 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHideNseek: Federated Lottery Ticket via Server-side Pruning and Sign Supermask
Paper and Code
Jun 09, 2022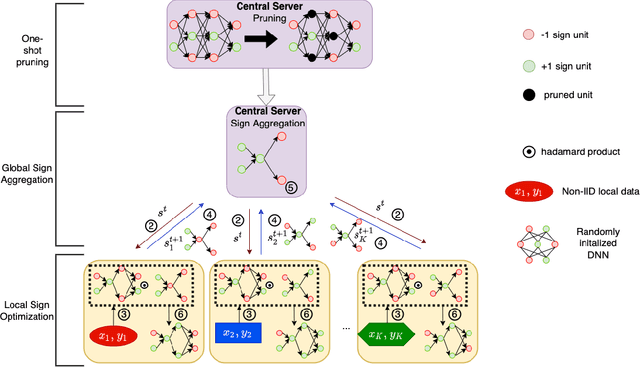

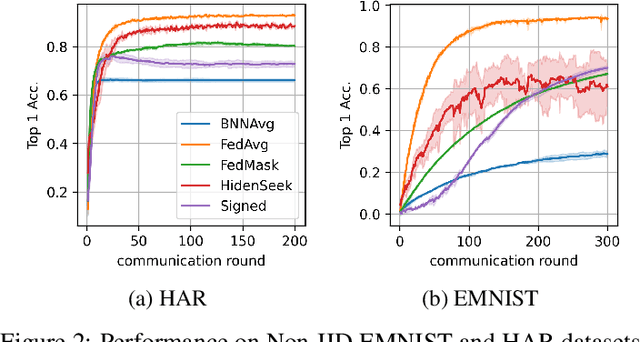
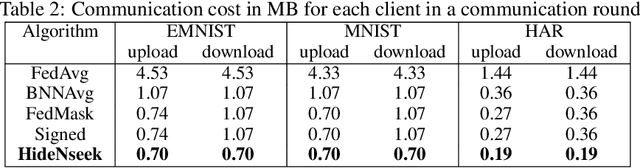
Federated learning alleviates the privacy risk in distributed learning by transmitting only the local model updates to the central server. However, it faces challenges including statistical heterogeneity of clients' datasets and resource constraints of client devices, which severely impact the training performance and user experience. Prior works have tackled these challenges by combining personalization with model compression schemes including quantization and pruning. However, the pruning is data-dependent and thus must be done on the client side which requires considerable computation cost. Moreover, the pruning normally trains a binary supermask $\in \{0, 1\}$ which significantly limits the model capacity yet with no computation benefit. Consequently, the training requires high computation cost and a long time to converge while the model performance does not pay off. In this work, we propose HideNseek which employs one-shot data-agnostic pruning at initialization to get a subnetwork based on weights' synaptic saliency. Each client then optimizes a sign supermask $\in \{-1, +1\}$ multiplied by the unpruned weights to allow faster convergence with the same compression rates as state-of-the-art. Empirical results from three datasets demonstrate that compared to state-of-the-art, HideNseek improves inferences accuracies by up to 40.6\% while reducing the communication cost and training time by up to 39.7\% and 46.8\% respectively.