 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSesaHand: Enhancing 3D Hand Reconstruction via Controllable Generation with Semantic and Structural Alignment
Feb 28, 2026Recent studies on 3D hand reconstruction have demonstrated the effectiveness of synthetic training data to improve estimation performance. However, most methods rely on game engines to synthesize hand images, which often lack diversity in textures and environments, and fail to include crucial components like arms or interacting objects. Generative models are promising alternatives to generate diverse hand images, but still suffer from misalignment issues. In this paper, we present SesaHand, which enhances controllable hand image generation from both semantic and structural alignment perspectives for 3D hand reconstruction. Specifically, for semantic alignment, we propose a pipeline with Chain-of-Thought inference to extract human behavior semantics from image captions generated by the Vision-Language Model. This semantics suppresses human-irrelevant environmental details and ensures sufficient human-centric contexts for hand image generation. For structural alignment, we introduce hierarchical structural fusion to integrate structural information with different granularity for feature refinement to better align the hand and the overall human body in generated images. We further propose a hand structure attention enhancement method to efficiently enhance the model's attention on hand regions. Experiments demonstrate that our method not only outperforms prior work in generation performance but also improves 3D hand reconstruction with the generated hand images.
CityRiSE: Reasoning Urban Socio-Economic Status in Vision-Language Models via Reinforcement Learning
Oct 25, 2025Harnessing publicly available, large-scale web data, such as street view and satellite imagery, urban socio-economic sensing is of paramount importance for achieving global sustainable development goals. With the emergence of Large Vision-Language Models (LVLMs), new opportunities have arisen to solve this task by treating it as a multi-modal perception and understanding problem. However, recent studies reveal that LVLMs still struggle with accurate and interpretable socio-economic predictions from visual data. To address these limitations and maximize the potential of LVLMs, we introduce \textbf{CityRiSE}, a novel framework for \textbf{R}eason\textbf{i}ng urban \textbf{S}ocio-\textbf{E}conomic status in LVLMs through pure reinforcement learning (RL). With carefully curated multi-modal data and verifiable reward design, our approach guides the LVLM to focus on semantically meaningful visual cues, enabling structured and goal-oriented reasoning for generalist socio-economic status prediction. Experiments demonstrate that CityRiSE with emergent reasoning process significantly outperforms existing baselines, improving both prediction accuracy and generalization across diverse urban contexts, particularly for prediction on unseen cities and unseen indicators. This work highlights the promise of combining RL and LVLMs for interpretable and generalist urban socio-economic sensing.
Hollywood Town: Long-Video Generation via Cross-Modal Multi-Agent Orchestration
Oct 25, 2025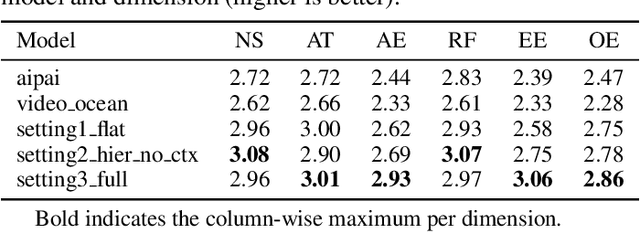
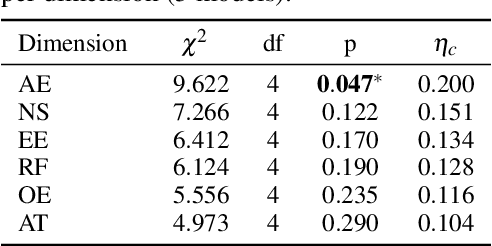
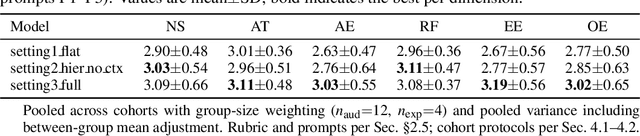
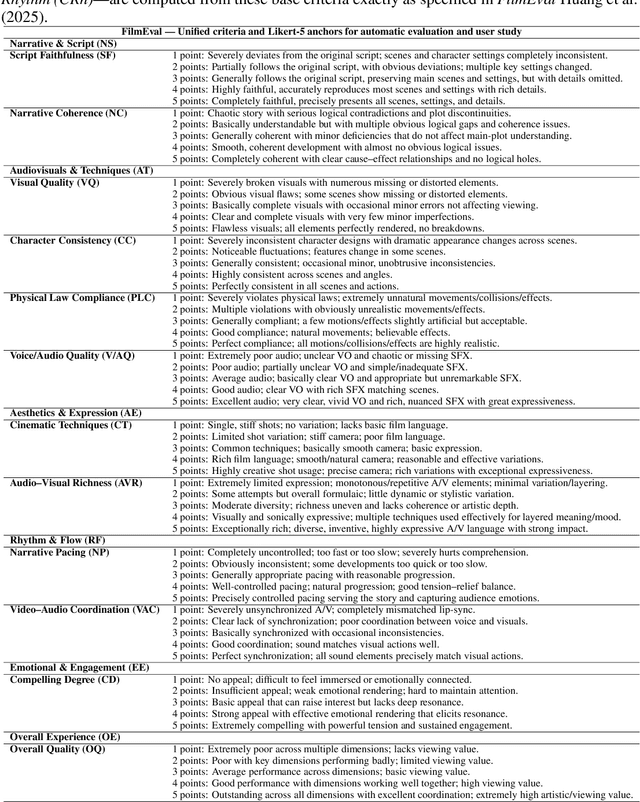
Recent advancements in multi-agent systems have demonstrated significant potential for enhancing creative task performance, such as long video generation. This study introduces three innovations to improve multi-agent collaboration. First, we propose OmniAgent, a hierarchical, graph-based multi-agent framework for long video generation that leverages a film-production-inspired architecture to enable modular specialization and scalable inter-agent collaboration. Second, inspired by context engineering, we propose hypergraph nodes that enable temporary group discussions among agents lacking sufficient context, reducing individual memory requirements while ensuring adequate contextual information. Third, we transition from directed acyclic graphs (DAGs) to directed cyclic graphs with limited retries, allowing agents to reflect and refine outputs iteratively, thereby improving earlier stages through feedback from subsequent nodes. These contributions lay the groundwork for developing more robust multi-agent systems in creative tasks.
From Superficial Outputs to Superficial Learning: Risks of Large Language Models in Education
