 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-distribution Tests Reveal Compositionality in Chess Transformers
Oct 23, 2025Chess is a canonical example of a task that requires rigorous reasoning and long-term planning. Modern decision Transformers - trained similarly to LLMs - are able to learn competent gameplay, but it is unclear to what extent they truly capture the rules of chess. To investigate this, we train a 270M parameter chess Transformer and test it on out-of-distribution scenarios, designed to reveal failures of systematic generalization. Our analysis shows that Transformers exhibit compositional generalization, as evidenced by strong rule extrapolation: they adhere to fundamental syntactic rules of the game by consistently choosing valid moves even in situations very different from the training data. Moreover, they also generate high-quality moves for OOD puzzles. In a more challenging test, we evaluate the models on variants including Chess960 (Fischer Random Chess) - a variant of chess where starting positions of pieces are randomized. We found that while the model exhibits basic strategy adaptation, they are inferior to symbolic AI algorithms that perform explicit search, but gap is smaller when playing against users on Lichess. Moreover, the training dynamics revealed that the model initially learns to move only its own pieces, suggesting an emergent compositional understanding of the game.
Beyond the Boundaries of Proximal Policy Optimization
Nov 01, 2024
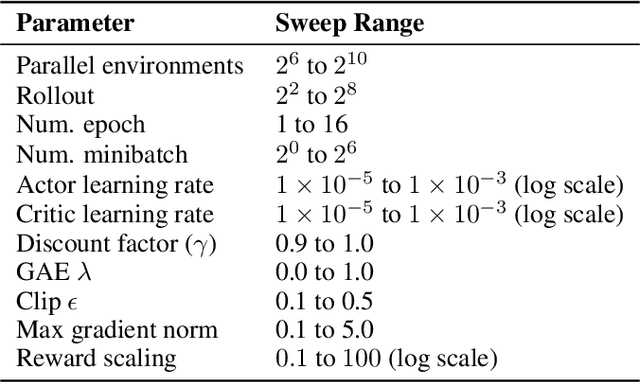
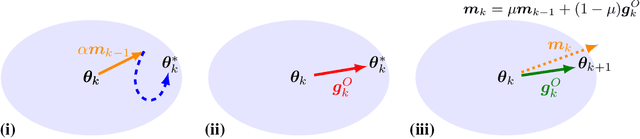

Proximal policy optimization (PPO) is a widely-used algorithm for on-policy reinforcement learning. This work offers an alternative perspective of PPO, in which it is decomposed into the inner-loop estimation of update vectors, and the outer-loop application of updates using gradient ascent with unity learning rate. Using this insight we propose outer proximal policy optimization (outer-PPO); a framework wherein these update vectors are applied using an arbitrary gradient-based optimizer. The decoupling of update estimation and update application enabled by outer-PPO highlights several implicit design choices in PPO that we challenge through empirical investigation. In particular we consider non-unity learning rates and momentum applied to the outer loop, and a momentum-bias applied to the inner estimation loop. Methods are evaluated against an aggressively tuned PPO baseline on Brax, Jumanji and MinAtar environments; non-unity learning rates and momentum both achieve statistically significant improvement on Brax and Jumanji, given the same hyperparameter tuning budget.
Identifiable Exchangeable Mechanisms for Causal Structure and Representation Learning
Jun 20, 2024



Identifying latent representations or causal structures is important for good generalization and downstream task performance. However, both fields have been developed rather independently. We observe that several methods in both representation and causal structure learning rely on the same data-generating process (DGP), namely, exchangeable but not i.i.d. (independent and identically distributed) data. We provide a unified framework, termed Identifiable Exchangeable Mechanisms (IEM), for representation and structure learning under the lens of exchangeability. IEM provides new insights that let us relax the necessary conditions for causal structure identification in exchangeable non--i.i.d. data. We also demonstrate the existence of a duality condition in identifiable representation learning, leading to new identifiability results. We hope this work will pave the way for further research in causal representation learning.
Do Finetti: On Causal Effects for Exchangeable Data
May 29, 2024


We study causal effect estimation in a setting where the data are not i.i.d. (independent and identically distributed). We focus on exchangeable data satisfying an assumption of independent causal mechanisms. Traditional causal effect estimation frameworks, e.g., relying on structural causal models and do-calculus, are typically limited to i.i.d. data and do not extend to more general exchangeable generative processes, which naturally arise in multi-environment data. To address this gap, we develop a generalized framework for exchangeable data and introduce a truncated factorization formula that facilitates both the identification and estimation of causal effects in our setting. To illustrate potential applications, we introduce a causal P\'olya urn model and demonstrate how intervention propagates effects in exchangeable data settings. Finally, we develop an algorithm that performs simultaneous causal discovery and effect estimation given multi-environment data.
