 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlotVTG: Object-Centric Adapter for Generalizable Video Temporal Grounding
Mar 26, 2026Multimodal Large Language Models (MLLMs) have shown strong performance on Video Temporal Grounding (VTG). However, their coarse recognition capabilities are insufficient for fine-grained temporal understanding, making task-specific fine-tuning indispensable. This fine-tuning causes models to memorize dataset-specific shortcuts rather than faithfully grounding in the actual visual content, leading to poor Out-of-Domain (OOD) generalization. Object-centric learning offers a promising remedy by decomposing scenes into entity-level representations, but existing approaches require re-running the entire multi-stage training pipeline from scratch. We propose SlotVTG, a framework that steers MLLMs toward object-centric, input-grounded visual reasoning at minimal cost. SlotVTG introduces a lightweight slot adapter that decomposes visual tokens into abstract slots via slot attention and reconstructs the original sequence, where objectness priors from a self-supervised vision model encourage semantically coherent slot formation. Cross-domain evaluation on standard VTG benchmarks demonstrates that our approach significantly improves OOD robustness while maintaining competitive In-Domain (ID) performance with minimal overhead.
Chain-of-Goals Hierarchical Policy for Long-Horizon Offline Goal-Conditioned RL
Feb 03, 2026Offline goal-conditioned reinforcement learning remains challenging for long-horizon tasks. While hierarchical approaches mitigate this issue by decomposing tasks, most existing methods rely on separate high- and low-level networks and generate only a single intermediate subgoal, making them inadequate for complex tasks that require coordinating multiple intermediate decisions. To address this limitation, we draw inspiration from the chain-of-thought paradigm and propose the Chain-of-Goals Hierarchical Policy (CoGHP), a novel framework that reformulates hierarchical decision-making as autoregressive sequence modeling within a unified architecture. Given a state and a final goal, CoGHP autoregressively generates a sequence of latent subgoals followed by the primitive action, where each latent subgoal acts as a reasoning step that conditions subsequent predictions. To implement this efficiently, we pioneer the use of an MLP-Mixer backbone, which supports cross-token communication and captures structural relationships among state, goal, latent subgoals, and action. Across challenging navigation and manipulation benchmarks, CoGHP consistently outperforms strong offline baselines, demonstrating improved performance on long-horizon tasks.
Why Can't I Open My Drawer? Mitigating Object-Driven Shortcuts in Zero-Shot Compositional Action Recognition
Jan 22, 2026We study Compositional Video Understanding (CVU), where models must recognize verbs and objects and compose them to generalize to unseen combinations. We find that existing Zero-Shot Compositional Action Recognition (ZS-CAR) models fail primarily due to an overlooked failure mode: object-driven verb shortcuts. Through systematic analysis, we show that this behavior arises from two intertwined factors: severe sparsity and skewness of compositional supervision, and the asymmetric learning difficulty between verbs and objects. As training progresses, the existing ZS-CAR model increasingly ignores visual evidence and overfits to co-occurrence statistics. Consequently, the existing model does not gain the benefit of compositional recognition in unseen verb-object compositions. To address this, we propose RCORE, a simple and effective framework that enforces temporally grounded verb learning. RCORE introduces (i) a composition-aware augmentation that diversifies verb-object combinations without corrupting motion cues, and (ii) a temporal order regularization loss that penalizes shortcut behaviors by explicitly modeling temporal structure. Across two benchmarks, Sth-com and our newly constructed EK100-com, RCORE significantly improves unseen composition accuracy, reduces reliance on co-occurrence bias, and achieves consistently positive compositional gaps. Our findings reveal object-driven shortcuts as a critical limiting factor in ZS-CAR and demonstrate that addressing them is essential for robust compositional video understanding.