Sep 26, 2025



Large Language Models (LLMs) are transforming education by enabling personalization, feedback, and knowledge access, while also raising concerns about risks to students and learning systems. Yet empirical evidence on these risks remains fragmented. This paper presents a systematic review of 70 empirical studies across computer science, education, and psychology. Guided by four research questions, we examine: (i) which applications of LLMs in education have been most frequently explored; (ii) how researchers have measured their impact; (iii) which risks stem from such applications; and (iv) what mitigation strategies have been proposed. We find that research on LLMs clusters around three domains: operational effectiveness, personalized applications, and interactive learning tools. Across these, model-level risks include superficial understanding, bias, limited robustness, anthropomorphism, hallucinations, privacy concerns, and knowledge constraints. When learners interact with LLMs, these risks extend to cognitive and behavioural outcomes, including reduced neural activity, over-reliance, diminished independent learning skills, and a loss of student agency. To capture this progression, we propose an LLM-Risk Adapted Learning Model that illustrates how technical risks cascade through interaction and interpretation to shape educational outcomes. As the first synthesis of empirically assessed risks, this review provides a foundation for responsible, human-centred integration of LLMs in education.
Simulating Generative Social Agents via Theory-Informed Workflow Design
Aug 12, 2025Recent advances in large language models have demonstrated strong reasoning and role-playing capabilities, opening new opportunities for agent-based social simulations. However, most existing agents' implementations are scenario-tailored, without a unified framework to guide the design. This lack of a general social agent limits their ability to generalize across different social contexts and to produce consistent, realistic behaviors. To address this challenge, we propose a theory-informed framework that provides a systematic design process for LLM-based social agents. Our framework is grounded in principles from Social Cognition Theory and introduces three key modules: motivation, action planning, and learning. These modules jointly enable agents to reason about their goals, plan coherent actions, and adapt their behavior over time, leading to more flexible and contextually appropriate responses. Comprehensive experiments demonstrate that our theory-driven agents reproduce realistic human behavior patterns under complex conditions, achieving up to 75% lower deviation from real-world behavioral data across multiple fidelity metrics compared to classical generative baselines. Ablation studies further show that removing motivation, planning, or learning modules increases errors by 1.5 to 3.2 times, confirming their distinct and essential contributions to generating realistic and coherent social behaviors.
M3G: Multi-Granular Gesture Generator for Audio-Driven Full-Body Human Motion Synthesis
May 13, 2025



Generating full-body human gestures encompassing face, body, hands, and global movements from audio is a valuable yet challenging task in virtual avatar creation. Previous systems focused on tokenizing the human gestures framewisely and predicting the tokens of each frame from the input audio. However, one observation is that the number of frames required for a complete expressive human gesture, defined as granularity, varies among different human gesture patterns. Existing systems fail to model these gesture patterns due to the fixed granularity of their gesture tokens. To solve this problem, we propose a novel framework named Multi-Granular Gesture Generator (M3G) for audio-driven holistic gesture generation. In M3G, we propose a novel Multi-Granular VQ-VAE (MGVQ-VAE) to tokenize motion patterns and reconstruct motion sequences from different temporal granularities. Subsequently, we proposed a multi-granular token predictor that extracts multi-granular information from audio and predicts the corresponding motion tokens. Then M3G reconstructs the human gestures from the predicted tokens using the MGVQ-VAE. Both objective and subjective experiments demonstrate that our proposed M3G framework outperforms the state-of-the-art methods in terms of generating natural and expressive full-body human gestures.
