 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRAFT: Dense Retrieval Augmented Few-shot Topic classifier Framework
Dec 05, 2023With the growing volume of diverse information, the demand for classifying arbitrary topics has become increasingly critical. To address this challenge, we introduce DRAFT, a simple framework designed to train a classifier for few-shot topic classification. DRAFT uses a few examples of a specific topic as queries to construct Customized dataset with a dense retriever model. Multi-query retrieval (MQR) algorithm, which effectively handles multiple queries related to a specific topic, is applied to construct the Customized dataset. Subsequently, we fine-tune a classifier using the Customized dataset to identify the topic. To demonstrate the efficacy of our proposed approach, we conduct evaluations on both widely used classification benchmark datasets and manually constructed datasets with 291 diverse topics, which simulate diverse contents encountered in real-world applications. DRAFT shows competitive or superior performance compared to baselines that use in-context learning, such as GPT-3 175B and InstructGPT 175B, on few-shot topic classification tasks despite having 177 times fewer parameters, demonstrating its effectiveness.
RobustSwap: A Simple yet Robust Face Swapping Model against Attribute Leakage
Mar 28, 2023Face swapping aims at injecting a source image's identity (i.e., facial features) into a target image, while strictly preserving the target's attributes, which are irrelevant to identity. However, we observed that previous approaches still suffer from source attribute leakage, where the source image's attributes interfere with the target image's. In this paper, we analyze the latent space of StyleGAN and find the adequate combination of the latents geared for face swapping task. Based on the findings, we develop a simple yet robust face swapping model, RobustSwap, which is resistant to the potential source attribute leakage. Moreover, we exploit the coordination of 3DMM's implicit and explicit information as a guidance to incorporate the structure of the source image and the precise pose of the target image. Despite our method solely utilizing an image dataset without identity labels for training, our model has the capability to generate high-fidelity and temporally consistent videos. Through extensive qualitative and quantitative evaluations, we demonstrate that our method shows significant improvements compared with the previous face swapping models in synthesizing both images and videos. Project page is available at https://robustswap.github.io/
Cross-speaker Emotion Transfer by Manipulating Speech Style Latents
Mar 15, 2023In recent years, emotional text-to-speech has shown considerable progress. However, it requires a large amount of labeled data, which is not easily accessible. Even if it is possible to acquire an emotional speech dataset, there is still a limitation in controlling emotion intensity. In this work, we propose a novel method for cross-speaker emotion transfer and manipulation using vector arithmetic in latent style space. By leveraging only a few labeled samples, we generate emotional speech from reading-style speech without losing the speaker identity. Furthermore, emotion strength is readily controllable using a scalar value, providing an intuitive way for users to manipulate speech. Experimental results show the proposed method affords superior performance in terms of expressiveness, naturalness, and controllability, preserving speaker identity.
