 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Goals Hierarchical Policy for Long-Horizon Offline Goal-Conditioned RL
Feb 03, 2026Offline goal-conditioned reinforcement learning remains challenging for long-horizon tasks. While hierarchical approaches mitigate this issue by decomposing tasks, most existing methods rely on separate high- and low-level networks and generate only a single intermediate subgoal, making them inadequate for complex tasks that require coordinating multiple intermediate decisions. To address this limitation, we draw inspiration from the chain-of-thought paradigm and propose the Chain-of-Goals Hierarchical Policy (CoGHP), a novel framework that reformulates hierarchical decision-making as autoregressive sequence modeling within a unified architecture. Given a state and a final goal, CoGHP autoregressively generates a sequence of latent subgoals followed by the primitive action, where each latent subgoal acts as a reasoning step that conditions subsequent predictions. To implement this efficiently, we pioneer the use of an MLP-Mixer backbone, which supports cross-token communication and captures structural relationships among state, goal, latent subgoals, and action. Across challenging navigation and manipulation benchmarks, CoGHP consistently outperforms strong offline baselines, demonstrating improved performance on long-horizon tasks.
Radar-Based NLoS Pedestrian Localization for Darting-Out Scenarios Near Parked Vehicles with Camera-Assisted Point Cloud Interpretation
Aug 06, 2025



The presence of Non-Line-of-Sight (NLoS) blind spots resulting from roadside parking in urban environments poses a significant challenge to road safety, particularly due to the sudden emergence of pedestrians. mmWave technology leverages diffraction and reflection to observe NLoS regions, and recent studies have demonstrated its potential for detecting obscured objects. However, existing approaches predominantly rely on predefined spatial information or assume simple wall reflections, thereby limiting their generalizability and practical applicability. A particular challenge arises in scenarios where pedestrians suddenly appear from between parked vehicles, as these parked vehicles act as temporary spatial obstructions. Furthermore, since parked vehicles are dynamic and may relocate over time, spatial information obtained from satellite maps or other predefined sources may not accurately reflect real-time road conditions, leading to erroneous sensor interpretations. To address this limitation, we propose an NLoS pedestrian localization framework that integrates monocular camera image with 2D radar point cloud (PCD) data. The proposed method initially detects parked vehicles through image segmentation, estimates depth to infer approximate spatial characteristics, and subsequently refines this information using 2D radar PCD to achieve precise spatial inference. Experimental evaluations conducted in real-world urban road environments demonstrate that the proposed approach enhances early pedestrian detection and contributes to improved road safety. Supplementary materials are available at https://hiyeun.github.io/NLoS/.
Dynamic Contrastive Skill Learning with State-Transition Based Skill Clustering and Dynamic Length Adjustment
Apr 21, 2025Reinforcement learning (RL) has made significant progress in various domains, but scaling it to long-horizon tasks with complex decision-making remains challenging. Skill learning attempts to address this by abstracting actions into higher-level behaviors. However, current approaches often fail to recognize semantically similar behaviors as the same skill and use fixed skill lengths, limiting flexibility and generalization. To address this, we propose Dynamic Contrastive Skill Learning (DCSL), a novel framework that redefines skill representation and learning. DCSL introduces three key ideas: state-transition based skill representation, skill similarity function learning, and dynamic skill length adjustment. By focusing on state transitions and leveraging contrastive learning, DCSL effectively captures the semantic context of behaviors and adapts skill lengths to match the appropriate temporal extent of behaviors. Our approach enables more flexible and adaptive skill extraction, particularly in complex or noisy datasets, and demonstrates competitive performance compared to existing methods in task completion and efficiency.
