 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-speaker Emotional Text-to-speech Synthesizer
Dec 07, 2021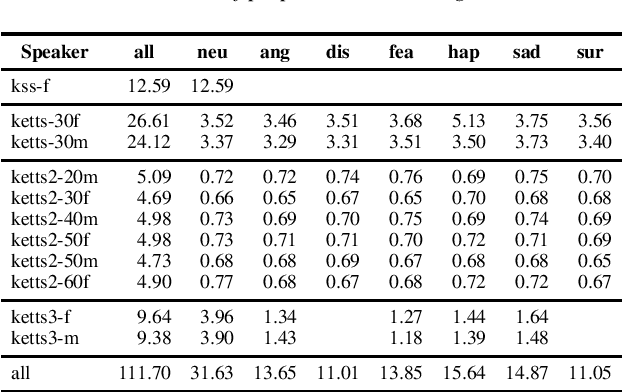
We present a methodology to train our multi-speaker emotional text-to-speech synthesizer that can express speech for 10 speakers' 7 different emotions. All silences from audio samples are removed prior to learning. This results in fast learning by our model. Curriculum learning is applied to train our model efficiently. Our model is first trained with a large single-speaker neutral dataset, and then trained with neutral speech from all speakers. Finally, our model is trained using datasets of emotional speech from all speakers. In each stage, training samples of each speaker-emotion pair have equal probability to appear in mini-batches. Through this procedure, our model can synthesize speech for all targeted speakers and emotions. Our synthesized audio sets are available on our web page.
* 2 pages; Published in the Proceedings of Interspeech 2021; Presented in Show and Tell; For the published paper, see https://www.isca-speech.org/archive/interspeech_2021/cho21_interspeech.html
Unigram-Normalized Perplexity as a Language Model Performance Measure with Different Vocabulary Sizes
Nov 26, 2020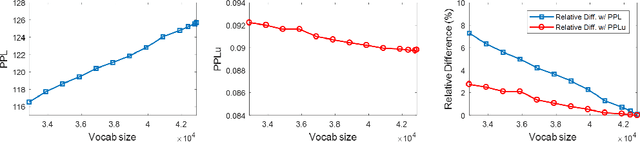


Although Perplexity is a widely used performance metric for language models, the values are highly dependent upon the number of words in the corpus and is useful to compare performance of the same corpus only. In this paper, we propose a new metric that can be used to evaluate language model performance with different vocabulary sizes. The proposed unigram-normalized Perplexity actually presents the performance improvement of the language models from that of simple unigram model, and is robust on the vocabulary size. Both theoretical analysis and computational experiments are reported.
Hierarchical GPT with Congruent Transformers for Multi-Sentence Language Models
Sep 18, 2020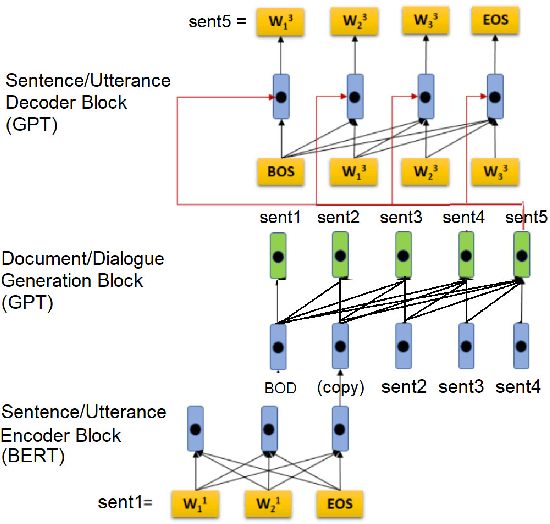
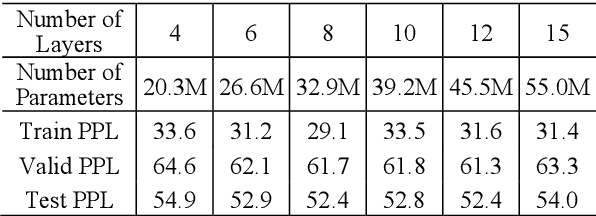
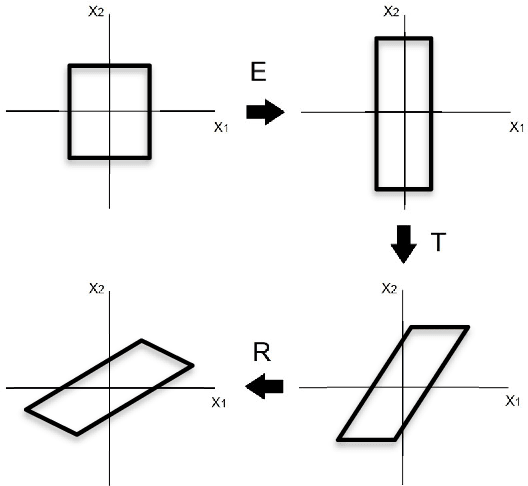
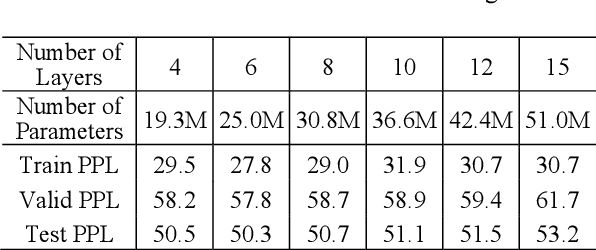
