 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculative Decoding with a Speculative Vocabulary
Feb 14, 2026Speculative decoding has rapidly emerged as a leading approach for accelerating language model (LM) inference, as it offers substantial speedups while yielding identical outputs. This relies upon a small draft model, tasked with predicting the outputs of the target model. State-of-the-art speculative decoding methods use a draft model consisting of a single decoder layer and output embedding matrix, with the latter dominating drafting time for the latest LMs. Recent work has sought to address this output distribution bottleneck by reducing the vocabulary of the draft model. Although this can improve throughput, it compromises speculation effectiveness when the target token is out-of-vocabulary. In this paper, we argue for vocabulary speculation as an alternative to a reduced vocabulary. We propose SpecVocab, an efficient and effective method that selects a vocabulary subset per decoding step. Across a variety of tasks, we demonstrate that SpecVocab can achieve a higher acceptance length than state-of-the-art speculative decoding approach, EAGLE-3. Notably, this yields up to an 8.1% increase in average throughput over EAGLE-3.
HierarchicalPrune: Position-Aware Compression for Large-Scale Diffusion Models
Aug 06, 2025State-of-the-art text-to-image diffusion models (DMs) achieve remarkable quality, yet their massive parameter scale (8-11B) poses significant challenges for inferences on resource-constrained devices. In this paper, we present HierarchicalPrune, a novel compression framework grounded in a key observation: DM blocks exhibit distinct functional hierarchies, where early blocks establish semantic structures while later blocks handle texture refinements. HierarchicalPrune synergistically combines three techniques: (1) Hierarchical Position Pruning, which identifies and removes less essential later blocks based on position hierarchy; (2) Positional Weight Preservation, which systematically protects early model portions that are essential for semantic structural integrity; and (3) Sensitivity-Guided Distillation, which adjusts knowledge-transfer intensity based on our discovery of block-wise sensitivity variations. As a result, our framework brings billion-scale diffusion models into a range more suitable for on-device inference, while preserving the quality of the output images. Specifically, when combined with INT4 weight quantisation, HierarchicalPrune achieves 77.5-80.4% memory footprint reduction (e.g., from 15.8 GB to 3.2 GB) and 27.9-38.0% latency reduction, measured on server and consumer grade GPUs, with the minimum drop of 2.6% in GenEval score and 7% in HPSv2 score compared to the original model. Last but not least, our comprehensive user study with 85 participants demonstrates that HierarchicalPrune maintains perceptual quality comparable to the original model while significantly outperforming prior works.
FedP$^2$EFT: Federated Learning to Personalize Parameter Efficient Fine-Tuning for Multilingual LLMs
Feb 05, 2025



Federated learning (FL) has enabled the training of multilingual large language models (LLMs) on diverse and decentralized multilingual data, especially on low-resource languages. To improve client-specific performance, personalization via the use of parameter-efficient fine-tuning (PEFT) modules such as LoRA is common. This involves a personalization strategy (PS), such as the design of the PEFT adapter structures (e.g., in which layers to add LoRAs and what ranks) and choice of hyperparameters (e.g., learning rates) for fine-tuning. Instead of manual PS configuration, we propose FedP$^2$EFT, a federated learning-to-personalize method for multilingual LLMs in cross-device FL settings. Unlike most existing PEFT structure selection methods, which are prone to overfitting low-data regimes, FedP$^2$EFT collaboratively learns the optimal personalized PEFT structure for each client via Bayesian sparse rank selection. Evaluations on both simulated and real-world multilingual FL benchmarks demonstrate that FedP$^2$EFT largely outperforms existing personalized fine-tuning methods, while complementing a range of existing FL methods.