Leveraging Language Models for Out-of-Distribution Recovery in Reinforcement Learning
Mar 21, 2025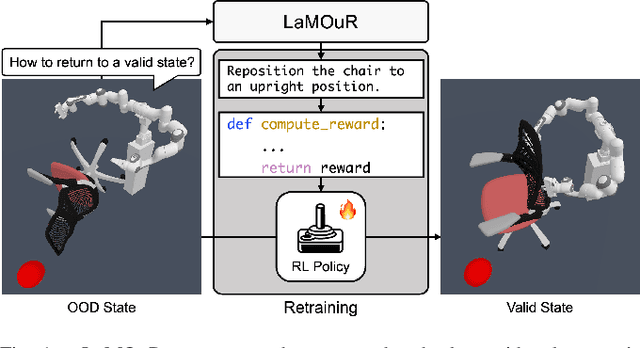



Deep Reinforcement Learning (DRL) has demonstrated strong performance in robotic control but remains susceptible to out-of-distribution (OOD) states, often resulting in unreliable actions and task failure. While previous methods have focused on minimizing or preventing OOD occurrences, they largely neglect recovery once an agent encounters such states. Although the latest research has attempted to address this by guiding agents back to in-distribution states, their reliance on uncertainty estimation hinders scalability in complex environments. To overcome this limitation, we introduce Language Models for Out-of-Distribution Recovery (LaMOuR), which enables recovery learning without relying on uncertainty estimation. LaMOuR generates dense reward codes that guide the agent back to a state where it can successfully perform its original task, leveraging the capabilities of LVLMs in image description, logical reasoning, and code generation. Experimental results show that LaMOuR substantially enhances recovery efficiency across diverse locomotion tasks and even generalizes effectively to complex environments, including humanoid locomotion and mobile manipulation, where existing methods struggle. The code and supplementary materials are available at \href{https://lamour-rl.github.io/}{https://lamour-rl.github.io/}.
DIAL: Distribution-Informed Adaptive Learning of Multi-Task Constraints for Safety-Critical Systems
Jan 30, 2025Safe reinforcement learning has traditionally relied on predefined constraint functions to ensure safety in complex real-world tasks, such as autonomous driving. However, defining these functions accurately for varied tasks is a persistent challenge. Recent research highlights the potential of leveraging pre-acquired task-agnostic knowledge to enhance both safety and sample efficiency in related tasks. Building on this insight, we propose a novel method to learn shared constraint distributions across multiple tasks. Our approach identifies the shared constraints through imitation learning and then adapts to new tasks by adjusting risk levels within these learned distributions. This adaptability addresses variations in risk sensitivity stemming from expert-specific biases, ensuring consistent adherence to general safety principles even with imperfect demonstrations. Our method can be applied to control and navigation domains, including multi-task and meta-task scenarios, accommodating constraints such as maintaining safe distances or adhering to speed limits. Experimental results validate the efficacy of our approach, demonstrating superior safety performance and success rates compared to baselines, all without requiring task-specific constraint definitions. These findings underscore the versatility and practicality of our method across a wide range of real-world tasks.
E2Map: Experience-and-Emotion Map for Self-Reflective Robot Navigation with Language Models
Sep 16, 2024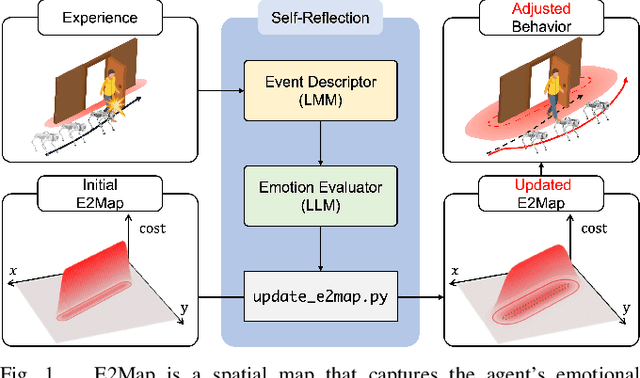



Large language models (LLMs) have shown significant potential in guiding embodied agents to execute language instructions across a range of tasks, including robotic manipulation and navigation. However, existing methods are primarily designed for static environments and do not leverage the agent's own experiences to refine its initial plans. Given that real-world environments are inherently stochastic, initial plans based solely on LLMs' general knowledge may fail to achieve their objectives, unlike in static scenarios. To address this limitation, this study introduces the Experience-and-Emotion Map (E2Map), which integrates not only LLM knowledge but also the agent's real-world experiences, drawing inspiration from human emotional responses. The proposed methodology enables one-shot behavior adjustments by updating the E2Map based on the agent's experiences. Our evaluation in stochastic navigation environments, including both simulations and real-world scenarios, demonstrates that the proposed method significantly enhances performance in stochastic environments compared to existing LLM-based approaches. Code and supplementary materials are available at https://e2map.github.io/.
