 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculative Decoding with a Speculative Vocabulary
Feb 14, 2026Speculative decoding has rapidly emerged as a leading approach for accelerating language model (LM) inference, as it offers substantial speedups while yielding identical outputs. This relies upon a small draft model, tasked with predicting the outputs of the target model. State-of-the-art speculative decoding methods use a draft model consisting of a single decoder layer and output embedding matrix, with the latter dominating drafting time for the latest LMs. Recent work has sought to address this output distribution bottleneck by reducing the vocabulary of the draft model. Although this can improve throughput, it compromises speculation effectiveness when the target token is out-of-vocabulary. In this paper, we argue for vocabulary speculation as an alternative to a reduced vocabulary. We propose SpecVocab, an efficient and effective method that selects a vocabulary subset per decoding step. Across a variety of tasks, we demonstrate that SpecVocab can achieve a higher acceptance length than state-of-the-art speculative decoding approach, EAGLE-3. Notably, this yields up to an 8.1% increase in average throughput over EAGLE-3.
Tempora: Characterising the Time-Contingent Utility of Online Test-Time Adaptation
Feb 05, 2026Test-time adaptation (TTA) offers a compelling remedy for machine learning (ML) models that degrade under domain shifts, improving generalisation on-the-fly with only unlabelled samples. This flexibility suits real deployments, yet conventional evaluations unrealistically assume unbounded processing time, overlooking the accuracy-latency trade-off. As ML increasingly underpins latency-sensitive and user-facing use-cases, temporal pressure constrains the viability of adaptable inference; predictions arriving too late to act on are futile. We introduce Tempora, a framework for evaluating TTA under this pressure. It consists of temporal scenarios that model deployment constraints, evaluation protocols that operationalise measurement, and time-contingent utility metrics that quantify the accuracy-latency trade-off. We instantiate the framework with three such metrics: (1) discrete utility for asynchronous streams with hard deadlines, (2) continuous utility for interactive settings where value decays with latency, and (3) amortised utility for budget-constrained deployments. Applying Tempora to seven TTA methods on ImageNet-C across 240 temporal evaluations reveals rank instability: conventional rankings do not predict rankings under temporal pressure; ETA, a state-of-the-art method in the conventional setting, falls short in 41.2% of evaluations. The highest-utility method varies with corruption type and temporal pressure, with no clear winner. By enabling systematic evaluation across diverse temporal constraints for the first time, Tempora reveals when and why rankings invert, offering practitioners a lens for method selection and researchers a target for deployable adaptation.
HierarchicalPrune: Position-Aware Compression for Large-Scale Diffusion Models
Aug 06, 2025State-of-the-art text-to-image diffusion models (DMs) achieve remarkable quality, yet their massive parameter scale (8-11B) poses significant challenges for inferences on resource-constrained devices. In this paper, we present HierarchicalPrune, a novel compression framework grounded in a key observation: DM blocks exhibit distinct functional hierarchies, where early blocks establish semantic structures while later blocks handle texture refinements. HierarchicalPrune synergistically combines three techniques: (1) Hierarchical Position Pruning, which identifies and removes less essential later blocks based on position hierarchy; (2) Positional Weight Preservation, which systematically protects early model portions that are essential for semantic structural integrity; and (3) Sensitivity-Guided Distillation, which adjusts knowledge-transfer intensity based on our discovery of block-wise sensitivity variations. As a result, our framework brings billion-scale diffusion models into a range more suitable for on-device inference, while preserving the quality of the output images. Specifically, when combined with INT4 weight quantisation, HierarchicalPrune achieves 77.5-80.4% memory footprint reduction (e.g., from 15.8 GB to 3.2 GB) and 27.9-38.0% latency reduction, measured on server and consumer grade GPUs, with the minimum drop of 2.6% in GenEval score and 7% in HPSv2 score compared to the original model. Last but not least, our comprehensive user study with 85 participants demonstrates that HierarchicalPrune maintains perceptual quality comparable to the original model while significantly outperforming prior works.