We report a GPT-based multi-sentence language model for dialogue generation and document understanding. First, we propose a hierarchical GPT which consists of three blocks, i.e., a sentence encoding block, a sentence generating block, and a sentence decoding block. The sentence encoding and decoding blocks are basically the encoder-decoder blocks of the standard Transformers, which work on each sentence independently. The sentence generating block is inserted between the encoding and decoding blocks, and generates the next sentence embedding vector from the previous sentence embedding vectors. We believe it is the way human make conversation and understand paragraphs and documents. Since each sentence may consist of fewer words, the sentence encoding and decoding Transformers can use much smaller dimensional embedding vectors. Secondly, we note the attention in the Transformers utilizes the inner-product similarity measure. Therefore, to compare the two vectors in the same space, we set the transform matrices for queries and keys to be the same. Otherwise, the similarity concept is incongruent. We report experimental results to show that these two modifications increase the language model performance for tasks with multiple sentences.
Semi-supervised Disentanglement with Independent Vector Variational Autoencoders
Mar 14, 2020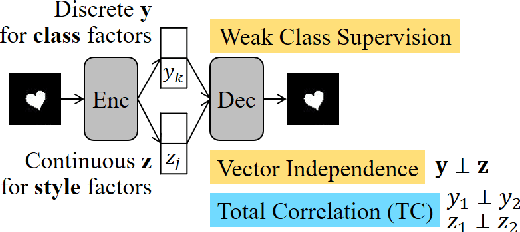
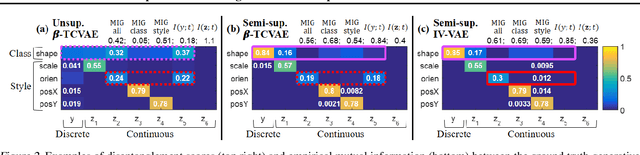

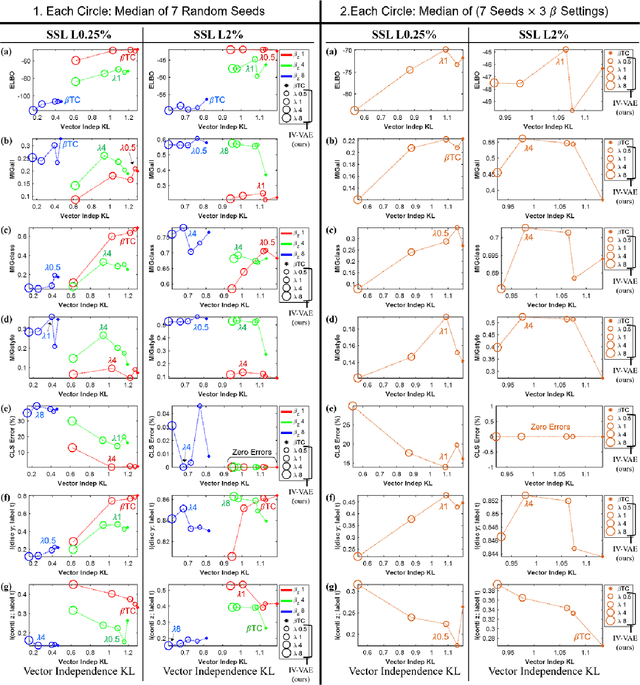
We aim to separate the generative factors of data into two latent vectors in a variational autoencoder. One vector captures class factors relevant to target classification tasks, while the other vector captures style factors relevant to the remaining information. To learn the discrete class features, we introduce supervision using a small amount of labeled data, which can simply yet effectively reduce the effort required for hyperparameter tuning performed in existing unsupervised methods. Furthermore, we introduce a learning objective to encourage statistical independence between the vectors. We show that (i) this vector independence term exists within the result obtained on decomposing the evidence lower bound with multiple latent vectors, and (ii) encouraging such independence along with reducing the total correlation within the vectors enhances disentanglement performance. Experiments conducted on several image datasets demonstrate that the disentanglement achieved via our method can improve classification performance and generation controllability.
