 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunk Knowledge Generation Model for Enhanced Information Retrieval: A Multi-task Learning Approach
Sep 19, 2025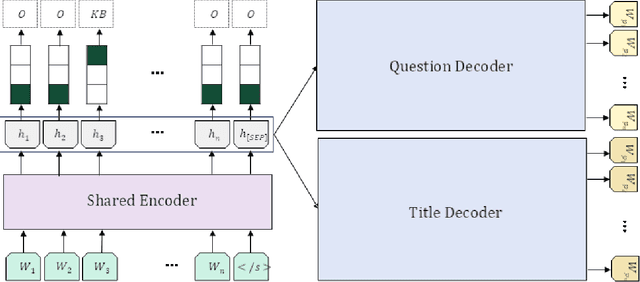



Traditional query expansion techniques for addressing vocabulary mismatch problems in information retrieval are context-sensitive and may lead to performance degradation. As an alternative, document expansion research has gained attention, but existing methods such as Doc2Query have limitations including excessive preprocessing costs, increased index size, and reliability issues with generated content. To mitigate these problems and seek more structured and efficient alternatives, this study proposes a method that divides documents into chunk units and generates textual data for each chunk to simultaneously improve retrieval efficiency and accuracy. The proposed "Chunk Knowledge Generation Model" adopts a T5-based multi-task learning structure that simultaneously generates titles and candidate questions from each document chunk while extracting keywords from user queries. This approach maximizes computational efficiency by generating and extracting three types of semantic information in parallel through a single encoding and two decoding processes. The generated data is utilized as additional information in the retrieval system. GPT-based evaluation on 305 query-document pairs showed that retrieval using the proposed model achieved 95.41% accuracy at Top@10, demonstrating superior performance compared to document chunk-level retrieval. This study contributes by proposing an approach that simultaneously generates titles and candidate questions from document chunks for application in retrieval pipelines, and provides empirical evidence applicable to large-scale information retrieval systems by demonstrating improved retrieval accuracy through qualitative evaluation.
Do You Keep an Eye on What I Ask? Mitigating Multimodal Hallucination via Attention-Guided Ensemble Decoding
May 23, 2025Recent advancements in Large Vision-Language Models (LVLMs) have significantly expanded their utility in tasks like image captioning and visual question answering. However, they still struggle with object hallucination, where models generate descriptions that inaccurately reflect the visual content by including nonexistent objects or misrepresenting existing ones. While previous methods, such as data augmentation and training-free approaches, strive to tackle this issue, they still encounter scalability challenges and often depend on additional external modules. In this work, we propose Ensemble Decoding (ED), a novel strategy that splits the input image into sub-images and combines logit distributions by assigning weights through the attention map. Furthermore, we introduce ED adaptive plausibility constraint to calibrate logit distribution and FastED, a variant designed for speed-critical applications. Extensive experiments across hallucination benchmarks demonstrate that our proposed method achieves state-of-the-art performance, validating the effectiveness of our approach.
GOTLoc: General Outdoor Text-based Localization Using Scene Graph Retrieval with OpenStreetMap
Jan 15, 2025We propose GOTLoc, a robust localization method capable of operating even in outdoor environments where GPS signals are unavailable. The method achieves this robust localization by leveraging comparisons between scene graphs generated from text descriptions and maps. Existing text-based localization studies typically represent maps as point clouds and identify the most similar scenes by comparing embeddings of text and point cloud data. However, point cloud maps have limited scalability as it is impractical to pre-generate maps for all outdoor spaces. Furthermore, their large data size makes it challenging to store and utilize them directly on actual robots. To address these issues, GOTLoc leverages compact data structures, such as scene graphs, to store spatial information, enabling individual robots to carry and utilize large amounts of map data. Additionally, by utilizing publicly available map data, such as OpenStreetMap, which provides global information on outdoor spaces, we eliminate the need for additional effort to create custom map data. For performance evaluation, we utilized the KITTI360Pose dataset in conjunction with corresponding OpenStreetMap data to compare the proposed method with existing approaches. Our results demonstrate that the proposed method achieves accuracy comparable to algorithms relying on point cloud maps. Moreover, in city-scale tests, GOTLoc required significantly less storage compared to point cloud-based methods and completed overall processing within a few seconds, validating its applicability to real-world robotics. Our code is available at https://github.com/donghwijung/GOTLoc.
