 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Guards the Guardians? The Challenges of Evaluating Identifiability of Learned Representations
Feb 27, 2026Identifiability in representation learning is commonly evaluated using standard metrics (e.g., MCC, DCI, R^2) on synthetic benchmarks with known ground-truth factors. These metrics are assumed to reflect recovery up to the equivalence class guaranteed by identifiability theory. We show that this assumption holds only under specific structural conditions: each metric implicitly encodes assumptions about both the data-generating process (DGP) and the encoder. When these assumptions are violated, metrics become misspecified and can produce systematic false positives and false negatives. Such failures occur both within classical identifiability regimes and in post-hoc settings where identifiability is most needed. We introduce a taxonomy separating DGP assumptions from encoder geometry, use it to characterise the validity domains of existing metrics, and release an evaluation suite for reproducible stress testing and comparison.
Causality is Key for Interpretability Claims to Generalise
Feb 18, 2026Interpretability research on large language models (LLMs) has yielded important insights into model behaviour, yet recurring pitfalls persist: findings that do not generalise, and causal interpretations that outrun the evidence. Our position is that causal inference specifies what constitutes a valid mapping from model activations to invariant high-level structures, the data or assumptions needed to achieve it, and the inferences it can support. Specifically, Pearl's causal hierarchy clarifies what an interpretability study can justify. Observations establish associations between model behaviour and internal components. Interventions (e.g., ablations or activation patching) support claims how these edits affect a behavioural metric (\eg, average change in token probabilities) over a set of prompts. However, counterfactual claims -- i.e., asking what the model output would have been for the same prompt under an unobserved intervention -- remain largely unverifiable without controlled supervision. We show how causal representation learning (CRL) operationalises this hierarchy, specifying which variables are recoverable from activations and under what assumptions. Together, these motivate a diagnostic framework that helps practitioners select methods and evaluations matching claims to evidence such that findings generalise.
From Isolation to Entanglement: When Do Interpretability Methods Identify and Disentangle Known Concepts?
Dec 17, 2025A central goal of interpretability is to recover representations of causally relevant concepts from the activations of neural networks. The quality of these concept representations is typically evaluated in isolation, and under implicit independence assumptions that may not hold in practice. Thus, it is unclear whether common featurization methods - including sparse autoencoders (SAEs) and sparse probes - recover disentangled representations of these concepts. This study proposes a multi-concept evaluation setting where we control the correlations between textual concepts, such as sentiment, domain, and tense, and analyze performance under increasing correlations between them. We first evaluate the extent to which featurizers can learn disentangled representations of each concept under increasing correlational strengths. We observe a one-to-many relationship from concepts to features: features correspond to no more than one concept, but concepts are distributed across many features. Then, we perform steering experiments, measuring whether each concept is independently manipulable. Even when trained on uniform distributions of concepts, SAE features generally affect many concepts when steered, indicating that they are neither selective nor independent; nonetheless, features affect disjoint subspaces. These results suggest that correlational metrics for measuring disentanglement are generally not sufficient for establishing independence when steering, and that affecting disjoint subspaces is not sufficient for concept selectivity. These results underscore the importance of compositional evaluations in interpretability research.
Out-of-distribution Tests Reveal Compositionality in Chess Transformers
Oct 23, 2025Chess is a canonical example of a task that requires rigorous reasoning and long-term planning. Modern decision Transformers - trained similarly to LLMs - are able to learn competent gameplay, but it is unclear to what extent they truly capture the rules of chess. To investigate this, we train a 270M parameter chess Transformer and test it on out-of-distribution scenarios, designed to reveal failures of systematic generalization. Our analysis shows that Transformers exhibit compositional generalization, as evidenced by strong rule extrapolation: they adhere to fundamental syntactic rules of the game by consistently choosing valid moves even in situations very different from the training data. Moreover, they also generate high-quality moves for OOD puzzles. In a more challenging test, we evaluate the models on variants including Chess960 (Fischer Random Chess) - a variant of chess where starting positions of pieces are randomized. We found that while the model exhibits basic strategy adaptation, they are inferior to symbolic AI algorithms that perform explicit search, but gap is smaller when playing against users on Lichess. Moreover, the training dynamics revealed that the model initially learns to move only its own pieces, suggesting an emergent compositional understanding of the game.
Estimating Treatment Effects with Independent Component Analysis
Jul 22, 2025The field of causal inference has developed a variety of methods to accurately estimate treatment effects in the presence of nuisance. Meanwhile, the field of identifiability theory has developed methods like Independent Component Analysis (ICA) to identify latent sources and mixing weights from data. While these two research communities have developed largely independently, they aim to achieve similar goals: the accurate and sample-efficient estimation of model parameters. In the partially linear regression (PLR) setting, Mackey et al. (2018) recently found that estimation consistency can be improved with non-Gaussian treatment noise. Non-Gaussianity is also a crucial assumption for identifying latent factors in ICA. We provide the first theoretical and empirical insights into this connection, showing that ICA can be used for causal effect estimation in the PLR model. Surprisingly, we find that linear ICA can accurately estimate multiple treatment effects even in the presence of Gaussian confounders or nonlinear nuisance.