Emotional Voice Conversion using Multitask Learning with Text-to-speech
Nov 27, 2019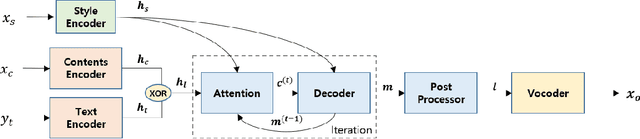

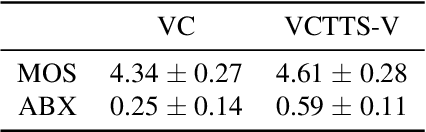
Voice conversion (VC) is a task to transform a person's voice to different style while conserving linguistic contents. Previous state-of-the-art on VC is based on sequence-to-sequence (seq2seq) model, which could mislead linguistic information. There was an attempt to overcome it by using textual supervision, it requires explicit alignment which loses the benefit of using seq2seq model. In this paper, a voice converter using multitask learning with text-to-speech (TTS) is presented. The embedding space of seq2seq-based TTS has abundant information on the text. The role of the decoder of TTS is to convert embedding space to speech, which is same to VC. In the proposed model, the whole network is trained to minimize loss of VC and TTS. VC is expected to capture more linguistic information and to preserve training stability by multitask learning. Experiments of VC were performed on a male Korean emotional text-speech dataset, and it is shown that multitask learning is helpful to keep linguistic contents in VC.
Unpaired Speech Enhancement by Acoustic and Adversarial Supervision for Speech Recognition
Nov 06, 2018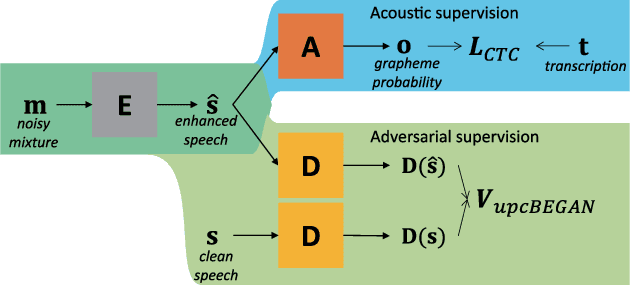
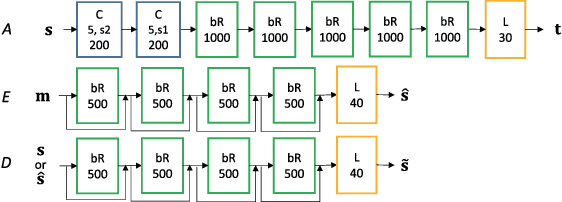

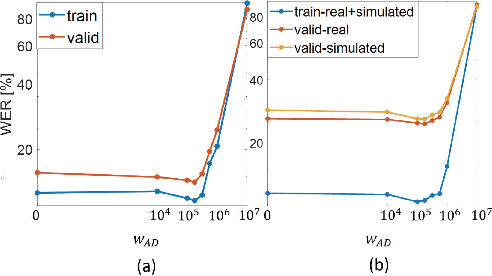
Many speech enhancement methods try to learn the relationship between noisy and clean speech, obtained using an acoustic room simulator. We point out several limitations of enhancement methods relying on clean speech targets; the goal of this work is proposing an alternative learning algorithm, called acoustic and adversarial supervision (AAS). AAS makes the enhanced output both maximizing the likelihood of transcription on the pre-trained acoustic model and having general characteristics of clean speech, which improve generalization on unseen noisy speeches. We employ the connectionist temporal classification and the unpaired conditional boundary equilibrium generative adversarial network as the loss function of AAS. AAS is tested on two datasets including additive noise without and with reverberation, Librispeech + DEMAND and CHiME-4. By visualizing the enhanced speech with different loss combinations, we demonstrate the role of each supervision. AAS achieves a lower word error rate than other state-of-the-art methods using the clean speech target in both datasets.
