 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Group Composition: A Window into the Mechanics of Deep Learning
Feb 03, 2026How do neural networks trained over sequences acquire the ability to perform structured operations, such as arithmetic, geometric, and algorithmic computation? To gain insight into this question, we introduce the sequential group composition task. In this task, networks receive a sequence of elements from a finite group encoded in a real vector space and must predict their cumulative product. The task can be order-sensitive and requires a nonlinear architecture to be learned. Our analysis isolates the roles of the group structure, encoding statistics, and sequence length in shaping learning. We prove that two-layer networks learn this task one irreducible representation of the group at a time in an order determined by the Fourier statistics of the encoding. These networks can perfectly learn the task, but doing so requires a hidden width exponential in the sequence length $k$. In contrast, we show how deeper models exploit the associativity of the task to dramatically improve this scaling: recurrent neural networks compose elements sequentially in $k$ steps, while multilayer networks compose adjacent pairs in parallel in $\log k$ layers. Overall, the sequential group composition task offers a tractable window into the mechanics of deep learning.
Alternating Gradient Flows: A Theory of Feature Learning in Two-layer Neural Networks
Jun 06, 2025What features neural networks learn, and how, remains an open question. In this paper, we introduce Alternating Gradient Flows (AGF), an algorithmic framework that describes the dynamics of feature learning in two-layer networks trained from small initialization. Prior works have shown that gradient flow in this regime exhibits a staircase-like loss curve, alternating between plateaus where neurons slowly align to useful directions and sharp drops where neurons rapidly grow in norm. AGF approximates this behavior as an alternating two-step process: maximizing a utility function over dormant neurons and minimizing a cost function over active ones. AGF begins with all neurons dormant. At each round, a dormant neuron activates, triggering the acquisition of a feature and a drop in the loss. AGF quantifies the order, timing, and magnitude of these drops, matching experiments across architectures. We show that AGF unifies and extends existing saddle-to-saddle analyses in fully connected linear networks and attention-only linear transformers, where the learned features are singular modes and principal components, respectively. In diagonal linear networks, we prove AGF converges to gradient flow in the limit of vanishing initialization. Applying AGF to quadratic networks trained to perform modular addition, we give the first complete characterization of the training dynamics, revealing that networks learn Fourier features in decreasing order of coefficient magnitude. Altogether, AGF offers a promising step towards understanding feature learning in neural networks.
Unsupervised cell segmentation by fast Gaussian Processes
May 24, 2025Cell boundary information is crucial for analyzing cell behaviors from time-lapse microscopy videos. Existing supervised cell segmentation tools, such as ImageJ, require tuning various parameters and rely on restrictive assumptions about the shape of the objects. While recent supervised segmentation tools based on convolutional neural networks enhance accuracy, they depend on high-quality labelled images, making them unsuitable for segmenting new types of objects not in the database. We developed a novel unsupervised cell segmentation algorithm based on fast Gaussian processes for noisy microscopy images without the need for parameter tuning or restrictive assumptions about the shape of the object. We derived robust thresholding criteria adaptive for heterogeneous images containing distinct brightness at different parts to separate objects from the background, and employed watershed segmentation to distinguish touching cell objects. Both simulated studies and real-data analysis of large microscopy images demonstrate the scalability and accuracy of our approach compared with the alternatives.
HOPSE: Scalable Higher-Order Positional and Structural Encoder for Combinatorial Representations
May 21, 2025While Graph Neural Networks (GNNs) have proven highly effective at modeling relational data, pairwise connections cannot fully capture multi-way relationships naturally present in complex real-world systems. In response to this, Topological Deep Learning (TDL) leverages more general combinatorial representations -- such as simplicial or cellular complexes -- to accommodate higher-order interactions. Existing TDL methods often extend GNNs through Higher-Order Message Passing (HOMP), but face critical \emph{scalability challenges} due to \textit{(i)} a combinatorial explosion of message-passing routes, and \textit{(ii)} significant complexity overhead from the propagation mechanism. To overcome these limitations, we propose HOPSE (Higher-Order Positional and Structural Encoder) -- a \emph{message passing-free} framework that uses Hasse graph decompositions to derive efficient and expressive encodings over \emph{arbitrary higher-order domains}. Notably, HOPSE scales linearly with dataset size while preserving expressive power and permutation equivariance. Experiments on molecular, expressivity and topological benchmarks show that HOPSE matches or surpasses state-of-the-art performance while achieving up to 7 $times$ speedups over HOMP-based models, opening a new path for scalable TDL.
