 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion-type Identification for Academic Questions in Online Learning Platform
Nov 24, 2022Online learning platforms provide learning materials and answers to students' academic questions by experts, peers, or systems. This paper explores question-type identification as a step in content understanding for an online learning platform. The aim of the question-type identifier is to categorize question types based on their structure and complexity, using the question text, subject, and structural features. We have defined twelve question-type classes, including Multiple-Choice Question (MCQ), essay, and others. We have compiled an internal dataset of students' questions and used a combination of weak-supervision techniques and manual annotation. We then trained a BERT-based ensemble model on this dataset and evaluated this model on a separate human-labeled test set. Our experiments yielded an F1-score of 0.94 for MCQ binary classification and promising results for 12-class multilabel classification. We deployed the model in our online learning platform as a crucial enabler for content understanding to enhance the student learning experience.
A Soft Recommender System for Social Networks
Jan 08, 2020
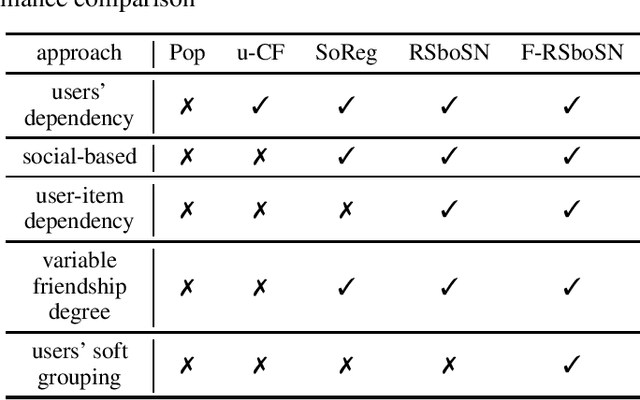

Recent social recommender systems benefit from friendship graph to make an accurate recommendation, believing that friends in a social network have exactly the same interests and preferences. Some studies have benefited from hard clustering algorithms (such as K-means) to determine the similarity between users and consequently to define degree of friendships. In this paper, we went a step further to identify true friends for making even more realistic recommendations. we calculated the similarity between users, as well as the dependency between a user and an item. Our hypothesis is that due to the uncertainties in user preferences, the fuzzy clustering, instead of the classical hard clustering, is beneficial in accurate recommendations. We incorporated the C-means algorithm to get different membership degrees of soft users' clusters. Then, the users' similarity metric is defined according to the soft clusters. Later, in a training scheme we determined the latent representations of users and items, extracting from the huge and sparse user-item-tag matrix using matrix factorization. In the parameter tuning, we found the optimum coefficients for the influence of our soft social regularization and the user-item dependency terms. Our experimental results convinced that the proposed fuzzy similarity metric improves the recommendations in real data compared to the baseline social recommender system with the hard clustering.
On the Efficiency of the Neuro-Fuzzy Classifier for User Knowledge Modeling Systems
Oct 26, 2019
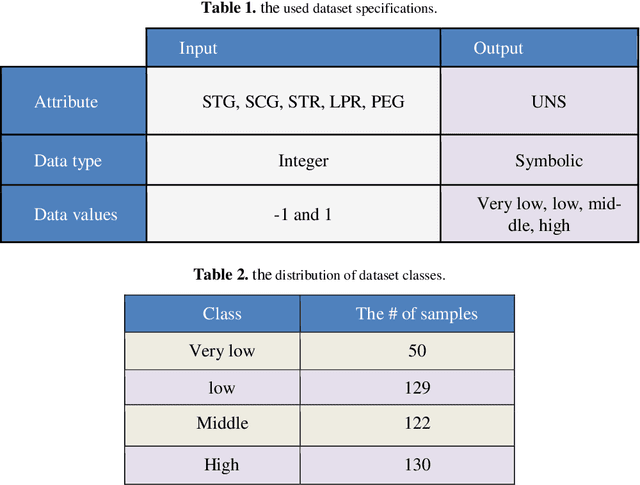

