 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Multi-modal (reasoning) LLMs work as deepfake detectors?
Mar 25, 2025Deepfake detection remains a critical challenge in the era of advanced generative models, particularly as synthetic media becomes more sophisticated. In this study, we explore the potential of state of the art multi-modal (reasoning) large language models (LLMs) for deepfake image detection such as (OpenAI O1/4o, Gemini thinking Flash 2, Deepseek Janus, Grok 3, llama 3.2, Qwen 2/2.5 VL, Mistral Pixtral, Claude 3.5/3.7 sonnet) . We benchmark 12 latest multi-modal LLMs against traditional deepfake detection methods across multiple datasets, including recently published real-world deepfake imagery. To enhance performance, we employ prompt tuning and conduct an in-depth analysis of the models' reasoning pathways to identify key contributing factors in their decision-making process. Our findings indicate that best multi-modal LLMs achieve competitive performance with promising generalization ability with zero shot, even surpass traditional deepfake detection pipelines in out-of-distribution datasets while the rest of the LLM families performs extremely disappointing with some worse than random guess. Furthermore, we found newer model version and reasoning capabilities does not contribute to performance in such niche tasks of deepfake detection while model size do help in some cases. This study highlights the potential of integrating multi-modal reasoning in future deepfake detection frameworks and provides insights into model interpretability for robustness in real-world scenarios.
Take History as a Mirror in Heterogeneous Federated Learning
Dec 16, 2023



Federated Learning (FL) allows several clients to cooperatively train machine learning models without disclosing the raw data. In practice, due to the system and statistical heterogeneity among devices, synchronous FL often encounters the straggler effect. In contrast, asynchronous FL can mitigate this problem, making it suitable for scenarios involving numerous participants. However, Non-IID data and stale models present significant challenges to asynchronous FL, as they would diminish the practicality of the global model and even lead to training failures. In this work, we propose a novel asynchronous FL framework called Federated Historical Learning (FedHist), which effectively addresses the challenges posed by both Non-IID data and gradient staleness. FedHist enhances the stability of local gradients by performing weighted fusion with historical global gradients cached on the server. Relying on hindsight, it assigns aggregation weights to each participant in a multi-dimensional manner during each communication round. To further enhance the efficiency and stability of the training process, we introduce an intelligent $\ell_2$-norm amplification scheme, which dynamically regulates the learning progress based on the $\ell_2$-norms of the submitted gradients. Extensive experiments demonstrate that FedHist outperforms state-of-the-art methods in terms of convergence performance and test accuracy.
Celeritas: Fast Optimizer for Large Dataflow Graphs
Jul 30, 2022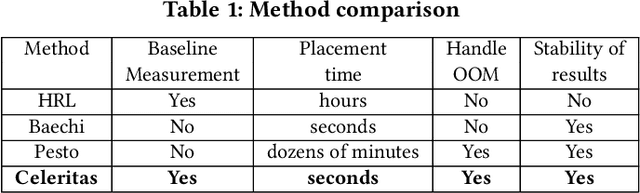
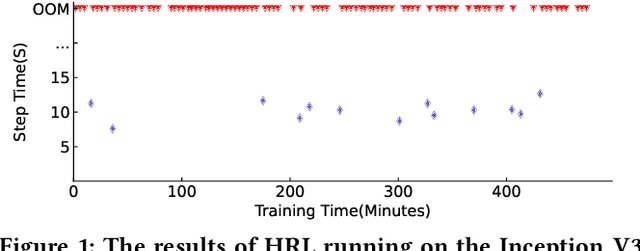
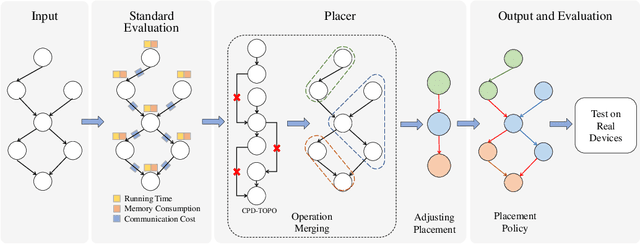
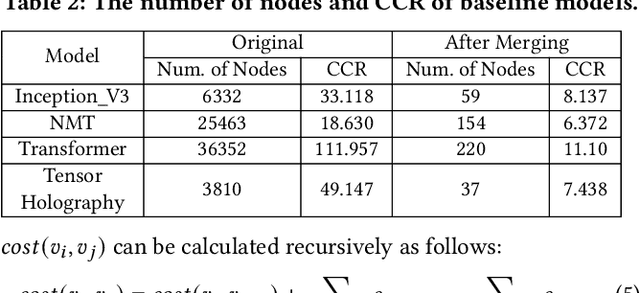
The rapidly enlarging neural network models are becoming increasingly challenging to run on a single device. Hence model parallelism over multiple devices is critical to guarantee the efficiency of training large models. Recent proposals fall short either in long processing time or poor performance. Therefore, we propose Celeritas, a fast framework for optimizing device placement for large models. Celeritas employs a simple but efficient model parallelization strategy in the Standard Evaluation, and generates placement policies through a series of scheduling algorithms. We conduct experiments to deploy and evaluate Celeritas on numerous large models. The results show that Celeritas not only reduces the placement policy generation time by 26.4\% but also improves the model running time by 34.2\% compared to most advanced methods.