On-demand Test-time Adaptation for Edge Devices
May 02, 2025Continual Test-time adaptation (CTTA) continuously adapts the deployed model on every incoming batch of data. While achieving optimal accuracy, existing CTTA approaches present poor real-world applicability on resource-constrained edge devices, due to the substantial memory overhead and energy consumption. In this work, we first introduce a novel paradigm -- on-demand TTA -- which triggers adaptation only when a significant domain shift is detected. Then, we present OD-TTA, an on-demand TTA framework for accurate and efficient adaptation on edge devices. OD-TTA comprises three innovative techniques: 1) a lightweight domain shift detection mechanism to activate TTA only when it is needed, drastically reducing the overall computation overhead, 2) a source domain selection module that chooses an appropriate source model for adaptation, ensuring high and robust accuracy, 3) a decoupled Batch Normalization (BN) update scheme to enable memory-efficient adaptation with small batch sizes. Extensive experiments show that OD-TTA achieves comparable and even better performance while reducing the energy and computation overhead remarkably, making TTA a practical reality.
MetaCLBench: Meta Continual Learning Benchmark on Resource-Constrained Edge Devices
Mar 31, 2025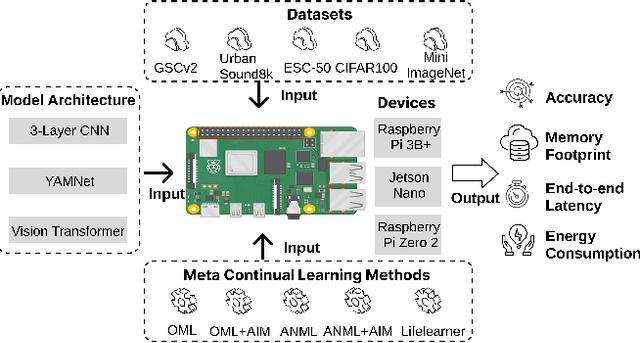
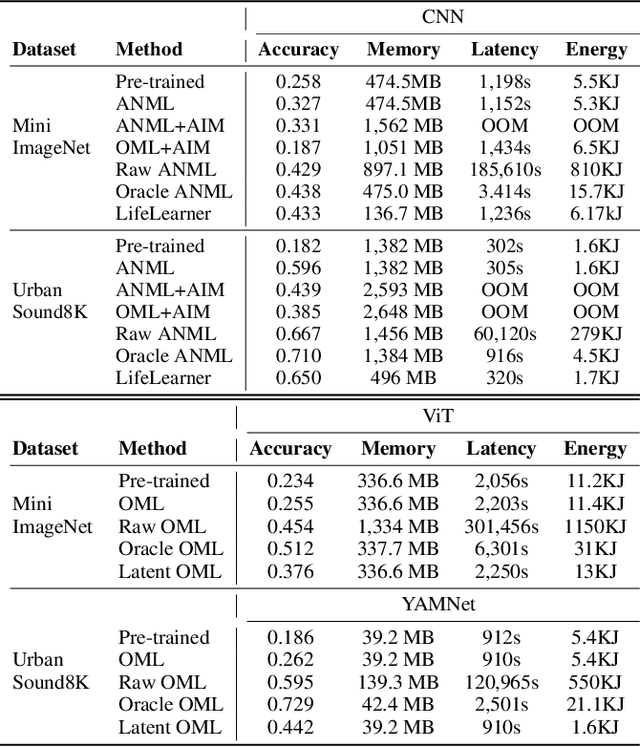
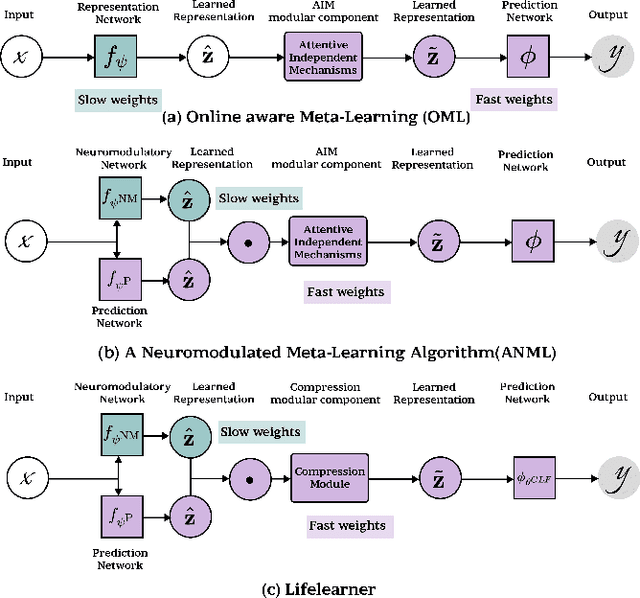
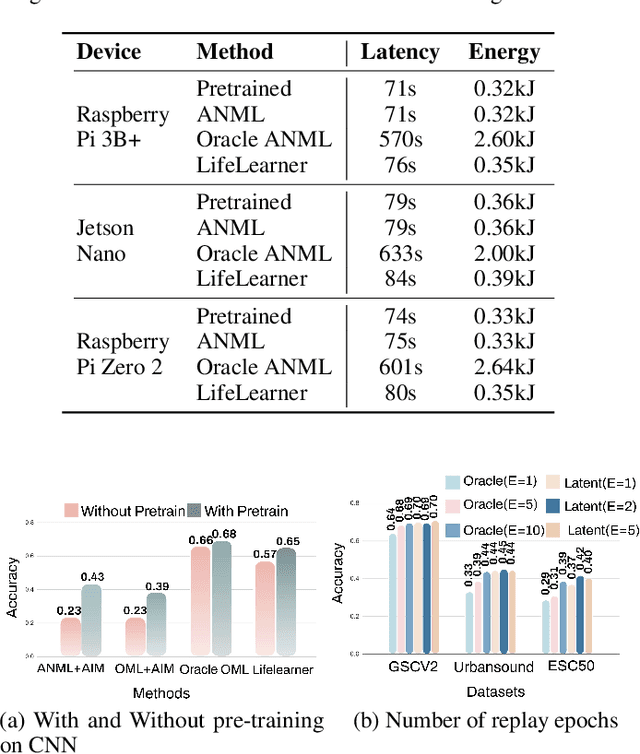
Meta-Continual Learning (Meta-CL) has emerged as a promising approach to minimize manual labeling efforts and system resource requirements by enabling Continual Learning (CL) with limited labeled samples. However, while existing methods have shown success in image-based tasks, their effectiveness remains unexplored for sequential time-series data from sensor systems, particularly audio inputs. To address this gap, we conduct a comprehensive benchmark study evaluating six representative Meta-CL approaches using three network architectures on five datasets from both image and audio modalities. We develop MetaCLBench, an end-to-end Meta-CL benchmark framework for edge devices to evaluate system overheads and investigate trade-offs among performance, computational costs, and memory requirements across various Meta-CL methods. Our results reveal that while many Meta-CL methods enable to learn new classes for both image and audio modalities, they impose significant computational and memory costs on edge devices. Also, we find that pre-training and meta-training procedures based on source data before deployment improve Meta-CL performance. Finally, to facilitate further research, we provide practical guidelines for researchers and machine learning practitioners implementing Meta-CL on resource-constrained environments and make our benchmark framework and tools publicly available, enabling fair evaluation across both accuracy and system-level metrics.
LeanTTA: A Backpropagation-Free and Stateless Approach to Quantized Test-Time Adaptation on Edge Devices