MultiTASC++: A Continuously Adaptive Scheduler for Edge-Based Multi-Device Cascade Inference
Dec 05, 2024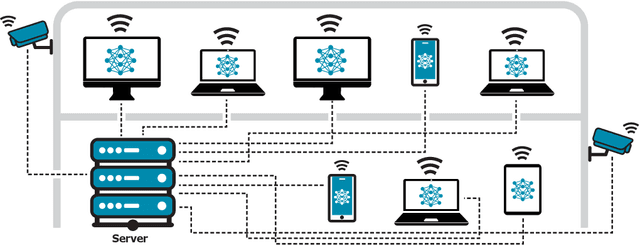
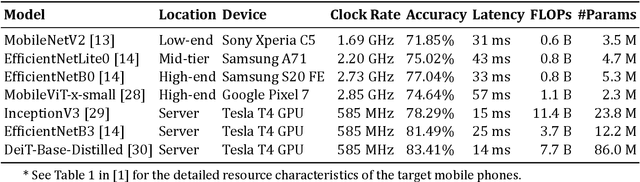
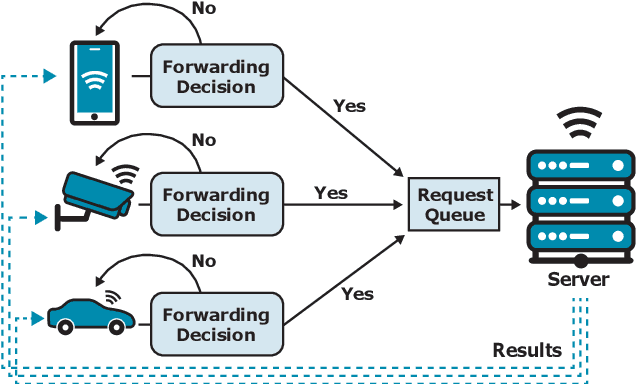
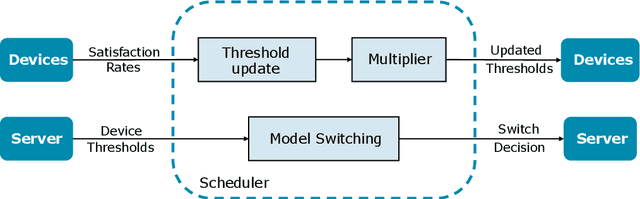
Cascade systems, consisting of a lightweight model processing all samples and a heavier, high-accuracy model refining challenging samples, have become a widely-adopted distributed inference approach to achieving high accuracy and maintaining a low computational burden for mobile and IoT devices. As intelligent indoor environments, like smart homes, continue to expand, a new scenario emerges, the multi-device cascade. In this setting, multiple diverse devices simultaneously utilize a shared heavy model hosted on a server, often situated within or close to the consumer environment. This work introduces MultiTASC++, a continuously adaptive multi-tenancy-aware scheduler that dynamically controls the forwarding decision functions of devices to optimize system throughput while maintaining high accuracy and low latency. Through extensive experimentation in diverse device environments and with varying server-side models, we demonstrate the scheduler's efficacy in consistently maintaining a targeted satisfaction rate while providing the highest available accuracy across different device tiers and workloads of up to 100 devices. This demonstrates its scalability and efficiency in addressing the unique challenges of collaborative DNN inference in dynamic and diverse IoT environments.