Learning Beyond Pattern Matching? Assaying Mathematical Understanding in LLMs
May 24, 2024We are beginning to see progress in language model assisted scientific discovery. Motivated by the use of LLMs as a general scientific assistant, this paper assesses the domain knowledge of LLMs through its understanding of different mathematical skills required to solve problems. In particular, we look at not just what the pre-trained model already knows, but how it learned to learn from information during in-context learning or instruction-tuning through exploiting the complex knowledge structure within mathematics. Motivated by the Neural Tangent Kernel (NTK), we propose \textit{NTKEval} to assess changes in LLM's probability distribution via training on different kinds of math data. Our systematic analysis finds evidence of domain understanding during in-context learning. By contrast, certain instruction-tuning leads to similar performance changes irrespective of training on different data, suggesting a lack of domain understanding across different skills.
Recurrent Early Exits for Federated Learning with Heterogeneous Clients
May 23, 2024Federated learning (FL) has enabled distributed learning of a model across multiple clients in a privacy-preserving manner. One of the main challenges of FL is to accommodate clients with varying hardware capacities; clients have differing compute and memory requirements. To tackle this challenge, recent state-of-the-art approaches leverage the use of early exits. Nonetheless, these approaches fall short of mitigating the challenges of joint learning multiple exit classifiers, often relying on hand-picked heuristic solutions for knowledge distillation among classifiers and/or utilizing additional layers for weaker classifiers. In this work, instead of utilizing multiple classifiers, we propose a recurrent early exit approach named ReeFL that fuses features from different sub-models into a single shared classifier. Specifically, we use a transformer-based early-exit module shared among sub-models to i) better exploit multi-layer feature representations for task-specific prediction and ii) modulate the feature representation of the backbone model for subsequent predictions. We additionally present a per-client self-distillation approach where the best sub-model is automatically selected as the teacher of the other sub-models at each client. Our experiments on standard image and speech classification benchmarks across various emerging federated fine-tuning baselines demonstrate ReeFL's effectiveness over previous works.
Understanding LLMs Requires More Than Statistical Generalization
May 03, 2024The last decade has seen blossoming research in deep learning theory attempting to answer, "Why does deep learning generalize?" A powerful shift in perspective precipitated this progress: the study of overparametrized models in the interpolation regime. In this paper, we argue that another perspective shift is due, since some of the desirable qualities of LLMs are not a consequence of good statistical generalization and require a separate theoretical explanation. Our core argument relies on the observation that AR probabilistic models are inherently non-identifiable: models zero or near-zero KL divergence apart -- thus, equivalent test loss -- can exhibit markedly different behaviors. We support our position with mathematical examples and empirical observations, illustrating why non-identifiability has practical relevance through three case studies: (1) the non-identifiability of zero-shot rule extrapolation; (2) the approximate non-identifiability of in-context learning; and (3) the non-identifiability of fine-tunability. We review promising research directions focusing on LLM-relevant generalization measures, transferability, and inductive biases.
FedL2P: Federated Learning to Personalize
Oct 03, 2023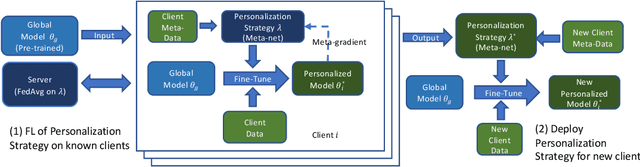
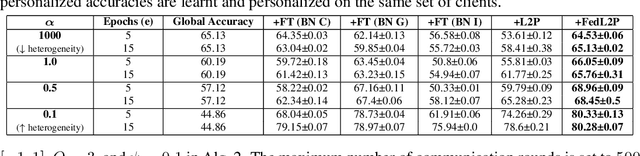
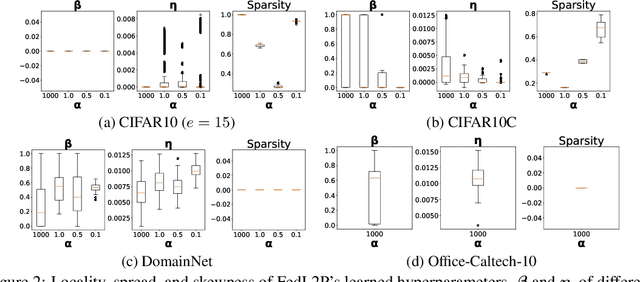
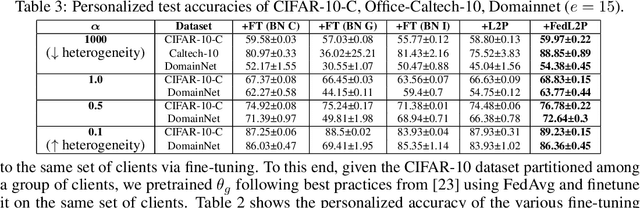
Federated learning (FL) research has made progress in developing algorithms for distributed learning of global models, as well as algorithms for local personalization of those common models to the specifics of each client's local data distribution. However, different FL problems may require different personalization strategies, and it may not even be possible to define an effective one-size-fits-all personalization strategy for all clients: depending on how similar each client's optimal predictor is to that of the global model, different personalization strategies may be preferred. In this paper, we consider the federated meta-learning problem of learning personalization strategies. Specifically, we consider meta-nets that induce the batch-norm and learning rate parameters for each client given local data statistics. By learning these meta-nets through FL, we allow the whole FL network to collaborate in learning a customized personalization strategy for each client. Empirical results show that this framework improves on a range of standard hand-crafted personalization baselines in both label and feature shift situations.
