 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaCLBench: Meta Continual Learning Benchmark on Resource-Constrained Edge Devices
Mar 31, 2025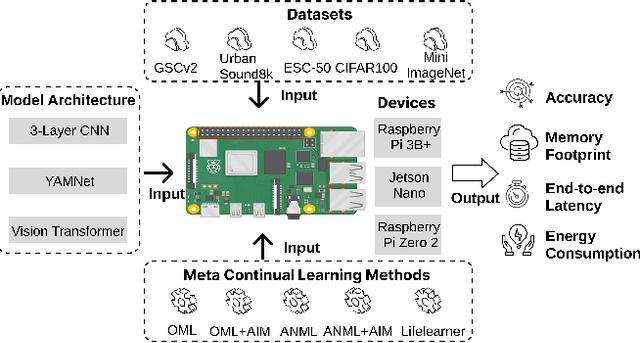
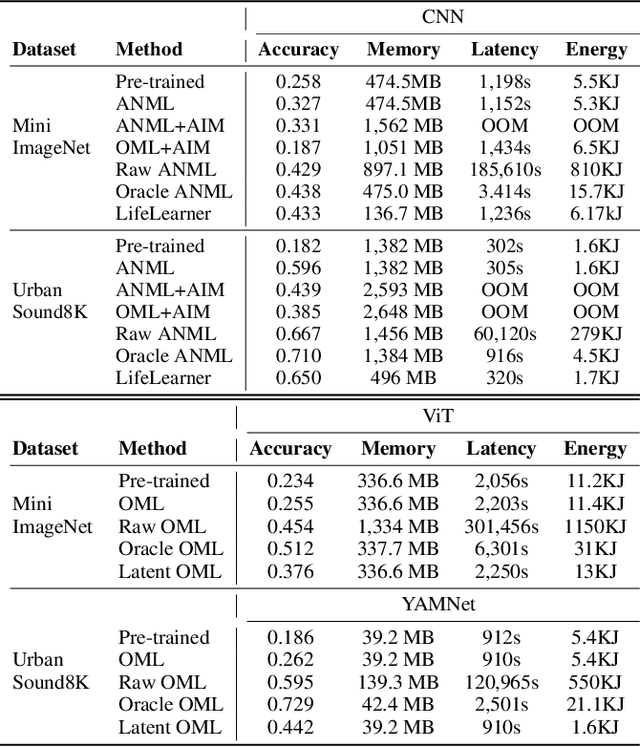
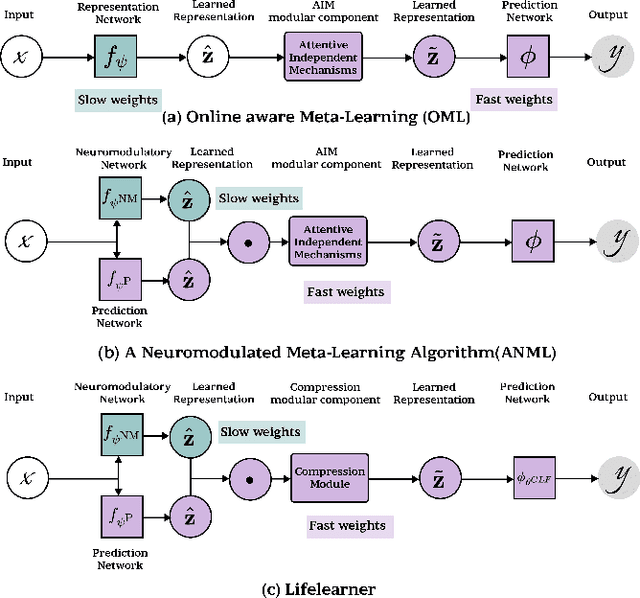
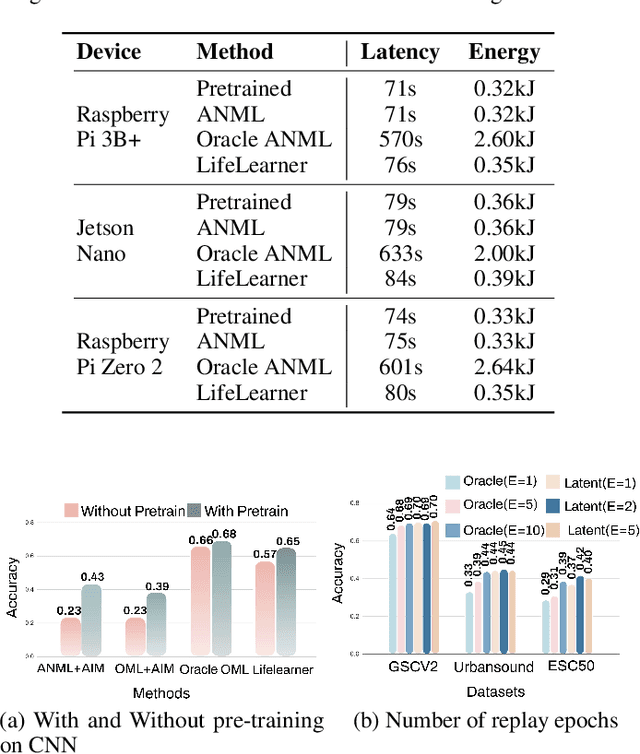
Meta-Continual Learning (Meta-CL) has emerged as a promising approach to minimize manual labeling efforts and system resource requirements by enabling Continual Learning (CL) with limited labeled samples. However, while existing methods have shown success in image-based tasks, their effectiveness remains unexplored for sequential time-series data from sensor systems, particularly audio inputs. To address this gap, we conduct a comprehensive benchmark study evaluating six representative Meta-CL approaches using three network architectures on five datasets from both image and audio modalities. We develop MetaCLBench, an end-to-end Meta-CL benchmark framework for edge devices to evaluate system overheads and investigate trade-offs among performance, computational costs, and memory requirements across various Meta-CL methods. Our results reveal that while many Meta-CL methods enable to learn new classes for both image and audio modalities, they impose significant computational and memory costs on edge devices. Also, we find that pre-training and meta-training procedures based on source data before deployment improve Meta-CL performance. Finally, to facilitate further research, we provide practical guidelines for researchers and machine learning practitioners implementing Meta-CL on resource-constrained environments and make our benchmark framework and tools publicly available, enabling fair evaluation across both accuracy and system-level metrics.
LMLPA: Language Model Linguistic Personality Assessment
Oct 23, 2024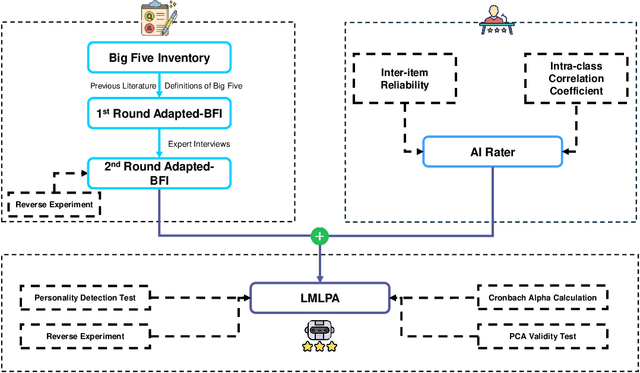


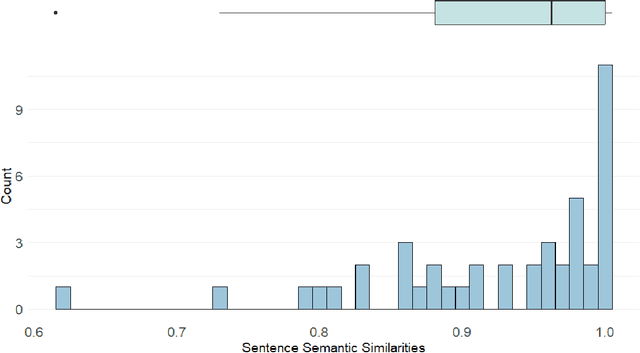