NOAH: Benchmarking Narrative Prior driven Hallucination and Omission in Video Large Language Models
Nov 09, 2025
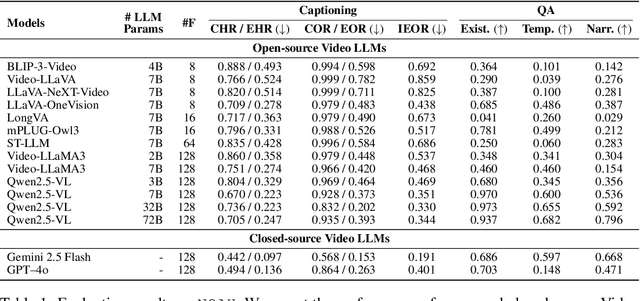
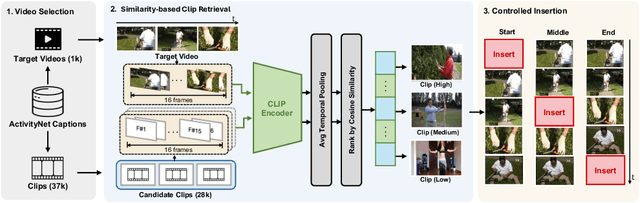

Video large language models (Video LLMs) have recently achieved strong performance on tasks such as captioning, summarization, and question answering. Many models and training methods explicitly encourage continuity across events to enhance narrative coherence. While this improves fluency, it also introduces an inductive bias that prioritizes storyline consistency over strict grounding in visual evidence. We identify this bias, which we call narrative prior, as a key driver of two errors: hallucinations, where non-existent events are introduced or existing ones are misinterpreted, and omissions, where factual events are suppressed because they are misaligned with surrounding context. To systematically evaluate narrative prior-induced errors, we introduce NOAH, a large-scale benchmark that constructs composite videos by inserting clips from other sources into target videos. By varying semantic similarity and insertion position, our benchmark enables controlled and scalable analysis of narrative priors. We design one captioning task with tailored metrics and three QA tasks - Existence, Temporal, and Narrative - yielding more than 60K evaluation samples. Extensive experiments yield three key findings: (i) most Video LLMs exhibit hallucinations and omissions driven by narrative priors, (ii) the patterns of these errors vary across architectures and depend on event similarity and insertion position, and (iii) reliance on narrative priors intensifies under sampling with fewer frames, amplifying errors when event continuity is weak. We establish NOAH as the first standardized evaluation of narrative prior-induced hallucination and omission in Video LLMs, providing a foundation for developing more reliable and trustworthy models. Our benchmark and code are available at https://anonymous550520.github.io/.
Disentangled Concepts Speak Louder Than Words:Explainable Video Action Recognition
Nov 05, 2025Effective explanations of video action recognition models should disentangle how movements unfold over time from the surrounding spatial context. However, existing methods based on saliency produce entangled explanations, making it unclear whether predictions rely on motion or spatial context. Language-based approaches offer structure but often fail to explain motions due to their tacit nature -- intuitively understood but difficult to verbalize. To address these challenges, we propose Disentangled Action aNd Context concept-based Explainable (DANCE) video action recognition, a framework that predicts actions through disentangled concept types: motion dynamics, objects, and scenes. We define motion dynamics concepts as human pose sequences. We employ a large language model to automatically extract object and scene concepts. Built on an ante-hoc concept bottleneck design, DANCE enforces prediction through these concepts. Experiments on four datasets -- KTH, Penn Action, HAA500, and UCF-101 -- demonstrate that DANCE significantly improves explanation clarity with competitive performance. We validate the superior interpretability of DANCE through a user study. Experimental results also show that DANCE is beneficial for model debugging, editing, and failure analysis.