Characterizing LLM-driven Social Network: The Chirper.ai Case
Apr 14, 2025



Large language models (LLMs) demonstrate the ability to simulate human decision-making processes, enabling their use as agents in modeling sophisticated social networks, both offline and online. Recent research has explored collective behavioral patterns and structural characteristics of LLM agents within simulated networks. However, empirical comparisons between LLM-driven and human-driven online social networks remain scarce, limiting our understanding of how LLM agents differ from human users. This paper presents a large-scale analysis of Chirper.ai, an X/Twitter-like social network entirely populated by LLM agents, comprising over 65,000 agents and 7.7 million AI-generated posts. For comparison, we collect a parallel dataset from Mastodon, a human-driven decentralized social network, with over 117,000 users and 16 million posts. We examine key differences between LLM agents and humans in posting behaviors, abusive content, and social network structures. Our findings provide critical insights into the evolving landscape of online social network analysis in the AI era, offering a comprehensive profile of LLM agents in social simulations.
MetaCLBench: Meta Continual Learning Benchmark on Resource-Constrained Edge Devices
Mar 31, 2025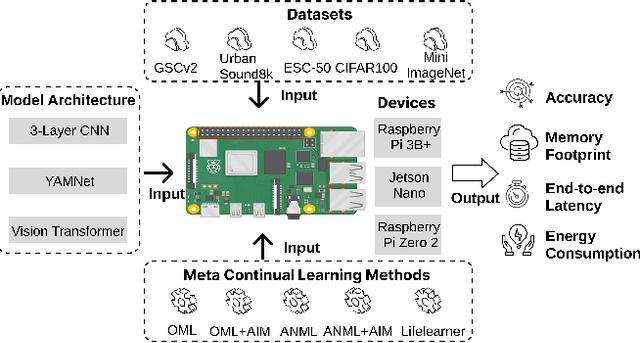
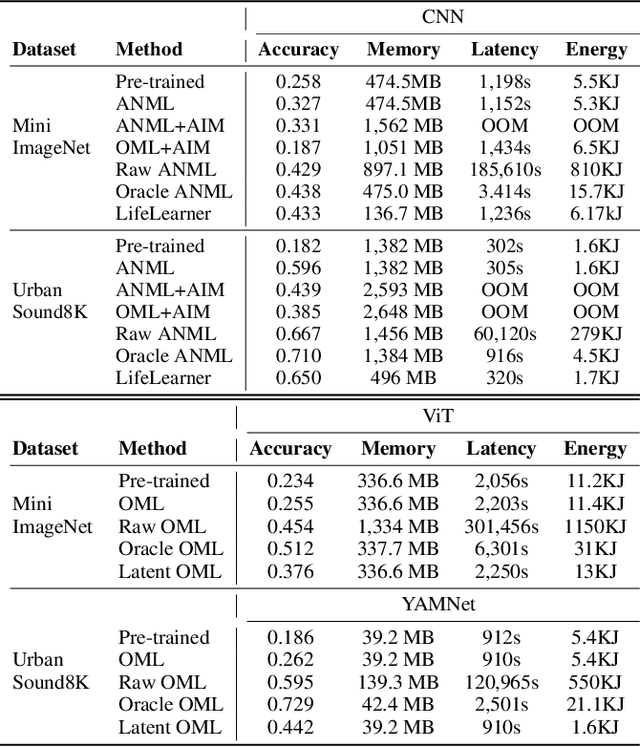
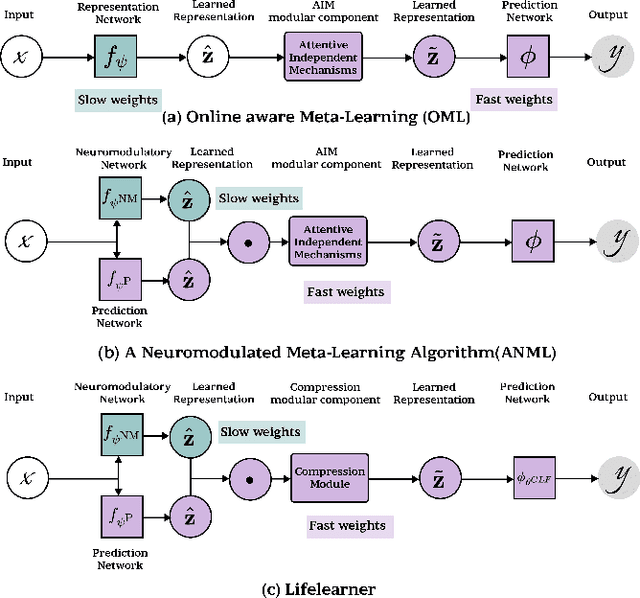
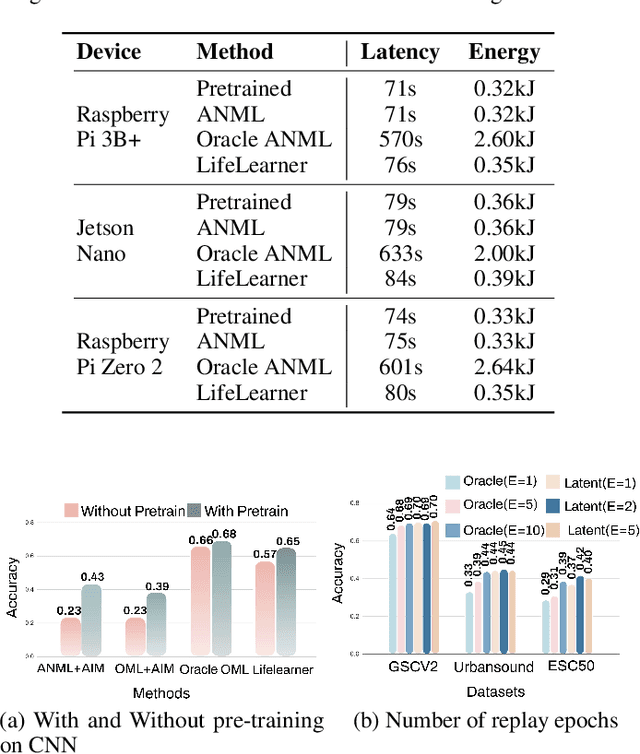
Meta-Continual Learning (Meta-CL) has emerged as a promising approach to minimize manual labeling efforts and system resource requirements by enabling Continual Learning (CL) with limited labeled samples. However, while existing methods have shown success in image-based tasks, their effectiveness remains unexplored for sequential time-series data from sensor systems, particularly audio inputs. To address this gap, we conduct a comprehensive benchmark study evaluating six representative Meta-CL approaches using three network architectures on five datasets from both image and audio modalities. We develop MetaCLBench, an end-to-end Meta-CL benchmark framework for edge devices to evaluate system overheads and investigate trade-offs among performance, computational costs, and memory requirements across various Meta-CL methods. Our results reveal that while many Meta-CL methods enable to learn new classes for both image and audio modalities, they impose significant computational and memory costs on edge devices. Also, we find that pre-training and meta-training procedures based on source data before deployment improve Meta-CL performance. Finally, to facilitate further research, we provide practical guidelines for researchers and machine learning practitioners implementing Meta-CL on resource-constrained environments and make our benchmark framework and tools publicly available, enabling fair evaluation across both accuracy and system-level metrics.