CL3DOR: Contrastive Learning for 3D Large Multimodal Models via Odds Ratio on High-Resolution Point Clouds
Jan 07, 2025Recent research has demonstrated that Large Language Models (LLMs) are not limited to text-only tasks but can also function as multimodal models across various modalities, including audio, images, and videos. In particular, research on 3D Large Multimodal Models (3D LMMs) is making notable strides, driven by the potential of processing higher-dimensional data like point clouds. However, upon closer examination, we find that the visual and textual content within each sample of existing training datasets lacks both high informational granularity and clarity, which serve as a bottleneck for precise cross-modal understanding. To address these issues, we propose CL3DOR, Contrastive Learning for 3D large multimodal models via Odds ratio on high-Resolution point clouds, designed to ensure greater specificity and clarity in both visual and textual content. Specifically, we increase the density of point clouds per object and construct informative hard negative responses in the training dataset to penalize unwanted responses. To leverage hard negative responses, we incorporate the odds ratio as an auxiliary term for contrastive learning into the conventional language modeling loss. CL3DOR achieves state-of-the-art performance in 3D scene understanding and reasoning benchmarks. Additionally, we demonstrate the effectiveness of CL3DOR's key components through extensive experiments.
E2Map: Experience-and-Emotion Map for Self-Reflective Robot Navigation with Language Models
Sep 16, 2024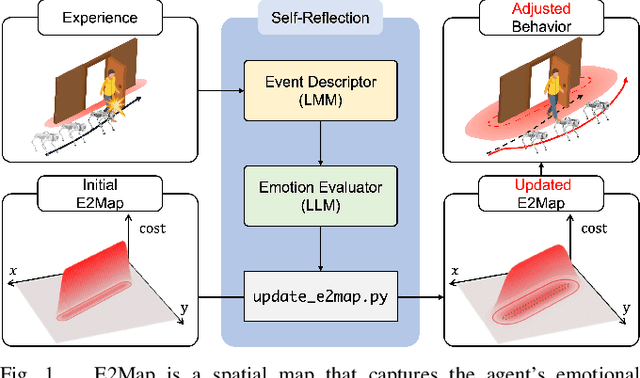



Large language models (LLMs) have shown significant potential in guiding embodied agents to execute language instructions across a range of tasks, including robotic manipulation and navigation. However, existing methods are primarily designed for static environments and do not leverage the agent's own experiences to refine its initial plans. Given that real-world environments are inherently stochastic, initial plans based solely on LLMs' general knowledge may fail to achieve their objectives, unlike in static scenarios. To address this limitation, this study introduces the Experience-and-Emotion Map (E2Map), which integrates not only LLM knowledge but also the agent's real-world experiences, drawing inspiration from human emotional responses. The proposed methodology enables one-shot behavior adjustments by updating the E2Map based on the agent's experiences. Our evaluation in stochastic navigation environments, including both simulations and real-world scenarios, demonstrates that the proposed method significantly enhances performance in stochastic environments compared to existing LLM-based approaches. Code and supplementary materials are available at https://e2map.github.io/.