ESSENTIAL: Episodic and Semantic Memory Integration for Video Class-Incremental Learning
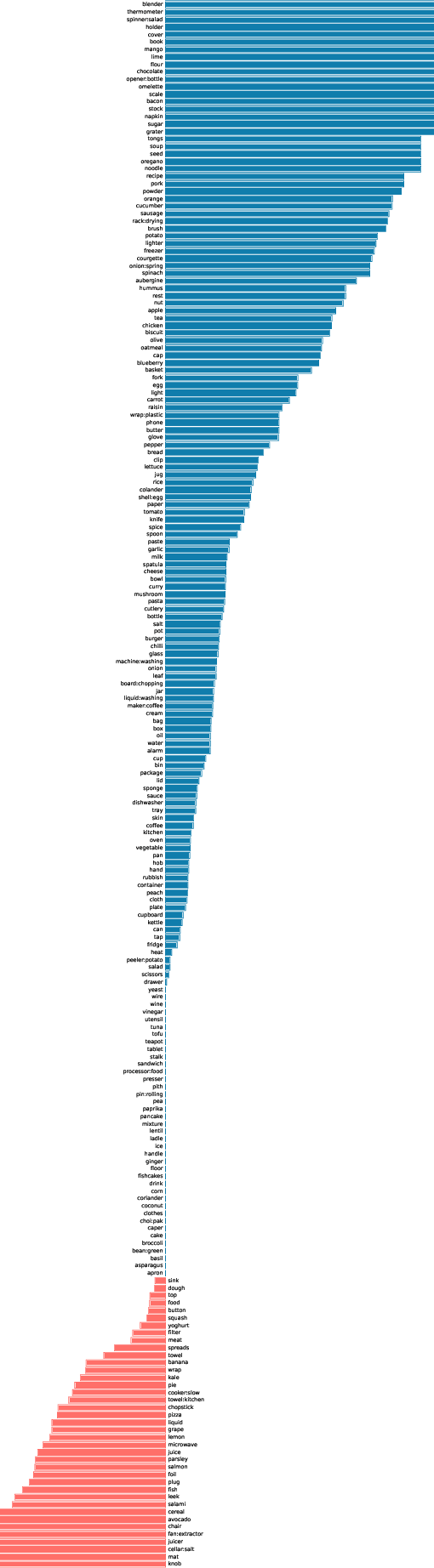
Aug 14, 2025In this work, we tackle the problem of video classincremental learning (VCIL). Many existing VCIL methods mitigate catastrophic forgetting by rehearsal training with a few temporally dense samples stored in episodic memory, which is memory-inefficient. Alternatively, some methods store temporally sparse samples, sacrificing essential temporal information and thereby resulting in inferior performance. To address this trade-off between memory-efficiency and performance, we propose EpiSodic and SEmaNTIc memory integrAtion for video class-incremental Learning (ESSENTIAL). ESSENTIAL consists of episodic memory for storing temporally sparse features and semantic memory for storing general knowledge represented by learnable prompts. We introduce a novel memory retrieval (MR) module that integrates episodic memory and semantic prompts through cross-attention, enabling the retrieval of temporally dense features from temporally sparse features. We rigorously validate ESSENTIAL on diverse datasets: UCF-101, HMDB51, and Something-Something-V2 from the TCD benchmark and UCF-101, ActivityNet, and Kinetics-400 from the vCLIMB benchmark. Remarkably, with significantly reduced memory, ESSENTIAL achieves favorable performance on the benchmarks.
Universal Domain Adaptation for Semantic Segmentation
May 28, 2025Unsupervised domain adaptation for semantic segmentation (UDA-SS) aims to transfer knowledge from labeled source data to unlabeled target data. However, traditional UDA-SS methods assume that category settings between source and target domains are known, which is unrealistic in real-world scenarios. This leads to performance degradation if private classes exist. To address this limitation, we propose Universal Domain Adaptation for Semantic Segmentation (UniDA-SS), achieving robust adaptation even without prior knowledge of category settings. We define the problem in the UniDA-SS scenario as low confidence scores of common classes in the target domain, which leads to confusion with private classes. To solve this problem, we propose UniMAP: UniDA-SS with Image Matching and Prototype-based Distinction, a novel framework composed of two key components. First, Domain-Specific Prototype-based Distinction (DSPD) divides each class into two domain-specific prototypes, enabling finer separation of domain-specific features and enhancing the identification of common classes across domains. Second, Target-based Image Matching (TIM) selects a source image containing the most common-class pixels based on the target pseudo-label and pairs it in a batch to promote effective learning of common classes. We also introduce a new UniDA-SS benchmark and demonstrate through various experiments that UniMAP significantly outperforms baselines. The code is available at \href{https://github.com/KU-VGI/UniMAP}{this https URL}.