Progressive Mixed-Precision Decoding for Efficient LLM Inference
Oct 17, 2024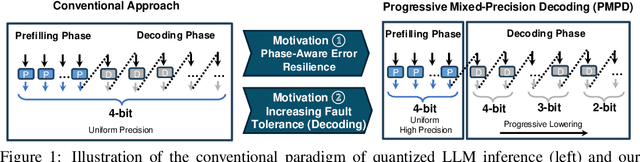
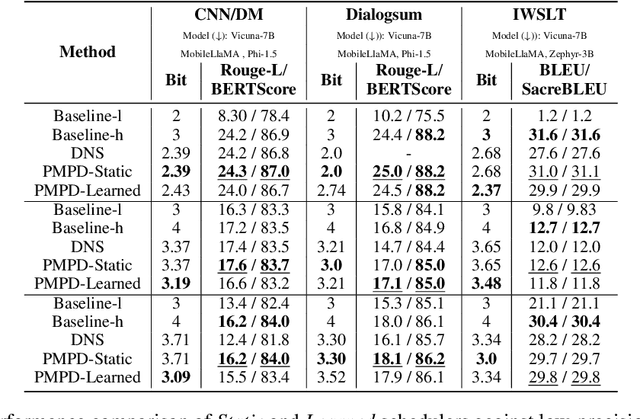
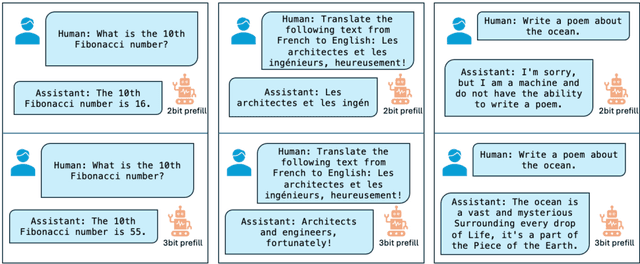
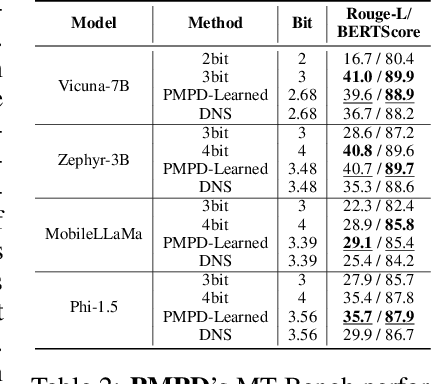
In spite of the great potential of large language models (LLMs) across various tasks, their deployment on resource-constrained devices remains challenging due to their excessive computational and memory demands. Quantization has emerged as an effective solution by storing weights in reduced precision. However, utilizing low precisions (i.e.~2/3-bit) to substantially alleviate the memory-boundedness of LLM decoding, still suffers from prohibitive performance drop. In this work, we argue that existing approaches fail to explore the diversity in computational patterns, redundancy, and sensitivity to approximations of the different phases of LLM inference, resorting to a uniform quantization policy throughout. Instead, we propose a novel phase-aware method that selectively allocates precision during different phases of LLM inference, achieving both strong context extraction during prefill and efficient memory bandwidth utilization during decoding. To further address the memory-boundedness of the decoding phase, we introduce Progressive Mixed-Precision Decoding (PMPD), a technique that enables the gradual lowering of precision deeper in the generated sequence, together with a spectrum of precision-switching schedulers that dynamically drive the precision-lowering decisions in either task-adaptive or prompt-adaptive manner. Extensive evaluation across diverse language tasks shows that when targeting Nvidia GPUs, PMPD achieves 1.4$-$12.2$\times$ speedup in matrix-vector multiplications over fp16 models, while when targeting an LLM-optimized NPU, our approach delivers a throughput gain of 3.8$-$8.0$\times$ over fp16 models and up to 1.54$\times$ over uniform quantization approaches while preserving the output quality.
CARIn: Constraint-Aware and Responsive Inference on Heterogeneous Devices for Single- and Multi-DNN Workloads
Sep 02, 2024


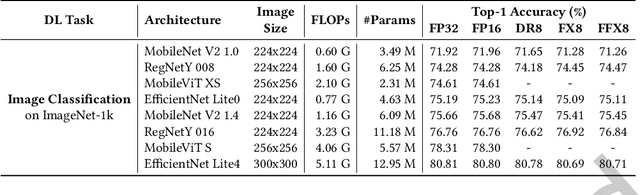
The relentless expansion of deep learning applications in recent years has prompted a pivotal shift toward on-device execution, driven by the urgent need for real-time processing, heightened privacy concerns, and reduced latency across diverse domains. This article addresses the challenges inherent in optimising the execution of deep neural networks (DNNs) on mobile devices, with a focus on device heterogeneity, multi-DNN execution, and dynamic runtime adaptation. We introduce CARIn, a novel framework designed for the optimised deployment of both single- and multi-DNN applications under user-defined service-level objectives. Leveraging an expressive multi-objective optimisation framework and a runtime-aware sorting and search algorithm (RASS) as the MOO solver, CARIn facilitates efficient adaptation to dynamic conditions while addressing resource contention issues associated with multi-DNN execution. Notably, RASS generates a set of configurations, anticipating subsequent runtime adaptation, ensuring rapid, low-overhead adjustments in response to environmental fluctuations. Extensive evaluation across diverse tasks, including text classification, scene recognition, and face analysis, showcases the versatility of CARIn across various model architectures, such as Convolutional Neural Networks and Transformers, and realistic use cases. We observe a substantial enhancement in the fair treatment of the problem's objectives, reaching 1.92x when compared to single-model designs and up to 10.69x in contrast to the state-of-the-art OODIn framework. Additionally, we achieve a significant gain of up to 4.06x over hardware-unaware designs in multi-DNN applications. Finally, our framework sustains its performance while effectively eliminating the time overhead associated with identifying the optimal design in response to environmental challenges.