Autonomous Algorithm for Training Autonomous Vehicles with Minimal Human Intervention
May 22, 2024



Reinforcement learning (RL) provides a compelling framework for enabling autonomous vehicles to continue to learn and improve diverse driving behaviors on their own. However, training real-world autonomous vehicles with current RL algorithms presents several challenges. One critical challenge, often overlooked in these algorithms, is the need to reset a driving environment between every episode. While resetting an environment after each episode is trivial in simulated settings, it demands significant human intervention in the real world. In this paper, we introduce a novel autonomous algorithm that allows off-the-shelf RL algorithms to train an autonomous vehicle with minimal human intervention. Our algorithm takes into account the learning progress of the autonomous vehicle to determine when to abort episodes before it enters unsafe states and where to reset it for subsequent episodes in order to gather informative transitions. The learning progress is estimated based on the novelty of both current and future states. We also take advantage of rule-based autonomous driving algorithms to safely reset an autonomous vehicle to an initial state. We evaluate our algorithm against baselines on diverse urban driving tasks. The experimental results show that our algorithm is task-agnostic and achieves better driving performance with fewer manual resets than baselines.
Traversability-aware Adaptive Optimization for Path Planning and Control in Mountainous Terrain
Apr 04, 2024
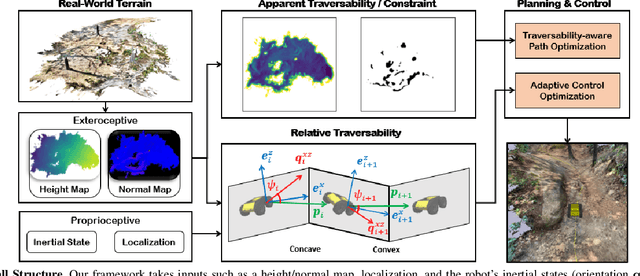
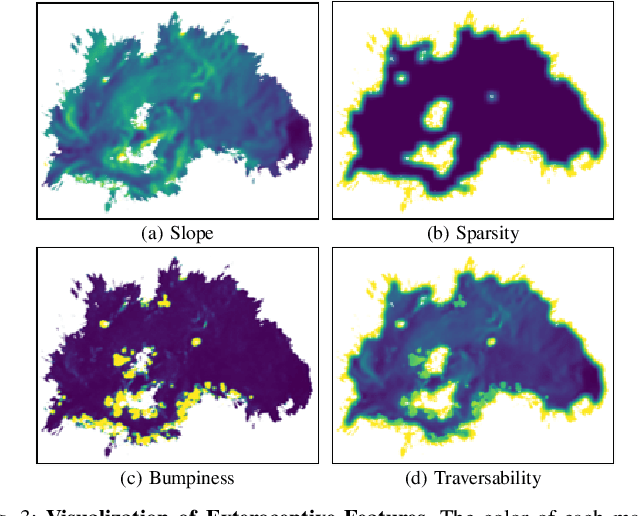

Autonomous navigation in extreme mountainous terrains poses challenges due to the presence of mobility-stressing elements and undulating surfaces, making it particularly difficult compared to conventional off-road driving scenarios. In such environments, estimating traversability solely based on exteroceptive sensors often leads to the inability to reach the goal due to a high prevalence of non-traversable areas. In this paper, we consider traversability as a relative value that integrates the robot's internal state, such as speed and torque to exhibit resilient behavior to reach its goal successfully. We separate traversability into apparent traversability and relative traversability, then incorporate these distinctions in the optimization process of sampling-based planning and motion predictive control. Our method enables the robots to execute the desired behaviors more accurately while avoiding hazardous regions and getting stuck. Experiments conducted on simulation with 27 diverse types of mountainous terrain and real-world demonstrate the robustness of the proposed framework, with increasingly better performance observed in more complex environments.
Results and Lessons Learned from Autonomous Driving Transportation Services in Airfield, Crowded Indoor, and Urban Environments
Mar 02, 2024Autonomous vehicles have been actively investigated over the past few decades. Several recent works show the potential of autonomous driving transportation services in urban environments with impressive experimental results. However, these works note that autonomous vehicles are still occasionally inferior to expert drivers in complex scenarios. Furthermore, they do not focus on the possibilities of autonomous driving transportation services in other areas beyond urban environments. This paper presents the research results and lessons learned from autonomous driving transportation services in airfield, crowded indoor, and urban environments. We discuss how we address several unique challenges in these diverse environments. We also offer an overview of remaining challenges that have not received much attention but must be addressed. This paper aims to share our unique experience to support researchers who are interested in realizing the potential of autonomous vehicles in various real-world environments.
