participation. We then designed a prototype system to support these goals and conducted a technology probe study (N=11) to garner a deeper understanding of user preferences for remote experiences. The study revealed user interactive patterns in each desired experience, highlighting the need of robot guidance, social engagements with the robot and the remote bystanders. Our work identifies a novel design space where conversational telepresence robots can be used to foster meaningful interactions in the remote physical environment. We offer design insights into the robot's proactive role in providing guidance and using dialogue to create personalized, contextualized and meaningful experiences.
"What's important here?": Opportunities and Challenges of Using LLMs in Retrieving Information from Web Interfaces
Dec 11, 2023Large language models (LLMs) that have been trained on a corpus that includes large amount of code exhibit a remarkable ability to understand HTML code. As web interfaces are primarily constructed using HTML, we design an in-depth study to see how LLMs can be used to retrieve and locate important elements for a user given query (i.e. task description) in a web interface. In contrast with prior works, which primarily focused on autonomous web navigation, we decompose the problem as an even atomic operation - Can LLMs identify the important information in the web page for a user given query? This decomposition enables us to scrutinize the current capabilities of LLMs and uncover the opportunities and challenges they present. Our empirical experiments show that while LLMs exhibit a reasonable level of performance in retrieving important UI elements, there is still a substantial room for improvement. We hope our investigation will inspire follow-up works in overcoming the current challenges in this domain.
Riemannian Functional Map Synchronization for Probabilistic Partial Correspondence in Shape Networks
Nov 29, 2021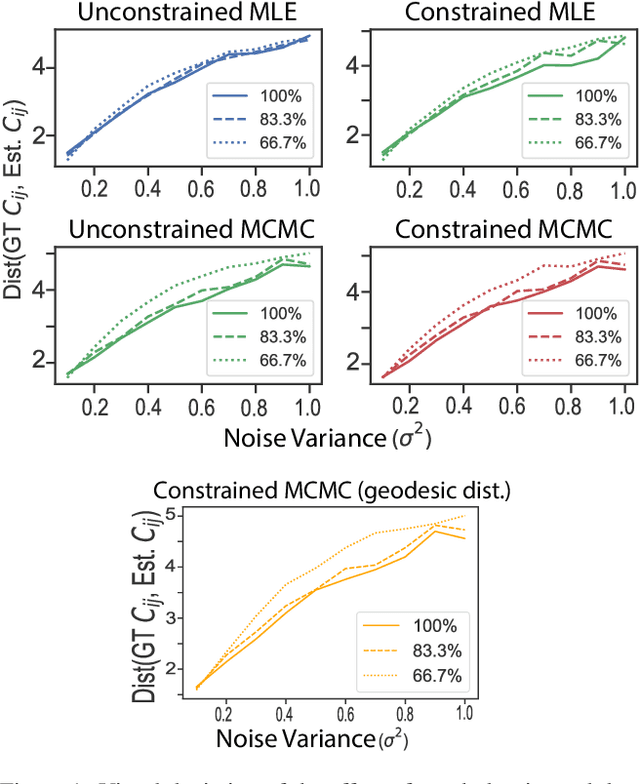
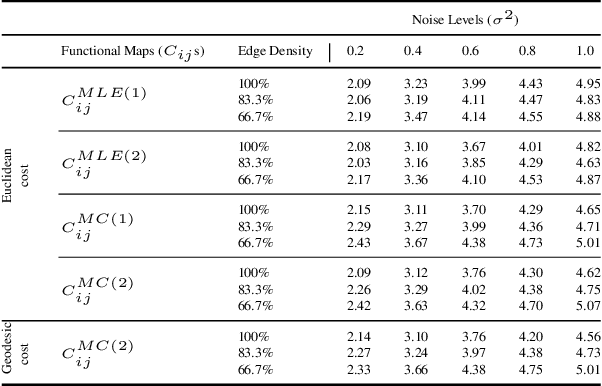
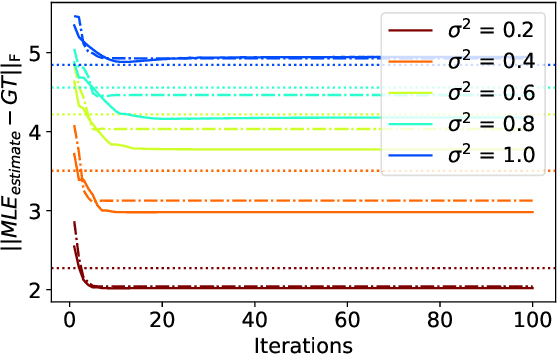