Ordered Topological Deep Learning: a Network Modeling Case Study
Mar 20, 2025



Computer networks are the foundation of modern digital infrastructure, facilitating global communication and data exchange. As demand for reliable high-bandwidth connectivity grows, advanced network modeling techniques become increasingly essential to optimize performance and predict network behavior. Traditional modeling methods, such as packet-level simulators and queueing theory, have notable limitations --either being computationally expensive or relying on restrictive assumptions that reduce accuracy. In this context, the deep learning-based RouteNet family of models has recently redefined network modeling by showing an unprecedented cost-performance trade-off. In this work, we revisit RouteNet's sophisticated design and uncover its hidden connection to Topological Deep Learning (TDL), an emerging field that models higher-order interactions beyond standard graph-based methods. We demonstrate that, although originally formulated as a heterogeneous Graph Neural Network, RouteNet serves as the first instantiation of a new form of TDL. More specifically, this paper presents OrdGCCN, a novel TDL framework that introduces the notion of ordered neighbors in arbitrary discrete topological spaces, and shows that RouteNet's architecture can be naturally described as an ordered topological neural network. To the best of our knowledge, this marks the first successful real-world application of state-of-the-art TDL principles --which we confirm through extensive testbed experiments--, laying the foundation for the next generation of ordered TDL-driven applications.
From superposition to sparse codes: interpretable representations in neural networks
Mar 03, 2025Understanding how information is represented in neural networks is a fundamental challenge in both neuroscience and artificial intelligence. Despite their nonlinear architectures, recent evidence suggests that neural networks encode features in superposition, meaning that input concepts are linearly overlaid within the network's representations. We present a perspective that explains this phenomenon and provides a foundation for extracting interpretable representations from neural activations. Our theoretical framework consists of three steps: (1) Identifiability theory shows that neural networks trained for classification recover latent features up to a linear transformation. (2) Sparse coding methods can extract disentangled features from these representations by leveraging principles from compressed sensing. (3) Quantitative interpretability metrics provide a means to assess the success of these methods, ensuring that extracted features align with human-interpretable concepts. By bridging insights from theoretical neuroscience, representation learning, and interpretability research, we propose an emerging perspective on understanding neural representations in both artificial and biological systems. Our arguments have implications for neural coding theories, AI transparency, and the broader goal of making deep learning models more interpretable.
When Machine Learning Gets Personal: Understanding Fairness of Personalized Models
Feb 05, 2025



Personalization in machine learning involves tailoring models to individual users by incorporating personal attributes such as demographic or medical data. While personalization can improve prediction accuracy, it may also amplify biases and reduce explainability. This work introduces a unified framework to evaluate the impact of personalization on both prediction accuracy and explanation quality across classification and regression tasks. We derive novel upper bounds for the number of personal attributes that can be used to reliably validate benefits of personalization. Our analysis uncovers key trade-offs. We show that regression models can potentially utilize more personal attributes than classification models. We also demonstrate that improvements in prediction accuracy due to personalization do not necessarily translate to enhanced explainability -- underpinning the importance to evaluate both metrics when personalizing machine learning models in critical settings such as healthcare. Validated with a real-world dataset, this framework offers practical guidance for balancing accuracy, fairness, and interpretability in personalized models.