Meta-Learned Kernel For Blind Super-Resolution Kernel Estimation
Dec 15, 2022



Recent image degradation estimation methods have enabled single-image super-resolution (SR) approaches to better upsample real-world images. Among these methods, explicit kernel estimation approaches have demonstrated unprecedented performance at handling unknown degradations. Nonetheless, a number of limitations constrain their efficacy when used by downstream SR models. Specifically, this family of methods yields i) excessive inference time due to long per-image adaptation times and ii) inferior image fidelity due to kernel mismatch. In this work, we introduce a learning-to-learn approach that meta-learns from the information contained in a distribution of images, thereby enabling significantly faster adaptation to new images with substantially improved performance in both kernel estimation and image fidelity. Specifically, we meta-train a kernel-generating GAN, named MetaKernelGAN, on a range of tasks, such that when a new image is presented, the generator starts from an informed kernel estimate and the discriminator starts with a strong capability to distinguish between patch distributions. Compared with state-of-the-art methods, our experiments show that MetaKernelGAN better estimates the magnitude and covariance of the kernel, leading to state-of-the-art blind SR results within a similar computational regime when combined with a non-blind SR model. Through supervised learning of an unsupervised learner, our method maintains the generalizability of the unsupervised learner, improves the optimization stability of kernel estimation, and hence image adaptation, and leads to a faster inference with a speedup between 14.24 to 102.1x over existing methods.
Rethinking Sharpness-Aware Minimization as Variational Inference
Oct 19, 2022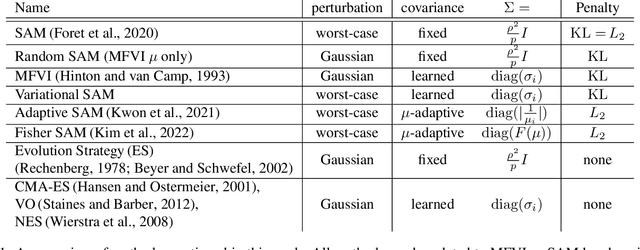
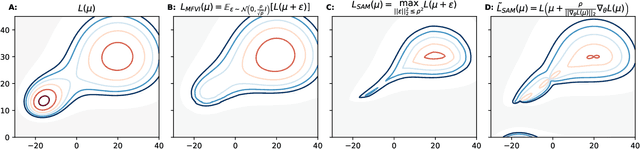
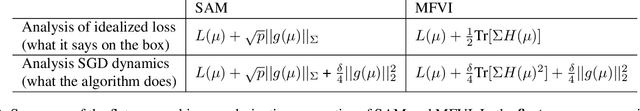
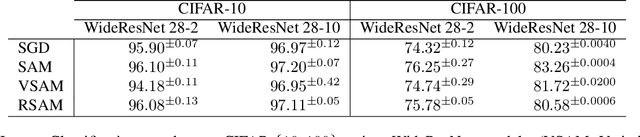
Sharpness-aware minimization (SAM) aims to improve the generalisation of gradient-based learning by seeking out flat minima. In this work, we establish connections between SAM and Mean-Field Variational Inference (MFVI) of neural network parameters. We show that both these methods have interpretations as optimizing notions of flatness, and when using the reparametrisation trick, they both boil down to calculating the gradient at a perturbed version of the current mean parameter. This thinking motivates our study of algorithms that combine or interpolate between SAM and MFVI. We evaluate the proposed variational algorithms on several benchmark datasets, and compare their performance to variants of SAM. Taking a broader perspective, our work suggests that SAM-like updates can be used as a drop-in replacement for the reparametrisation trick.