Mar 20, 2025While there are many advantages to deploying machine learning models on edge devices, the resource constraints of mobile platforms, the dynamic nature of the environment, and differences between the distribution of training versus in-the-wild data make such deployments challenging. Current test-time adaptation methods are often memory-intensive and not designed to be quantization-compatible or deployed on low-resource devices. To address these challenges, we present LeanTTA, a novel backpropagation-free and stateless framework for quantized test-time adaptation tailored to edge devices. Our approach minimizes computational costs by dynamically updating normalization statistics without backpropagation, which frees LeanTTA from the common pitfall of relying on large batches and historical data, making our method robust to realistic deployment scenarios. Our approach is the first to enable further computational gains by combining partial adaptation with quantized module fusion. We validate our framework across sensor modalities, demonstrating significant improvements over state-of-the-art TTA methods, including a 15.7% error reduction, peak memory usage of only 11.2MB for ResNet18, and fast adaptation within an order-of-magnitude of normal inference speeds on-device. LeanTTA provides a robust solution for achieving the right trade offs between accuracy and system efficiency in edge deployments, addressing the unique challenges posed by limited data and varied operational conditions.
UR2M: Uncertainty and Resource-Aware Event Detection on Microcontrollers
Feb 17, 2024Traditional machine learning techniques are prone to generating inaccurate predictions when confronted with shifts in the distribution of data between the training and testing phases. This vulnerability can lead to severe consequences, especially in applications such as mobile healthcare. Uncertainty estimation has the potential to mitigate this issue by assessing the reliability of a model's output. However, existing uncertainty estimation techniques often require substantial computational resources and memory, making them impractical for implementation on microcontrollers (MCUs). This limitation hinders the feasibility of many important on-device wearable event detection (WED) applications, such as heart attack detection. In this paper, we present UR2M, a novel Uncertainty and Resource-aware event detection framework for MCUs. Specifically, we (i) develop an uncertainty-aware WED based on evidential theory for accurate event detection and reliable uncertainty estimation; (ii) introduce a cascade ML framework to achieve efficient model inference via early exits, by sharing shallower model layers among different event models; (iii) optimize the deployment of the model and MCU library for system efficiency. We conducted extensive experiments and compared UR2M to traditional uncertainty baselines using three wearable datasets. Our results demonstrate that UR2M achieves up to 864% faster inference speed, 857% energy-saving for uncertainty estimation, 55% memory saving on two popular MCUs, and a 22% improvement in uncertainty quantification performance. UR2M can be deployed on a wide range of MCUs, significantly expanding real-time and reliable WED applications.