HideNseek: Federated Lottery Ticket via Server-side Pruning and Sign Supermask
Jun 09, 2022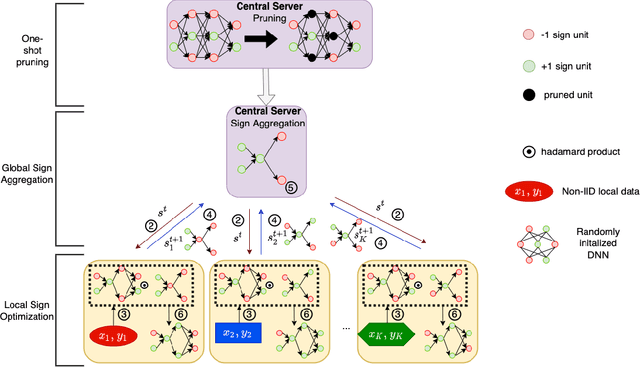

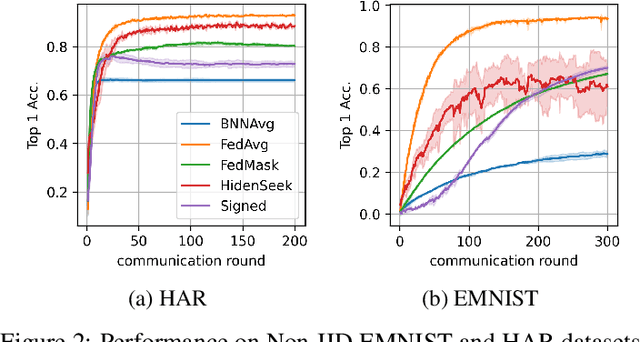
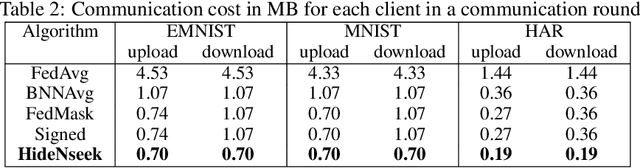
Federated learning alleviates the privacy risk in distributed learning by transmitting only the local model updates to the central server. However, it faces challenges including statistical heterogeneity of clients' datasets and resource constraints of client devices, which severely impact the training performance and user experience. Prior works have tackled these challenges by combining personalization with model compression schemes including quantization and pruning. However, the pruning is data-dependent and thus must be done on the client side which requires considerable computation cost. Moreover, the pruning normally trains a binary supermask $\in \{0, 1\}$ which significantly limits the model capacity yet with no computation benefit. Consequently, the training requires high computation cost and a long time to converge while the model performance does not pay off. In this work, we propose HideNseek which employs one-shot data-agnostic pruning at initialization to get a subnetwork based on weights' synaptic saliency. Each client then optimizes a sign supermask $\in \{-1, +1\}$ multiplied by the unpruned weights to allow faster convergence with the same compression rates as state-of-the-art. Empirical results from three datasets demonstrate that compared to state-of-the-art, HideNseek improves inferences accuracies by up to 40.6\% while reducing the communication cost and training time by up to 39.7\% and 46.8\% respectively.