Hardware-Aware Parallel Prompt Decoding for Memory-Efficient Acceleration of LLM Inference
May 28, 2024



The auto-regressive decoding of Large Language Models (LLMs) results in significant overheads in their hardware performance. While recent research has investigated various speculative decoding techniques for multi-token generation, these efforts have primarily focused on improving processing speed such as throughput. Crucially, they often neglect other metrics essential for real-life deployments, such as memory consumption and training cost. To overcome these limitations, we propose a novel parallel prompt decoding that requires only $0.0002$% trainable parameters, enabling efficient training on a single A100-40GB GPU in just 16 hours. Inspired by the human natural language generation process, $PPD$ approximates outputs generated at future timesteps in parallel by using multiple prompt tokens. This approach partially recovers the missing conditional dependency information necessary for multi-token generation, resulting in up to a 28% higher acceptance rate for long-range predictions. Furthermore, we present a hardware-aware dynamic sparse tree technique that adaptively optimizes this decoding scheme to fully leverage the computational capacities on different GPUs. Through extensive experiments across LLMs ranging from MobileLlama to Vicuna-13B on a wide range of benchmarks, our approach demonstrates up to 2.49$\times$ speedup and maintains a minimal runtime memory overhead of just $0.0004$%. More importantly, our parallel prompt decoding can serve as an orthogonal optimization for synergistic integration with existing speculative decoding, showing up to $1.22\times$ further speed improvement. Our code is available at https://github.com/hmarkc/parallel-prompt-decoding.
LifeLearner: Hardware-Aware Meta Continual Learning System for Embedded Computing Platforms
Nov 19, 2023Continual Learning (CL) allows applications such as user personalization and household robots to learn on the fly and adapt to context. This is an important feature when context, actions, and users change. However, enabling CL on resource-constrained embedded systems is challenging due to the limited labeled data, memory, and computing capacity. In this paper, we propose LifeLearner, a hardware-aware meta continual learning system that drastically optimizes system resources (lower memory, latency, energy consumption) while ensuring high accuracy. Specifically, we (1) exploit meta-learning and rehearsal strategies to explicitly cope with data scarcity issues and ensure high accuracy, (2) effectively combine lossless and lossy compression to significantly reduce the resource requirements of CL and rehearsal samples, and (3) developed hardware-aware system on embedded and IoT platforms considering the hardware characteristics. As a result, LifeLearner achieves near-optimal CL performance, falling short by only 2.8% on accuracy compared to an Oracle baseline. With respect to the state-of-the-art (SOTA) Meta CL method, LifeLearner drastically reduces the memory footprint (by 178.7x), end-to-end latency by 80.8-94.2%, and energy consumption by 80.9-94.2%. In addition, we successfully deployed LifeLearner on two edge devices and a microcontroller unit, thereby enabling efficient CL on resource-constrained platforms where it would be impractical to run SOTA methods and the far-reaching deployment of adaptable CL in a ubiquitous manner. Code is available at https://github.com/theyoungkwon/LifeLearner.