LifeLearner: Hardware-Aware Meta Continual Learning System for Embedded Computing Platforms
Nov 19, 2023Continual Learning (CL) allows applications such as user personalization and household robots to learn on the fly and adapt to context. This is an important feature when context, actions, and users change. However, enabling CL on resource-constrained embedded systems is challenging due to the limited labeled data, memory, and computing capacity. In this paper, we propose LifeLearner, a hardware-aware meta continual learning system that drastically optimizes system resources (lower memory, latency, energy consumption) while ensuring high accuracy. Specifically, we (1) exploit meta-learning and rehearsal strategies to explicitly cope with data scarcity issues and ensure high accuracy, (2) effectively combine lossless and lossy compression to significantly reduce the resource requirements of CL and rehearsal samples, and (3) developed hardware-aware system on embedded and IoT platforms considering the hardware characteristics. As a result, LifeLearner achieves near-optimal CL performance, falling short by only 2.8% on accuracy compared to an Oracle baseline. With respect to the state-of-the-art (SOTA) Meta CL method, LifeLearner drastically reduces the memory footprint (by 178.7x), end-to-end latency by 80.8-94.2%, and energy consumption by 80.9-94.2%. In addition, we successfully deployed LifeLearner on two edge devices and a microcontroller unit, thereby enabling efficient CL on resource-constrained platforms where it would be impractical to run SOTA methods and the far-reaching deployment of adaptable CL in a ubiquitous manner. Code is available at https://github.com/theyoungkwon/LifeLearner.
TinyTrain: Deep Neural Network Training at the Extreme Edge
Jul 19, 2023
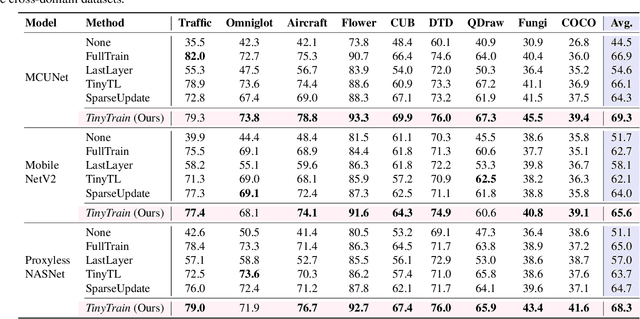
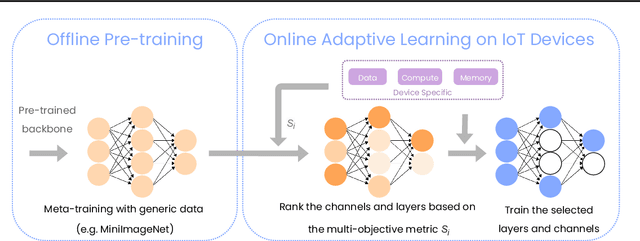
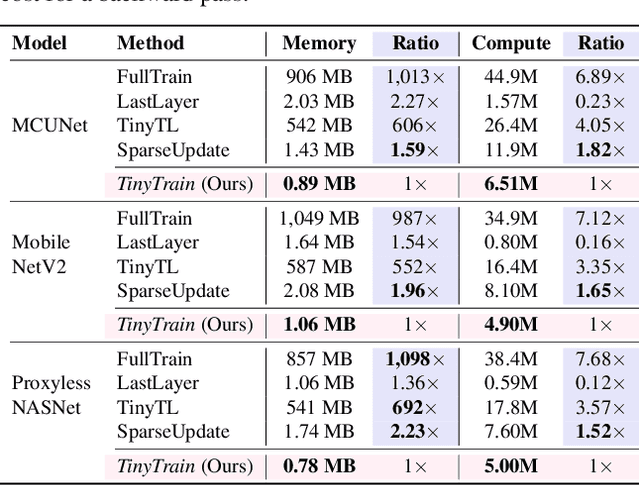
On-device training is essential for user personalisation and privacy. With the pervasiveness of IoT devices and microcontroller units (MCU), this task becomes more challenging due to the constrained memory and compute resources, and the limited availability of labelled user data. Nonetheless, prior works neglect the data scarcity issue, require excessively long training time (e.g. a few hours), or induce substantial accuracy loss ($\geq$10\%). We propose TinyTrain, an on-device training approach that drastically reduces training time by selectively updating parts of the model and explicitly coping with data scarcity. TinyTrain introduces a task-adaptive sparse-update method that dynamically selects the layer/channel based on a multi-objective criterion that jointly captures user data, the memory, and the compute capabilities of the target device, leading to high accuracy on unseen tasks with reduced computation and memory footprint. TinyTrain outperforms vanilla fine-tuning of the entire network by 3.6-5.0\% in accuracy, while reducing the backward-pass memory and computation cost by up to 2,286$\times$ and 7.68$\times$, respectively. Targeting broadly used real-world edge devices, TinyTrain achieves 9.5$\times$ faster and 3.5$\times$ more energy-efficient training over status-quo approaches, and 2.8$\times$ smaller memory footprint than SOTA approaches, while remaining within the 1 MB memory envelope of MCU-grade platforms.
