 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Soft Recommender System for Social Networks
Jan 08, 2020
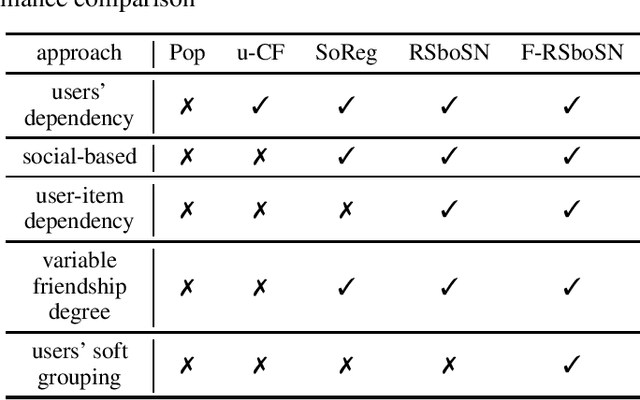

Recent social recommender systems benefit from friendship graph to make an accurate recommendation, believing that friends in a social network have exactly the same interests and preferences. Some studies have benefited from hard clustering algorithms (such as K-means) to determine the similarity between users and consequently to define degree of friendships. In this paper, we went a step further to identify true friends for making even more realistic recommendations. we calculated the similarity between users, as well as the dependency between a user and an item. Our hypothesis is that due to the uncertainties in user preferences, the fuzzy clustering, instead of the classical hard clustering, is beneficial in accurate recommendations. We incorporated the C-means algorithm to get different membership degrees of soft users' clusters. Then, the users' similarity metric is defined according to the soft clusters. Later, in a training scheme we determined the latent representations of users and items, extracting from the huge and sparse user-item-tag matrix using matrix factorization. In the parameter tuning, we found the optimum coefficients for the influence of our soft social regularization and the user-item dependency terms. Our experimental results convinced that the proposed fuzzy similarity metric improves the recommendations in real data compared to the baseline social recommender system with the hard clustering.