Text-driven Emotional Style Control and Cross-speaker Style Transfer in Neural TTS
Jul 13, 2022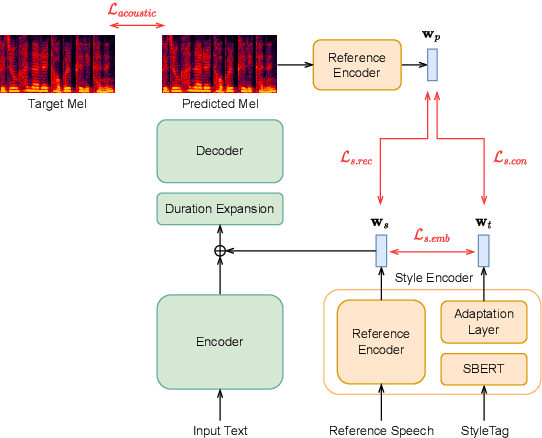
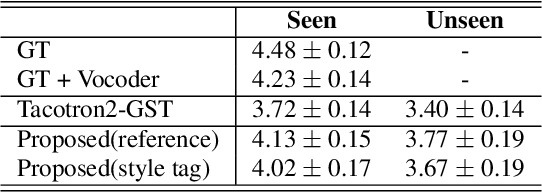

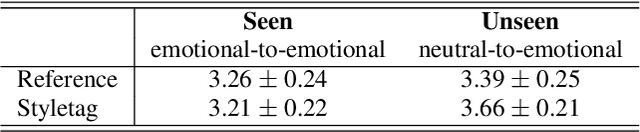
Expressive text-to-speech has shown improved performance in recent years. However, the style control of synthetic speech is often restricted to discrete emotion categories and requires training data recorded by the target speaker in the target style. In many practical situations, users may not have reference speech recorded in target emotion but still be interested in controlling speech style just by typing text description of desired emotional style. In this paper, we propose a text-based interface for emotional style control and cross-speaker style transfer in multi-speaker TTS. We propose the bi-modal style encoder which models the semantic relationship between text description embedding and speech style embedding with a pretrained language model. To further improve cross-speaker style transfer on disjoint, multi-style datasets, we propose the novel style loss. The experimental results show that our model can generate high-quality expressive speech even in unseen style.
Learning pronunciation from a foreign language in speech synthesis networks
Nov 23, 2018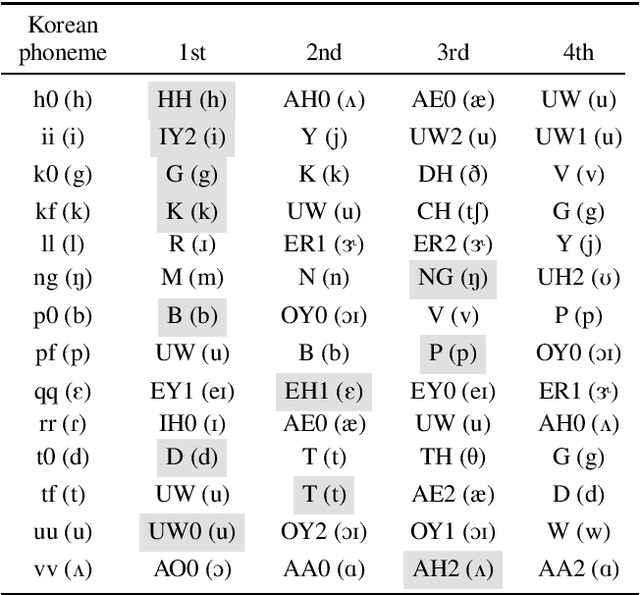

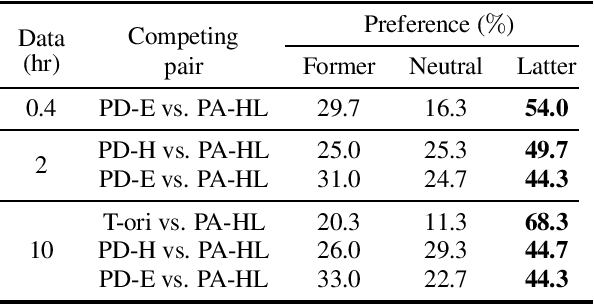
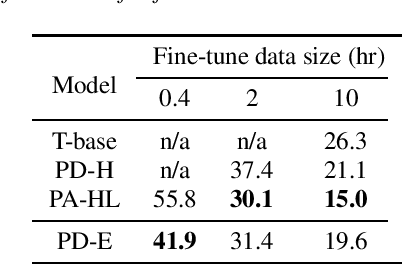
Although there are more than 65,000 languages in the world, the pronunciations of many phonemes sound similar across the languages. When people learn a foreign language, their pronunciation often reflect their native language's characteristics. That motivates us to investigate how the speech synthesis network learns the pronunciation when multi-lingual dataset is given. In this study, we train the speech synthesis network bilingually in English and Korean, and analyze how the network learns the relations of phoneme pronunciation between the languages. Our experimental result shows that the learned phoneme embedding vectors are located closer if their pronunciations are similar across the languages. Based on the result, we also show that it is possible to train networks that synthesize English speaker's Korean speech and vice versa. In another experiment, we train the network with limited amount of English dataset and large Korean dataset, and analyze the required amount of dataset to train a resource-poor language with the help of resource-rich languages.