Large Language Models (LLMs) are increasingly used in everyday life and research. One of the most common use cases is conversational interactions, enabled by the language generation capabilities of LLMs. Just as between two humans, a conversation between an LLM-powered entity and a human depends on the personality of the conversants. However, measuring the personality of a given LLM is currently a challenge. This paper introduces the Language Model Linguistic Personality Assessment (LMLPA), a system designed to evaluate the linguistic personalities of LLMs. Our system helps to understand LLMs' language generation capabilities by quantitatively assessing the distinct personality traits reflected in their linguistic outputs. Unlike traditional human-centric psychometrics, the LMLPA adapts a personality assessment questionnaire, specifically the Big Five Inventory, to align with the operational capabilities of LLMs, and also incorporates the findings from previous language-based personality measurement literature. To mitigate sensitivity to the order of options, our questionnaire is designed to be open-ended, resulting in textual answers. Thus, the AI rater is needed to transform ambiguous personality information from text responses into clear numerical indicators of personality traits. Utilising Principal Component Analysis and reliability validations, our findings demonstrate that LLMs possess distinct personality traits that can be effectively quantified by the LMLPA. This research contributes to Human-Computer Interaction and Human-Centered AI, providing a robust framework for future studies to refine AI personality assessments and expand their applications in multiple areas, including education and manufacturing.
Towards Massive Interaction with Generalist Robotics: A Systematic Review of XR-enabled Remote Human-Robot Interaction Systems
Mar 26, 2024



The rising interest of generalist robots seek to create robots with versatility to handle multiple tasks in a variety of environments, and human will interact with such robots through immersive interfaces. In the context of human-robot interaction (HRI), this survey provides an exhaustive review of the applications of extended reality (XR) technologies in the field of remote HRI. We developed a systematic search strategy based on the PRISMA methodology. From the initial 2,561 articles selected, 100 research papers that met our inclusion criteria were included. We categorized and summarized the domain in detail, delving into XR technologies, including