DEBATE: Devil's Advocate-Based Assessment and Text Evaluation
May 16, 2024As natural language generation (NLG) models have become prevalent, systematically assessing the quality of machine-generated texts has become increasingly important. Recent studies introduce LLM-based evaluators that operate as reference-free metrics, demonstrating their capability to adeptly handle novel tasks. However, these models generally rely on a single-agent approach, which, we argue, introduces an inherent limit to their performance. This is because there exist biases in LLM agent's responses, including preferences for certain text structure or content. In this work, we propose DEBATE, an NLG evaluation framework based on multi-agent scoring system augmented with a concept of Devil's Advocate. Within the framework, one agent is instructed to criticize other agents' arguments, potentially resolving the bias in LLM agent's answers. DEBATE substantially outperforms the previous state-of-the-art methods in two meta-evaluation benchmarks in NLG evaluation, SummEval and TopicalChat. We also show that the extensiveness of debates among agents and the persona of an agent can influence the performance of evaluators.
DRAFT: Dense Retrieval Augmented Few-shot Topic classifier Framework
Dec 05, 2023With the growing volume of diverse information, the demand for classifying arbitrary topics has become increasingly critical. To address this challenge, we introduce DRAFT, a simple framework designed to train a classifier for few-shot topic classification. DRAFT uses a few examples of a specific topic as queries to construct Customized dataset with a dense retriever model. Multi-query retrieval (MQR) algorithm, which effectively handles multiple queries related to a specific topic, is applied to construct the Customized dataset. Subsequently, we fine-tune a classifier using the Customized dataset to identify the topic. To demonstrate the efficacy of our proposed approach, we conduct evaluations on both widely used classification benchmark datasets and manually constructed datasets with 291 diverse topics, which simulate diverse contents encountered in real-world applications. DRAFT shows competitive or superior performance compared to baselines that use in-context learning, such as GPT-3 175B and InstructGPT 175B, on few-shot topic classification tasks despite having 177 times fewer parameters, demonstrating its effectiveness.
MEMTO: Memory-guided Transformer for Multivariate Time Series Anomaly Detection
Dec 05, 2023Detecting anomalies in real-world multivariate time series data is challenging due to complex temporal dependencies and inter-variable correlations. Recently, reconstruction-based deep models have been widely used to solve the problem. However, these methods still suffer from an over-generalization issue and fail to deliver consistently high performance. To address this issue, we propose the MEMTO, a memory-guided Transformer using a reconstruction-based approach. It is designed to incorporate a novel memory module that can learn the degree to which each memory item should be updated in response to the input data. To stabilize the training procedure, we use a two-phase training paradigm which involves using K-means clustering for initializing memory items. Additionally, we introduce a bi-dimensional deviation-based detection criterion that calculates anomaly scores considering both input space and latent space. We evaluate our proposed method on five real-world datasets from diverse domains, and it achieves an average anomaly detection F1-score of 95.74%, significantly outperforming the previous state-of-the-art methods. We also conduct extensive experiments to empirically validate the effectiveness of our proposed model's key components.
A Robotic Dating Coaching System Leveraging Online Communities Posts
Nov 24, 2020
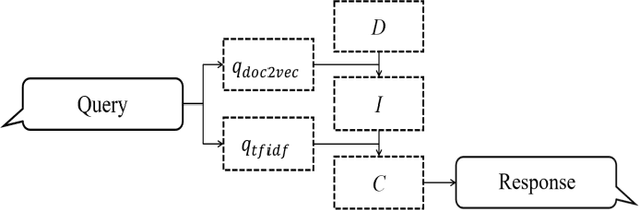
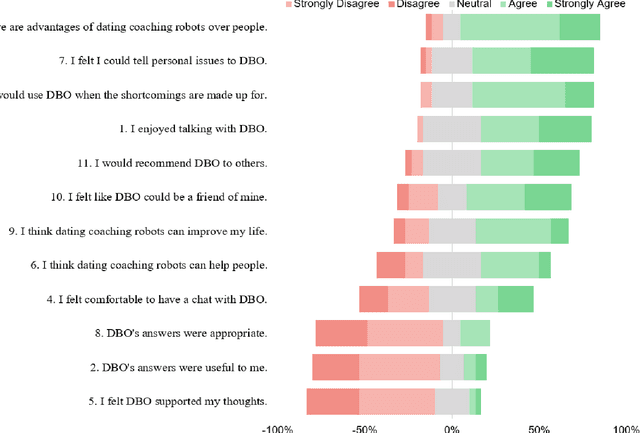
Can a robot be a personal dating coach? Even with the increasing amount of conversational data on the internet, the implementation of conversational robots remains a challenge. In particular, a detailed and professional counseling log is expensive and not publicly accessible. In this paper, we develop a robot dating coaching system leveraging corpus from online communities. We examine people's perceptions of the dating coaching robot with a dialogue module. 97 participants joined to have a conversation with the robot, and 30 of them evaluated the robot. The results indicate that participants thought the robot could become a dating coach while considering the robot is entertaining rather than helpful.