Follow the Footprints: Self-supervised Traversability Estimation for Off-road Vehicle Navigation based on Geometric and Visual Cues
Feb 23, 2024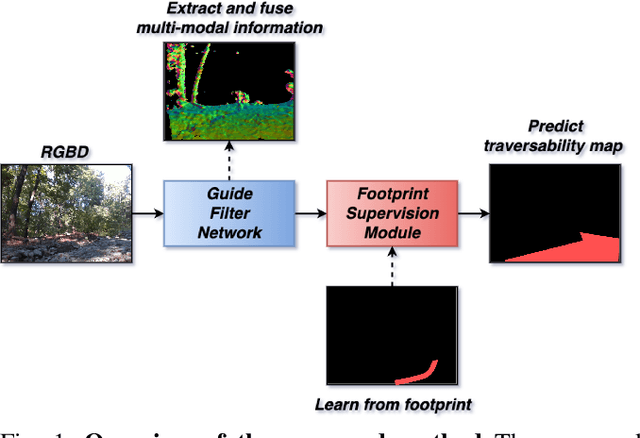
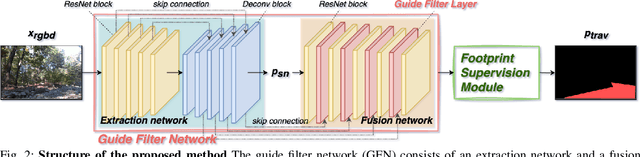
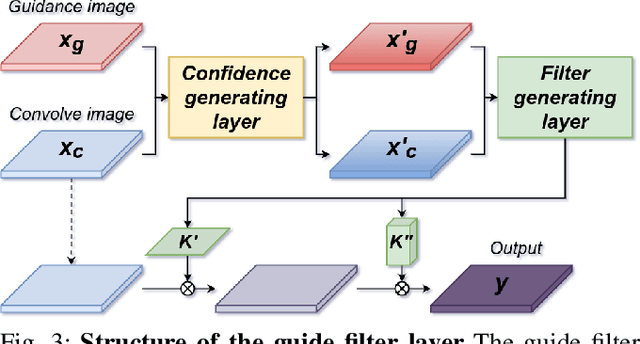
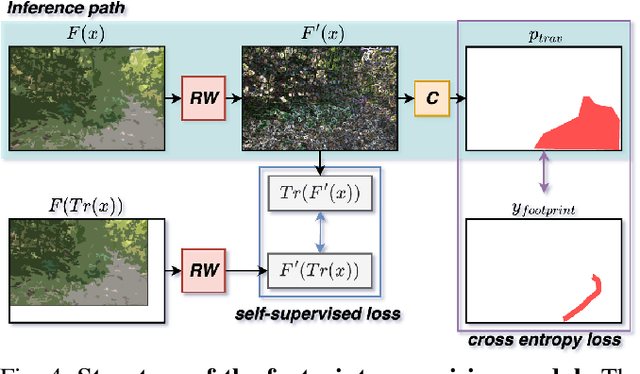
In this study, we address the off-road traversability estimation problem, that predicts areas where a robot can navigate in off-road environments. An off-road environment is an unstructured environment comprising a combination of traversable and non-traversable spaces, which presents a challenge for estimating traversability. This study highlights three primary factors that affect a robot's traversability in an off-road environment: surface slope, semantic information, and robot platform. We present two strategies for estimating traversability, using a guide filter network (GFN) and footprint supervision module (FSM). The first strategy involves building a novel GFN using a newly designed guide filter layer. The GFN interprets the surface and semantic information from the input data and integrates them to extract features optimized for traversability estimation. The second strategy involves developing an FSM, which is a self-supervision module that utilizes the path traversed by the robot in pre-driving, also known as a footprint. This enables the prediction of traversability that reflects the characteristics of the robot platform. Based on these two strategies, the proposed method overcomes the limitations of existing methods, which require laborious human supervision and lack scalability. Extensive experiments in diverse conditions, including automobiles and unmanned ground vehicles, herbfields, woodlands, and farmlands, demonstrate that the proposed method is compatible for various robot platforms and adaptable to a range of terrains. Code is available at https://github.com/yurimjeon1892/FtFoot.