augmented reality (AR), virtual reality (VR), and mixed reality (MR), and their applications in facilitating intuitive and effective remote control and interaction with robotic systems. The survey highlights existing articles on the application of XR technologies, user experience enhancement, and various interaction designs for XR in remote HRI, providing insights into current trends and future directions. We also identified potential gaps and opportunities for future research to improve remote HRI systems through XR technology to guide and inform future XR and robotics research.
Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
Mar 08, 2024


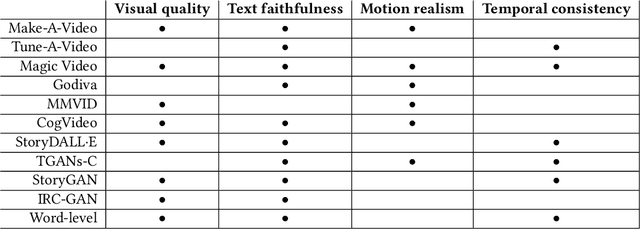
Text-to-video generation marks a significant frontier in the rapidly evolving domain of generative AI, integrating advancements in text-to-image synthesis, video captioning, and text-guided editing. This survey critically examines the progression of text-to-video technologies, focusing on the shift from traditional generative models to the cutting-edge Sora model, highlighting developments in scalability and generalizability. Distinguishing our analysis from prior works, we offer an in-depth exploration of the technological frameworks and evolutionary pathways of these models. Additionally, we delve into practical applications and address ethical and technological challenges such as the inability to perform multiple entity handling, comprehend causal-effect learning, understand physical interaction, perceive object scaling and proportioning, and combat object hallucination which is also a long-standing problem in generative models. Our comprehensive discussion covers the topic of enablement of text-to-video generation models as human-assistive tools and world models, as well as eliciting model's shortcomings and summarizing future improvement direction that mainly centers around training datasets and evaluation metrics (both automatic and human-centered). Aimed at both newcomers and seasoned researchers, this survey seeks to catalyze further innovation and discussion in the growing field of text-to-video generation, paving the way for more reliable and practical generative artificial intelligence technologies.