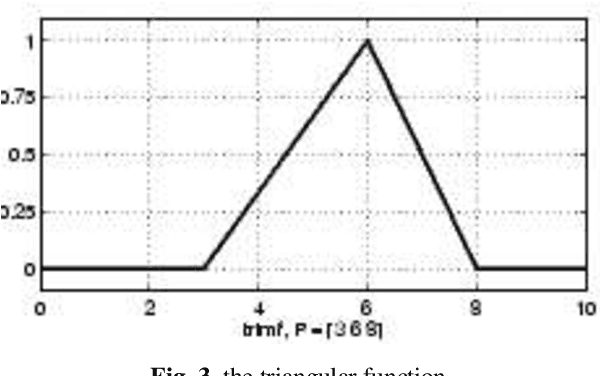
User knowledge modeling systems are used as the most effective technology for grabbing new user's attention. Moreover, the quality of service (QOS) is increased by these intelligent services. This paper proposes two user knowledge classifiers based on artificial neural networks used as one of the influential parts of knowledge modeling systems. We employed multi-layer perceptron (MLP) and adaptive neural fuzzy inference system (ANFIS) as the classifiers. Moreover, we used real data contains the user's degree of study time, repetition number, their performance in exam, as well as the learning percentage, as our classifier's inputs. Compared with well-known methods like KNN and Bayesian classifiers used in other research with the same data sets, our experiments present better performance. Although, the number of samples in the train set is not large enough, the performance of the neuro-fuzzy classifier in the test set is 98.6% which is the best result in comparison with others. However, the comparison of MLP toward the ANFIS results presents performance reduction, although the MLP performance is more efficient than other methods like Bayesian and KNN. As our goal is evaluating and reporting the efficiency of a neuro-fuzzy classifier for user knowledge modeling systems, we utilized many different evaluation metrics such as Receiver Operating Characteristic and the Area Under its Curve, Total Accuracy, and Kappa statistics.
D-Point Trigonometric Path Planning based on Q-Learning in Uncertain Environments
Oct 26, 2019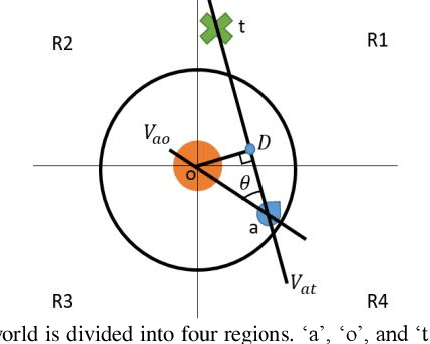
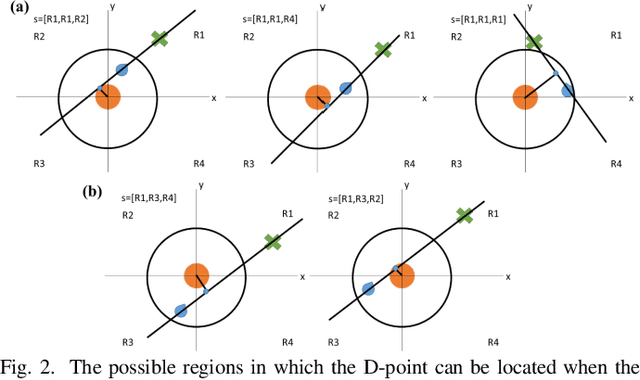

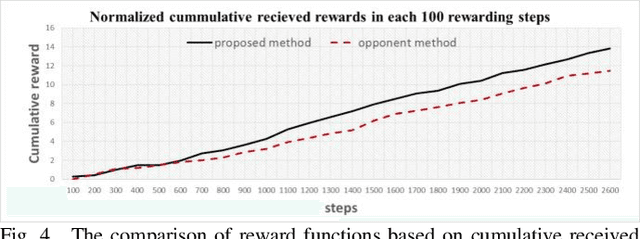
Finding the optimum path for a robot for moving from start to the goal position through obstacles is still a challenging issue. This paper presents a novel path planning method, named D-point trigonometric, based on Q-learning algorithm for dynamic and uncertain environments, in which all the obstacles and the target are moving. We define a new state, action and reward functions for the Q-learning by which the agent can find the best action in every state to reach the goal in the most appropriate path. The D-point approach minimizes the possible number of states. Moreover, the experiments in Unity3D confirmed the high convergence speed, the high hit rate, as well as the low dependency on environmental parameters of the proposed method compared with an opponent approach.
Emotional End-to-End Neural Speech Synthesizer
Nov 28, 2017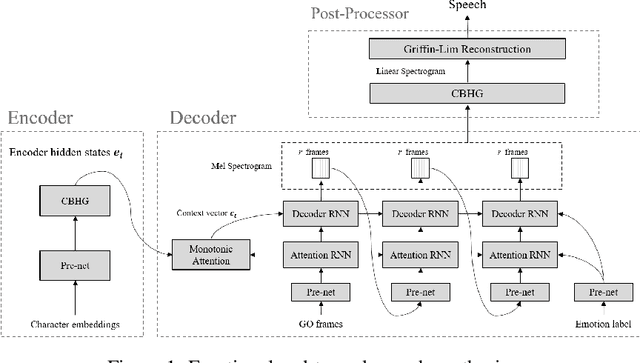
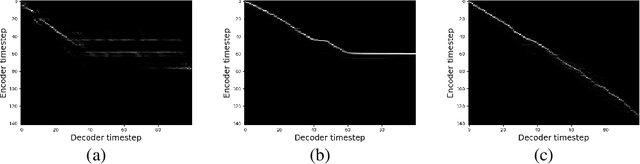
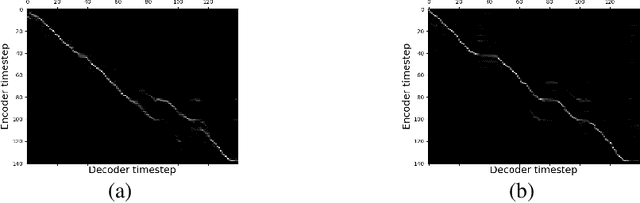
In this paper, we introduce an emotional speech synthesizer based on the recent end-to-end neural model, named Tacotron. Despite its benefits, we found that the original Tacotron suffers from the exposure bias problem and irregularity of the attention alignment. Later, we address the problem by utilization of context vector and residual connection at recurrent neural networks (RNNs). Our experiments showed that the model could successfully train and generate speech for given emotion labels.