 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-driven Emotional Style Control and Cross-speaker Style Transfer in Neural TTS
Paper and Code
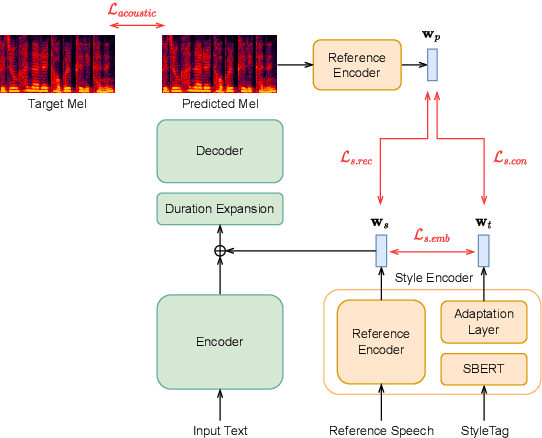
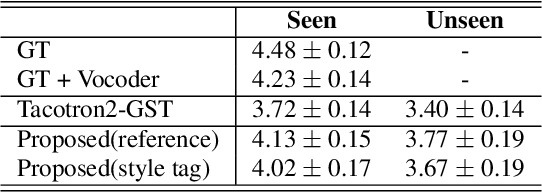

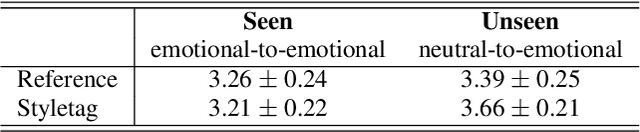
Expressive text-to-speech has shown improved performance in recent years. However, the style control of synthetic speech is often restricted to discrete emotion categories and requires training data recorded by the target speaker in the target style. In many practical situations, users may not have reference speech recorded in target emotion but still be interested in controlling speech style just by typing text description of desired emotional style. In this paper, we propose a text-based interface for emotional style control and cross-speaker style transfer in multi-speaker TTS. We propose the bi-modal style encoder which models the semantic relationship between text description embedding and speech style embedding with a pretrained language model. To further improve cross-speaker style transfer on disjoint, multi-style datasets, we propose the novel style loss. The experimental results show that our model can generate high-quality expressive speech even in unseen style.