Dynamic Contrastive Skill Learning with State-Transition Based Skill Clustering and Dynamic Length Adjustment
Apr 21, 2025Reinforcement learning (RL) has made significant progress in various domains, but scaling it to long-horizon tasks with complex decision-making remains challenging. Skill learning attempts to address this by abstracting actions into higher-level behaviors. However, current approaches often fail to recognize semantically similar behaviors as the same skill and use fixed skill lengths, limiting flexibility and generalization. To address this, we propose Dynamic Contrastive Skill Learning (DCSL), a novel framework that redefines skill representation and learning. DCSL introduces three key ideas: state-transition based skill representation, skill similarity function learning, and dynamic skill length adjustment. By focusing on state transitions and leveraging contrastive learning, DCSL effectively captures the semantic context of behaviors and adapts skill lengths to match the appropriate temporal extent of behaviors. Our approach enables more flexible and adaptive skill extraction, particularly in complex or noisy datasets, and demonstrates competitive performance compared to existing methods in task completion and efficiency.
PCBEAR: Pose Concept Bottleneck for Explainable Action Recognition
Apr 17, 2025Human action recognition (HAR) has achieved impressive results with deep learning models, but their decision-making process remains opaque due to their black-box nature. Ensuring interpretability is crucial, especially for real-world applications requiring transparency and accountability. Existing video XAI methods primarily rely on feature attribution or static textual concepts, both of which struggle to capture motion dynamics and temporal dependencies essential for action understanding. To address these challenges, we propose Pose Concept Bottleneck for Explainable Action Recognition (PCBEAR), a novel concept bottleneck framework that introduces human pose sequences as motion-aware, structured concepts for video action recognition. Unlike methods based on pixel-level features or static textual descriptions, PCBEAR leverages human skeleton poses, which focus solely on body movements, providing robust and interpretable explanations of motion dynamics. We define two types of pose-based concepts: static pose concepts for spatial configurations at individual frames, and dynamic pose concepts for motion patterns across multiple frames. To construct these concepts, PCBEAR applies clustering to video pose sequences, allowing for automatic discovery of meaningful concepts without manual annotation. We validate PCBEAR on KTH, Penn-Action, and HAA500, showing that it achieves high classification performance while offering interpretable, motion-driven explanations. Our method provides both strong predictive performance and human-understandable insights into the model's reasoning process, enabling test-time interventions for debugging and improving model behavior.
CA^2ST: Cross-Attention in Audio, Space, and Time for Holistic Video Recognition
Mar 30, 2025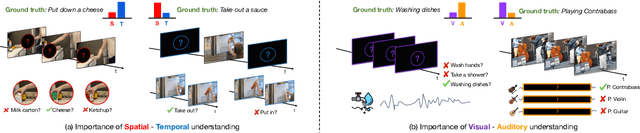
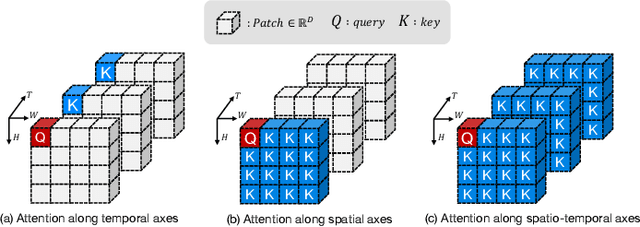
We propose Cross-Attention in Audio, Space, and Time (CA^2ST), a transformer-based method for holistic video recognition. Recognizing actions in videos requires both spatial and temporal understanding, yet most existing models lack a balanced spatio-temporal understanding of videos. To address this, we propose a novel two-stream architecture, called Cross-Attention in Space and Time (CAST), using only RGB input. In each layer of CAST, Bottleneck Cross-Attention (B-CA) enables spatial and temporal experts to exchange information and make synergistic predictions. For holistic video understanding, we extend CAST by integrating an audio expert, forming Cross-Attention in Visual and Audio (CAVA). We validate the CAST on benchmarks with different characteristics, EPIC-KITCHENS-100, Something-Something-V2, and Kinetics-400, consistently showing balanced performance. We also validate the CAVA on audio-visual action recognition benchmarks, including UCF-101, VGG-Sound, KineticsSound, and EPIC-SOUNDS. With a favorable performance of CAVA across these datasets, we demonstrate the effective information exchange among multiple experts within the B-CA module. In summary, CA^2ST combines CAST and CAVA by employing spatial, temporal, and audio experts through cross-attention, achieving balanced and holistic video understanding.