APT-Pipe: An Automatic Prompt-Tuning Tool for Social Computing Data Annotation
Feb 08, 2024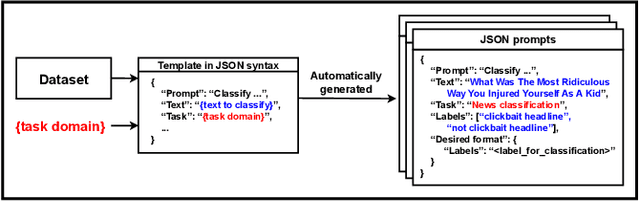

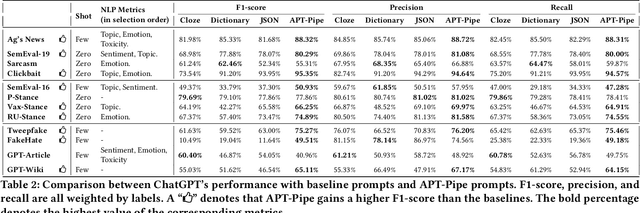
Recent research has highlighted the potential of LLM applications, like ChatGPT, for performing label annotation on social computing text. However, it is already well known that performance hinges on the quality of the input prompts. To address this, there has been a flurry of research into prompt tuning -- techniques and guidelines that attempt to improve the quality of prompts. Yet these largely rely on manual effort and prior knowledge of the dataset being annotated. To address this limitation, we propose APT-Pipe, an automated prompt-tuning pipeline. APT-Pipe aims to automatically tune prompts to enhance ChatGPT's text classification performance on any given dataset. We implement APT-Pipe and test it across twelve distinct text classification datasets. We find that prompts tuned by APT-Pipe help ChatGPT achieve higher weighted F1-score on nine out of twelve experimented datasets, with an improvement of 7.01% on average. We further highlight APT-Pipe's flexibility as a framework by showing how it can be extended to support additional tuning mechanisms.
Generative AI meets 3D: A Survey on Text-to-3D in AIGC Era
May 10, 2023

Generative AI (AIGC, a.k.a. AI generated content) has made remarkable progress in the past few years, among which text-guided content generation is the most practical one since it enables the interaction between human instruction and AIGC. Due to the development in text-to-image as well 3D modeling technologies (like NeRF), text-to-3D has become a newly emerging yet highly active research field. Our work conducts the first yet comprehensive survey on text-to-3D to help readers interested in this direction quickly catch up with its fast development. First, we introduce 3D data representations, including both Euclidean data and non-Euclidean data. On top of that, we introduce various foundation technologies as well as summarize how recent works combine those foundation technologies to realize satisfactory text-to-3D. Moreover, we summarize how text-to-3D technology is used in various applications, including avatar generation, texture generation, shape transformation, and scene generation.