Sparse-DySta: Sparsity-Aware Dynamic and Static Scheduling for Sparse Multi-DNN Workloads
Oct 17, 2023Running multiple deep neural networks (DNNs) in parallel has become an emerging workload in both edge devices, such as mobile phones where multiple tasks serve a single user for daily activities, and data centers, where various requests are raised from millions of users, as seen with large language models. To reduce the costly computational and memory requirements of these workloads, various efficient sparsification approaches have been introduced, resulting in widespread sparsity across different types of DNN models. In this context, there is an emerging need for scheduling sparse multi-DNN workloads, a problem that is largely unexplored in previous literature. This paper systematically analyses the use-cases of multiple sparse DNNs and investigates the opportunities for optimizations. Based on these findings, we propose Dysta, a novel bi-level dynamic and static scheduler that utilizes both static sparsity patterns and dynamic sparsity information for the sparse multi-DNN scheduling. Both static and dynamic components of Dysta are jointly designed at the software and hardware levels, respectively, to improve and refine the scheduling approach. To facilitate future progress in the study of this class of workloads, we construct a public benchmark that contains sparse multi-DNN workloads across different deployment scenarios, spanning from mobile phones and AR/VR wearables to data centers. A comprehensive evaluation on the sparse multi-DNN benchmark demonstrates that our proposed approach outperforms the state-of-the-art methods with up to 10% decrease in latency constraint violation rate and nearly 4X reduction in average normalized turnaround time. Our artifacts and code are publicly available at: https://github.com/SamsungLabs/Sparse-Multi-DNN-Scheduling.
Mitigating Memory Wall Effects in CNN Engines with On-the-Fly Weights Generation
Jul 25, 2023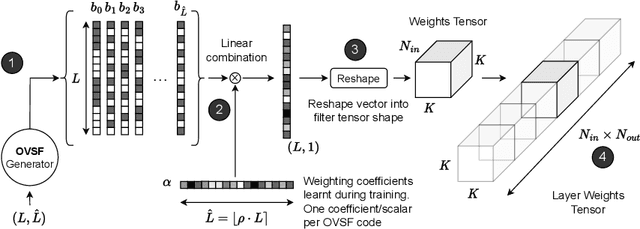

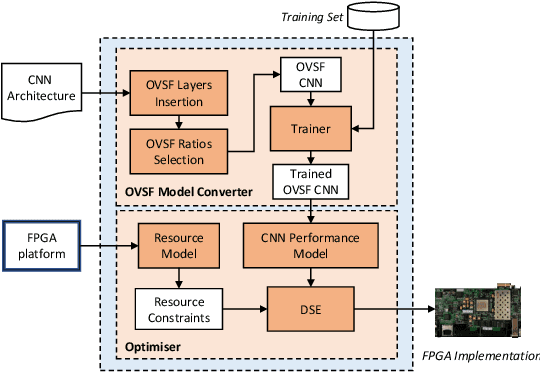

The unprecedented accuracy of convolutional neural networks (CNNs) across a broad range of AI tasks has led to their widespread deployment in mobile and embedded settings. In a pursuit for high-performance and energy-efficient inference, significant research effort has been invested in the design of FPGA-based CNN accelerators. In this context, single computation engines constitute a popular approach to support diverse CNN modes without the overhead of fabric reconfiguration. Nevertheless, this flexibility often comes with significantly degraded performance on memory-bound layers and resource underutilisation due to the suboptimal mapping of certain layers on the engine's fixed configuration. In this work, we investigate the implications in terms of CNN engine design for a class of models that introduce a pre-convolution stage to decompress the weights at run time. We refer to these approaches as on-the-fly. This paper presents unzipFPGA, a novel CNN inference system that counteracts the limitations of existing CNN engines. The proposed framework comprises a novel CNN hardware architecture that introduces a weights generator module that enables the on-chip on-the-fly generation of weights, alleviating the negative impact of limited bandwidth on memory-bound layers. We further enhance unzipFPGA with an automated hardware-aware methodology that tailors the weights generation mechanism to the target CNN-device pair, leading to an improved accuracy-performance balance. Finally, we introduce an input selective processing element (PE) design that balances the load between PEs in suboptimally mapped layers. The proposed framework yields hardware designs that achieve an average of 2.57x performance efficiency gain over highly optimised GPU designs for the same power constraints and up to 3.94x higher performance density over a diverse range of state-of-the-art FPGA-based CNN accelerators.