KitcheNette: Predicting and Recommending Food Ingredient Pairings using Siamese Neural Networks
May 16, 2019
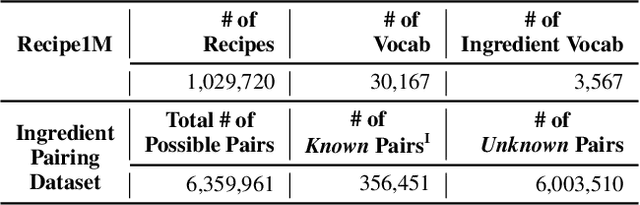
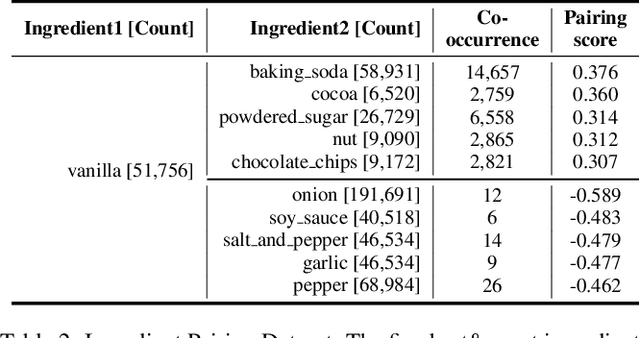
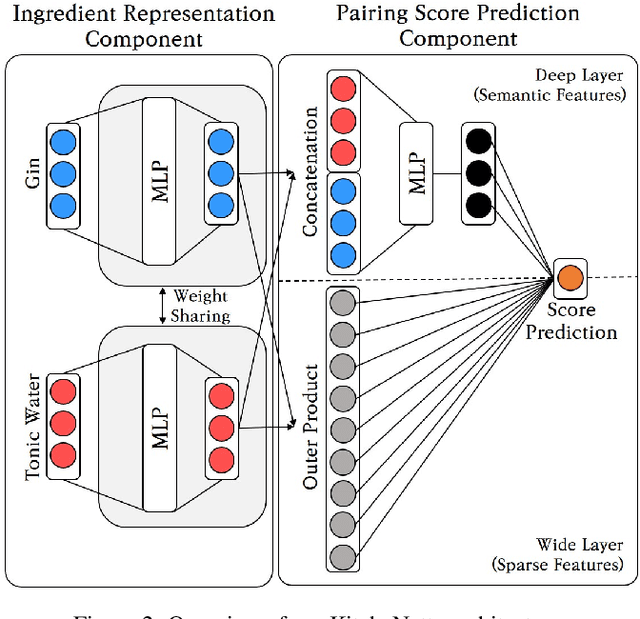
As a vast number of ingredients exist in the culinary world, there are countless food ingredient pairings, but only a small number of pairings have been adopted by chefs and studied by food researchers. In this work, we propose KitcheNette which is a model that predicts food ingredient pairing scores and recommends optimal ingredient pairings. KitcheNette employs Siamese neural networks and is trained on our annotated dataset containing 300K scores of pairings generated from numerous ingredients in food recipes. As the results demonstrate, our model not only outperforms other baseline models but also can recommend complementary food pairings and discover novel ingredient pairings.