Towards Computational Architecture of Liberty: A Comprehensive Survey on Deep Learning for Generating Virtual Architecture in the Metaverse
Apr 30, 2023
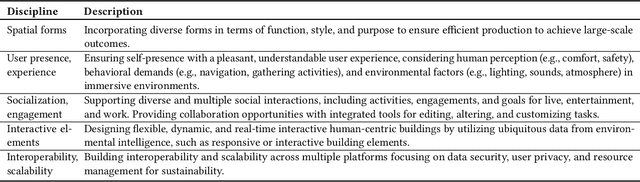


3D shape generation techniques utilizing deep learning are increasing attention from both computer vision and architectural design. This survey focuses on investigating and comparing the current latest approaches to 3D object generation with deep generative models (DGMs), including Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), 3D-aware images, and diffusion models. We discuss 187 articles (80.7% of articles published between 2018-2022) to review the field of generated possibilities of architecture in virtual environments, limited to the architecture form. We provide an overview of architectural research, virtual environment, and related technical approaches, followed by a review of recent trends in discrete voxel generation, 3D models generated from 2D images, and conditional parameters. We highlight under-explored issues in 3D generation and parameterized control that is worth further investigation. Moreover, we speculate that four research agendas including data limitation, editability, evaluation metrics, and human-computer interaction are important enablers of ubiquitous interaction with immersive systems in architecture for computer-aided design Our work contributes to researchers' understanding of the current potential and future needs of deep learnings in generating virtual architecture.
One Small Step for Generative AI, One Giant Leap for AGI: A Complete Survey on ChatGPT in AIGC Era
Apr 04, 2023OpenAI has recently released GPT-4 (a.k.a. ChatGPT plus), which is demonstrated to be one small step for generative AI (GAI), but one giant leap for artificial general intelligence (AGI). Since its official release in November 2022, ChatGPT has quickly attracted numerous users with extensive media coverage. Such unprecedented attention has also motivated numerous researchers to investigate ChatGPT from various aspects. According to Google scholar, there are more than 500 articles with ChatGPT in their titles or mentioning it in their abstracts. Considering this, a review is urgently needed, and our work fills this gap. Overall, this work is the first to survey ChatGPT with a comprehensive review of its underlying technology, applications, and challenges. Moreover, we present an outlook on how ChatGPT might evolve to realize general-purpose AIGC (a.k.a. AI-generated content), which will be a significant milestone for the development of AGI.
A Complete Survey on Generative AI : Is ChatGPT from GPT-4 to GPT-5 All You Need?
Mar 21, 2023



As ChatGPT goes viral, generative AI (AIGC, a.k.a AI-generated content) has made headlines everywhere because of its ability to analyze and create text, images, and beyond. With such overwhelming media coverage, it is almost impossible for us to miss the opportunity to glimpse AIGC from a certain angle. In the era of AI transitioning from pure analysis to creation, it is worth noting that ChatGPT, with its most recent language model GPT-4, is just a tool out of numerous AIGC tasks. Impressed by the capability of the ChatGPT, many people are wondering about its limits: can GPT-5 (or other future GPT variants) help ChatGPT unify all AIGC tasks for diversified content creation? Toward answering this question, a comprehensive review of existing AIGC tasks is needed. As such, our work comes to fill this gap promptly by offering a first look at AIGC, ranging from its techniques to applications. Modern generative AI relies on various technical foundations, ranging from model architecture and self-supervised pretraining to generative modeling methods (like GAN and diffusion models). After introducing the fundamental techniques, this work focuses on the technological development of various AIGC tasks based on their output type, including text, images, videos, 3D content, etc., which depicts the full potential of ChatGPT's future. Moreover, we summarize their significant applications in some mainstream industries, such as education and creativity content. Finally, we discuss the challenges currently faced and present an outlook on how generative AI might evolve in the near future.
Towards Reproducible Evaluations for Flying Drone Controllers in Virtual Environments
Jul 29, 2022



Research attention on natural user interfaces (NUIs) for drone flights are rising. Nevertheless, NUIs are highly diversified, and primarily evaluated by different physical environments leading to hard-to-compare performance between such solutions. We propose a virtual environment, namely VRFlightSim, enabling comparative evaluations with enriched drone flight details to address this issue. We first replicated a state-of-the-art (SOTA) interface and designed two tasks (crossing and pointing) in our virtual environment. Then, two user studies with 13 participants demonstrate the necessity of VRFlightSim and further highlight the potential of open-data interface designs.