An Empirically Grounded Identifiability Theory Will Accelerate Self-Supervised Learning Research
Apr 17, 2025
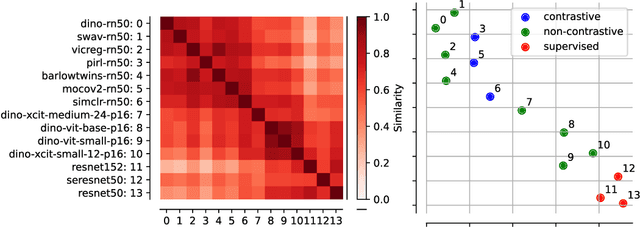
Self-Supervised Learning (SSL) powers many current AI systems. As research interest and investment grow, the SSL design space continues to expand. The Platonic view of SSL, following the Platonic Representation Hypothesis (PRH), suggests that despite different methods and engineering approaches, all representations converge to the same Platonic ideal. However, this phenomenon lacks precise theoretical explanation. By synthesizing evidence from Identifiability Theory (IT), we show that the PRH can emerge in SSL. However, current IT cannot explain SSL's empirical success. To bridge the gap between theory and practice, we propose expanding IT into what we term Singular Identifiability Theory (SITh), a broader theoretical framework encompassing the entire SSL pipeline. SITh would allow deeper insights into the implicit data assumptions in SSL and advance the field towards learning more interpretable and generalizable representations. We highlight three critical directions for future research: 1) training dynamics and convergence properties of SSL; 2) the impact of finite samples, batch size, and data diversity; and 3) the role of inductive biases in architecture, augmentations, initialization schemes, and optimizers.
From superposition to sparse codes: interpretable representations in neural networks
Mar 03, 2025Understanding how information is represented in neural networks is a fundamental challenge in both neuroscience and artificial intelligence. Despite their nonlinear architectures, recent evidence suggests that neural networks encode features in superposition, meaning that input concepts are linearly overlaid within the network's representations. We present a perspective that explains this phenomenon and provides a foundation for extracting interpretable representations from neural activations. Our theoretical framework consists of three steps: (1) Identifiability theory shows that neural networks trained for classification recover latent features up to a linear transformation. (2) Sparse coding methods can extract disentangled features from these representations by leveraging principles from compressed sensing. (3) Quantitative interpretability metrics provide a means to assess the success of these methods, ensuring that extracted features align with human-interpretable concepts. By bridging insights from theoretical neuroscience, representation learning, and interpretability research, we propose an emerging perspective on understanding neural representations in both artificial and biological systems. Our arguments have implications for neural coding theories, AI transparency, and the broader goal of making deep learning models more interpretable.
Cross-Entropy Is All You Need To Invert the Data Generating Process
Oct 29, 2024



Supervised learning has become a cornerstone of modern machine learning, yet a comprehensive theory explaining its effectiveness remains elusive. Empirical phenomena, such as neural analogy-making and the linear representation hypothesis, suggest that supervised models can learn interpretable factors of variation in a linear fashion. Recent advances in self-supervised learning, particularly nonlinear Independent Component Analysis, have shown that these methods can recover latent structures by inverting the data generating process. We extend these identifiability results to parametric instance discrimination, then show how insights transfer to the ubiquitous setting of supervised learning with cross-entropy minimization. We prove that even in standard classification tasks, models learn representations of ground-truth factors of variation up to a linear transformation. We corroborate our theoretical contribution with a series of empirical studies. First, using simulated data matching our theoretical assumptions, we demonstrate successful disentanglement of latent factors. Second, we show that on DisLib, a widely-used disentanglement benchmark, simple classification tasks recover latent structures up to linear transformations. Finally, we reveal that models trained on ImageNet encode representations that permit linear decoding of proxy factors of variation. Together, our theoretical findings and experiments offer a compelling explanation for recent observations of linear representations, such as superposition in neural networks. This work takes a significant step toward a cohesive theory that accounts for the unreasonable effectiveness of supervised deep learning.
InfoNCE: Identifying the Gap Between Theory and Practice
Jun 28, 2024Previous theoretical work on contrastive learning (CL) with InfoNCE showed that, under certain assumptions, the learned representations uncover the ground-truth latent factors. We argue these theories overlook crucial aspects of how CL is deployed in practice. Specifically, they assume that within a positive pair, all latent factors either vary to a similar extent, or that some do not vary at all. However, in practice, positive pairs are often generated using augmentations such as strong cropping to just a few pixels. Hence, a more realistic assumption is that all latent factors change, with a continuum of variability across these factors. We introduce AnInfoNCE, a generalization of InfoNCE that can provably uncover the latent factors in this anisotropic setting, broadly generalizing previous identifiability results in CL. We validate our identifiability results in controlled experiments and show that AnInfoNCE increases the recovery of previously collapsed information in CIFAR10 and ImageNet, albeit at the cost of downstream accuracy. Additionally, we explore and discuss further mismatches between theoretical assumptions and practical implementations, including extensions to hard negative mining and loss ensembles.
Identifiable Exchangeable Mechanisms for Causal Structure and Representation Learning
Jun 20, 2024



Identifying latent representations or causal structures is important for good generalization and downstream task performance. However, both fields have been developed rather independently. We observe that several methods in both representation and causal structure learning rely on the same data-generating process (DGP), namely, exchangeable but not i.i.d. (independent and identically distributed) data. We provide a unified framework, termed Identifiable Exchangeable Mechanisms (IEM), for representation and structure learning under the lens of exchangeability. IEM provides new insights that let us relax the necessary conditions for causal structure identification in exchangeable non--i.i.d. data. We also demonstrate the existence of a duality condition in identifiable representation learning, leading to new identifiability results. We hope this work will pave the way for further research in causal representation learning.