Analyzing the Synthetic-to-Real Domain Gap in 3D Hand Pose Estimation
Mar 25, 2025



Recent synthetic 3D human datasets for the face, body, and hands have pushed the limits on photorealism. Face recognition and body pose estimation have achieved state-of-the-art performance using synthetic training data alone, but for the hand, there is still a large synthetic-to-real gap. This paper presents the first systematic study of the synthetic-to-real gap of 3D hand pose estimation. We analyze the gap and identify key components such as the forearm, image frequency statistics, hand pose, and object occlusions. To facilitate our analysis, we propose a data synthesis pipeline to synthesize high-quality data. We demonstrate that synthetic hand data can achieve the same level of accuracy as real data when integrating our identified components, paving the path to use synthetic data alone for hand pose estimation. Code and data are available at: https://github.com/delaprada/HandSynthesis.git.
Experimental Exploration: Investigating Cooperative Interaction Behavior Between Humans and Large Language Model Agents
Mar 10, 2025



With the rise of large language models (LLMs), AI agents as autonomous decision-makers present significant opportunities and challenges for human-AI cooperation. While many studies have explored human cooperation with AI as tools, the role of LLM-augmented autonomous agents in competitive-cooperative interactions remains under-examined. This study investigates human cooperative behavior by engaging 30 participants who interacted with LLM agents exhibiting different characteristics (purported human, purported rule-based AI agent, and LLM agent) in repeated Prisoner's Dilemma games. Findings show significant differences in cooperative behavior based on the agents' purported characteristics and the interaction effect of participants' genders and purported characteristics. We also analyzed human response patterns, including game completion time, proactive favorable behavior, and acceptance of repair efforts. These insights offer a new perspective on human interactions with LLM agents in competitive cooperation contexts, such as virtual avatars or future physical entities. The study underscores the importance of understanding human biases toward AI agents and how observed behaviors can influence future human-AI cooperation dynamics.