TopoTune : A Framework for Generalized Combinatorial Complex Neural Networks
Oct 09, 2024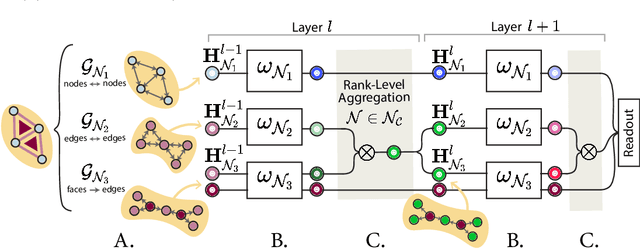
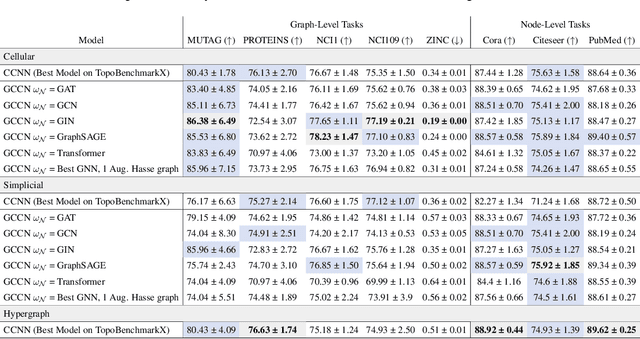
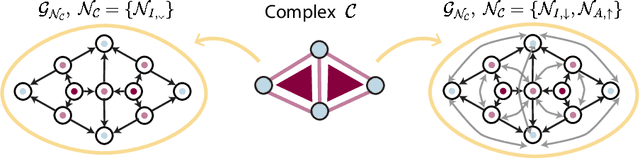
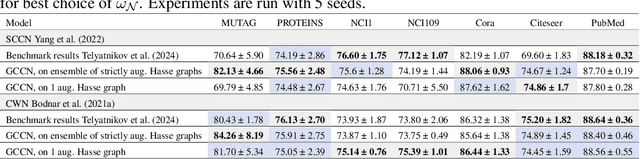
Graph Neural Networks (GNNs) excel in learning from relational datasets, processing node and edge features in a way that preserves the symmetries of the graph domain. However, many complex systems--such as biological or social networks--involve multiway complex interactions that are more naturally represented by higher-order topological spaces. The emerging field of Topological Deep Learning (TDL) aims to accommodate and leverage these higher-order structures. Combinatorial Complex Neural Networks (CCNNs), fairly general TDL models, have been shown to be more expressive and better performing than GNNs. However, differently from the graph deep learning ecosystem, TDL lacks a principled and standardized framework for easily defining new architectures, restricting its accessibility and applicability. To address this issue, we introduce Generalized CCNNs (GCCNs), a novel simple yet powerful family of TDL models that can be used to systematically transform any (graph) neural network into its TDL counterpart. We prove that GCCNs generalize and subsume CCNNs, while extensive experiments on a diverse class of GCCNs show that these architectures consistently match or outperform CCNNs, often with less model complexity. In an effort to accelerate and democratize TDL, we introduce TopoTune, a lightweight software that allows practitioners to define, build, and train GCCNs with unprecedented flexibility and ease.