Robust and fine-grained prosody control of end-to-end speech synthesis
Nov 06, 2018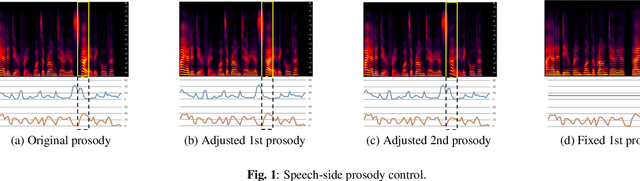

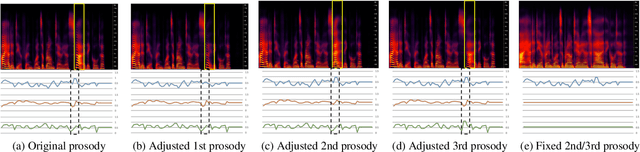

We propose prosody embeddings for emotional and expressive speech synthesis networks. The proposed methods introduce temporal structures in the embedding networks, which enable fine-grained control of the speaking style of the synthesized speech. The temporal structures could be designed either in speech-side or text-side, which lead different control resolution in time. The prosody embedding networks are plugged into end-to-end speech synthesis networks, and trained without any other supervision except the target speech for synthesizing. The prosody embedding networks learned to extract prosodic features. By adjusting the learned prosody features, we could change the pitch and amplitude of the synthesized speech both in frame level and phoneme level. We also introduce temporal normalization of prosody embeddings, which shows better robustness against speaker perturbation in prosody transfer tasks.
Emotional End-to-End Neural Speech Synthesizer
Nov 28, 2017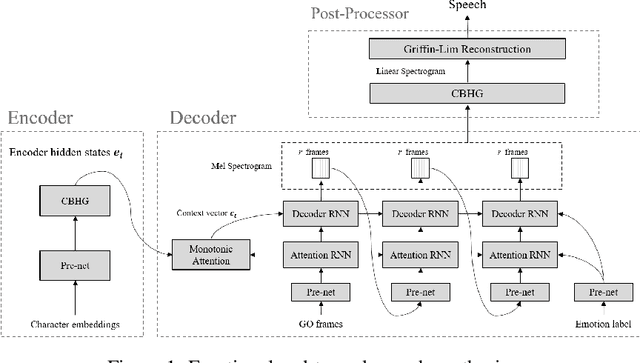
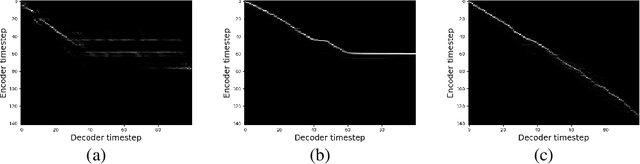
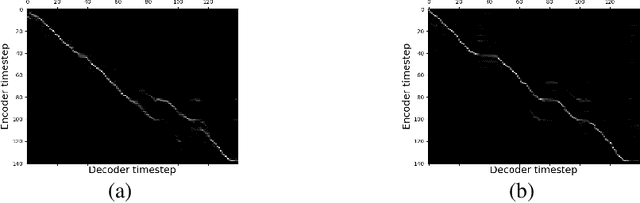
In this paper, we introduce an emotional speech synthesizer based on the recent end-to-end neural model, named Tacotron. Despite its benefits, we found that the original Tacotron suffers from the exposure bias problem and irregularity of the attention alignment. Later, we address the problem by utilization of context vector and residual connection at recurrent neural networks (RNNs). Our experiments showed that the model could successfully train and generate speech for given emotion labels.