Functional maps are efficient representations of shape correspondences, that provide matching of real-valued functions between pairs of shapes. Functional maps can be modelled as elements of the Lie group $SO(n)$ for nearly isometric shapes. Synchronization can subsequently be employed to enforce cycle consistency between functional maps computed on a set of shapes, hereby enhancing the accuracy of the individual maps. There is an interest in developing synchronization methods that respect the geometric structure of $SO(n)$, while introducing a probabilistic framework to quantify the uncertainty associated with the synchronization results. This paper introduces a Bayesian probabilistic inference framework on $SO(n)$ for Riemannian synchronization of functional maps, performs a maximum-a-posteriori estimation of functional maps through synchronization and further deploys a Riemannian Markov-Chain Monte Carlo sampler for uncertainty quantification. Our experiments demonstrate that constraining the synchronization on the Riemannian manifold $SO(n)$ improves the estimation of the functional maps, while our Riemannian MCMC sampler provides for the first time an uncertainty quantification of the results.
Holistic static and animated 3D scene generation from diverse text descriptions
Oct 04, 2020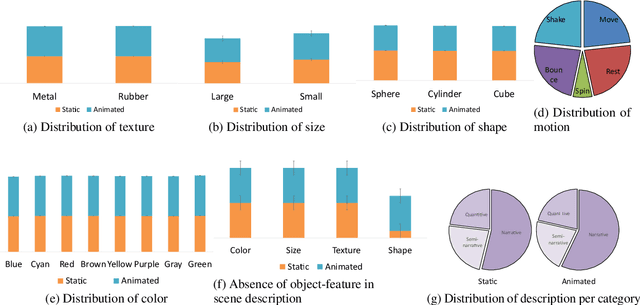
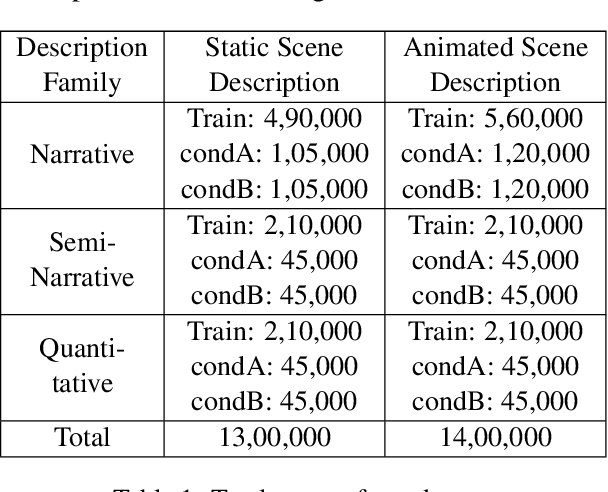


We propose a framework for holistic static and animated 3D scene generation from diverse text descriptions. Prior works of scene generation rely on static rule-based entity extraction from natural language description. However, this limits the usability of a practical solution. To overcome this limitation, we use one of state-of-the-art architecture - TransformerXL. Instead of rule-based extraction, our framework leverages the rich contextual encoding which allows us to process a larger range (diverse) of possible natural language descriptions. We empirically show how our proposed mechanism generalizes even on novel combinations of object-features during inference. We also show how our framework can jointly generate static and animated 3D scene efficiently. We modify CLEVR to generate a large, scalable dataset - Integrated static and animated 3D scene (Iscene). Data preparation code and pre-trained model available at - https://github.com/oaishi/3DScene_from_text.