ICML Topological Deep Learning Challenge 2024: Beyond the Graph Domain
Sep 08, 2024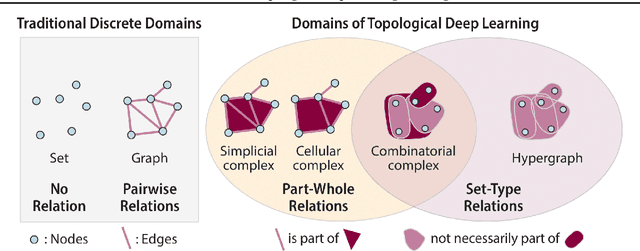
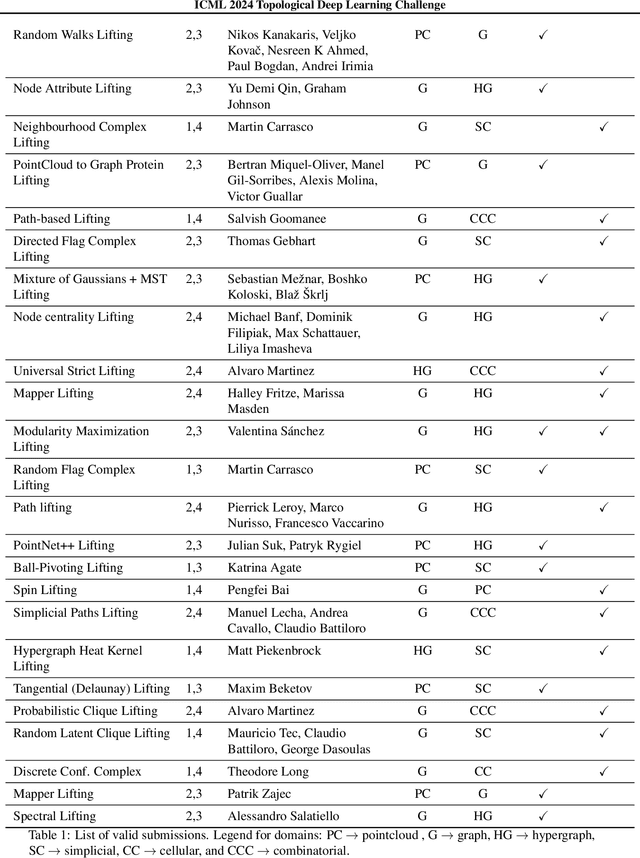
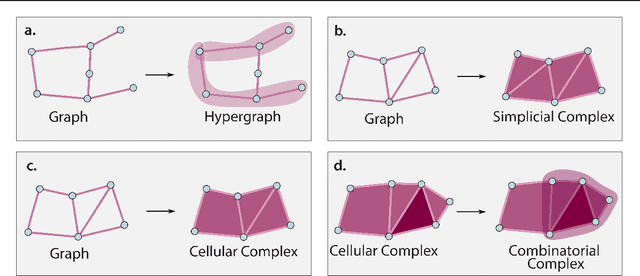
This paper describes the 2nd edition of the ICML Topological Deep Learning Challenge that was hosted within the ICML 2024 ELLIS Workshop on Geometry-grounded Representation Learning and Generative Modeling (GRaM). The challenge focused on the problem of representing data in different discrete topological domains in order to bridge the gap between Topological Deep Learning (TDL) and other types of structured datasets (e.g. point clouds, graphs). Specifically, participants were asked to design and implement topological liftings, i.e. mappings between different data structures and topological domains --like hypergraphs, or simplicial/cell/combinatorial complexes. The challenge received 52 submissions satisfying all the requirements. This paper introduces the main scope of the challenge, and summarizes the main results and findings.
Beyond Euclid: An Illustrated Guide to Modern Machine Learning with Geometric, Topological, and Algebraic Structures
Jul 12, 2024



The enduring legacy of Euclidean geometry underpins classical machine learning, which, for decades, has been primarily developed for data lying in Euclidean space. Yet, modern machine learning increasingly encounters richly structured data that is inherently nonEuclidean. This data can exhibit intricate geometric, topological and algebraic structure: from the geometry of the curvature of space-time, to topologically complex interactions between neurons in the brain, to the algebraic transformations describing symmetries of physical systems. Extracting knowledge from such non-Euclidean data necessitates a broader mathematical perspective. Echoing the 19th-century revolutions that gave rise to non-Euclidean geometry, an emerging line of research is redefining modern machine learning with non-Euclidean structures. Its goal: generalizing classical methods to unconventional data types with geometry, topology, and algebra. In this review, we provide an accessible gateway to this fast-growing field and propose a graphical taxonomy that integrates recent advances into an intuitive unified framework. We subsequently extract insights into current challenges and highlight exciting opportunities for future development in this field.