HideNseek: Federated Lottery Ticket via Server-side Pruning and Sign Supermask
Jun 09, 2022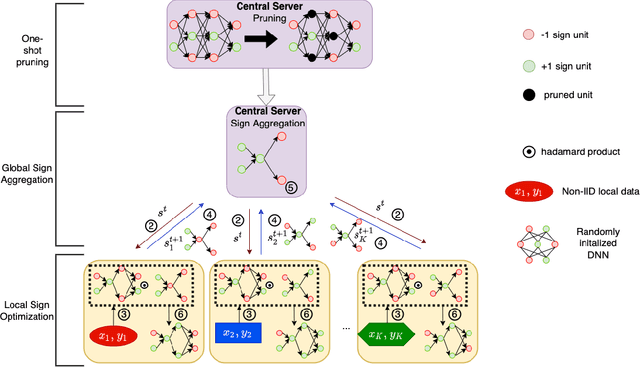

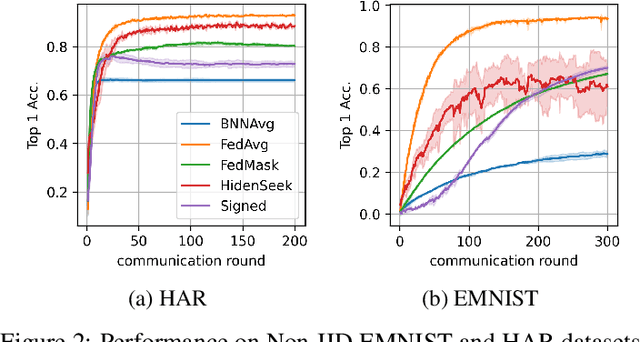
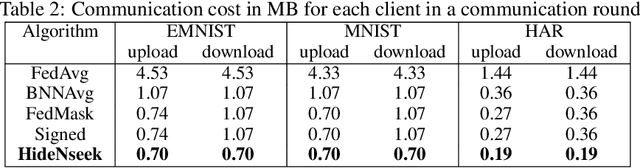
Federated learning alleviates the privacy risk in distributed learning by transmitting only the local model updates to the central server. However, it faces challenges including statistical heterogeneity of clients' datasets and resource constraints of client devices, which severely impact the training performance and user experience. Prior works have tackled these challenges by combining personalization with model compression schemes including quantization and pruning. However, the pruning is data-dependent and thus must be done on the client side which requires considerable computation cost. Moreover, the pruning normally trains a binary supermask $\in \{0, 1\}$ which significantly limits the model capacity yet with no computation benefit. Consequently, the training requires high computation cost and a long time to converge while the model performance does not pay off. In this work, we propose HideNseek which employs one-shot data-agnostic pruning at initialization to get a subnetwork based on weights' synaptic saliency. Each client then optimizes a sign supermask $\in \{-1, +1\}$ multiplied by the unpruned weights to allow faster convergence with the same compression rates as state-of-the-art. Empirical results from three datasets demonstrate that compared to state-of-the-art, HideNseek improves inferences accuracies by up to 40.6\% while reducing the communication cost and training time by up to 39.7\% and 46.8\% respectively.