End-to-end Multimodal Emotion and Gender Recognition with Dynamic Joint Loss Weights
Oct 02, 2018


Multi-task learning is a method for improving the generalizability of multiple tasks. In order to perform multiple classification tasks with one neural network model, the losses of each task should be combined. Previous studies have mostly focused on multiple prediction tasks using joint loss with static weights for training models, choosing the weights between tasks without making sufficient considerations by setting them uniformly or empirically. In this study, we propose a method to calculate joint loss using dynamic weights to improve the total performance, instead of the individual performance, of tasks. We apply this method to design an end-to-end multimodal emotion and gender recognition model using audio and video data. This approach provides proper weights for the loss of each task when the training process ends. In our experiments, emotion and gender recognition with the proposed method yielded a lower joint loss, which is computed as the negative log-likelihood, than using static weights for joint loss. Moreover, our proposed model has better generalizability than other models. To the best of our knowledge, this research is the first to demonstrate the strength of using dynamic weights for joint loss for maximizing overall performance in emotion and gender recognition tasks.
Emotional End-to-End Neural Speech Synthesizer
Nov 28, 2017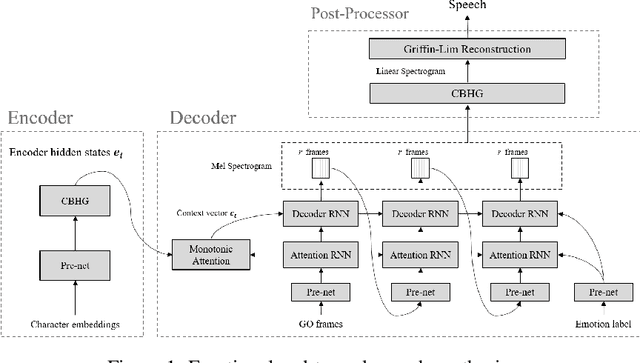
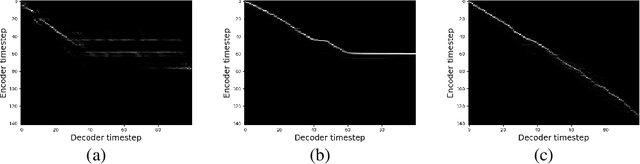
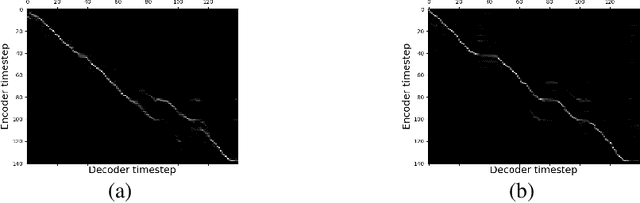
In this paper, we introduce an emotional speech synthesizer based on the recent end-to-end neural model, named Tacotron. Despite its benefits, we found that the original Tacotron suffers from the exposure bias problem and irregularity of the attention alignment. Later, we address the problem by utilization of context vector and residual connection at recurrent neural networks (RNNs). Our experiments showed that the model could successfully train and generate speech for given emotion labels.
Deep CNNs along the Time Axis with Intermap Pooling for Robustness to Spectral Variations
Jul 12, 2016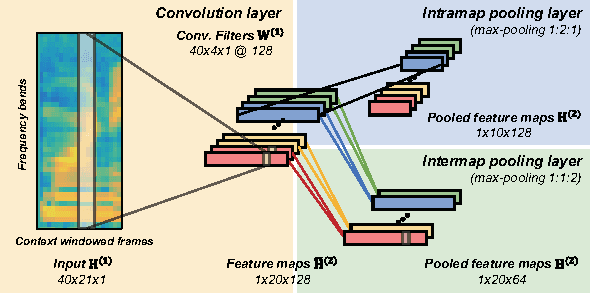
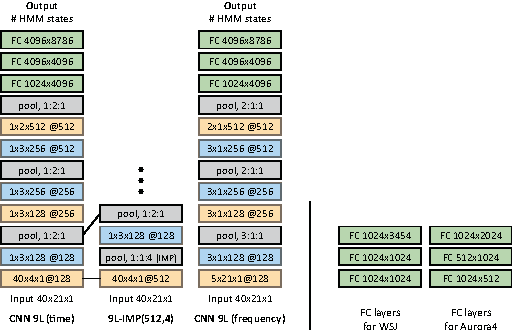
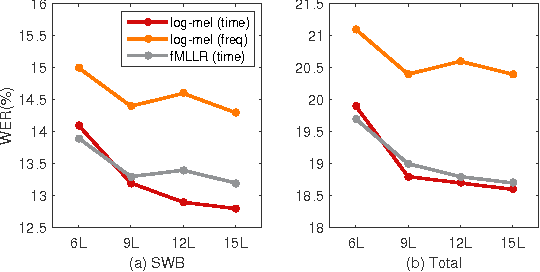
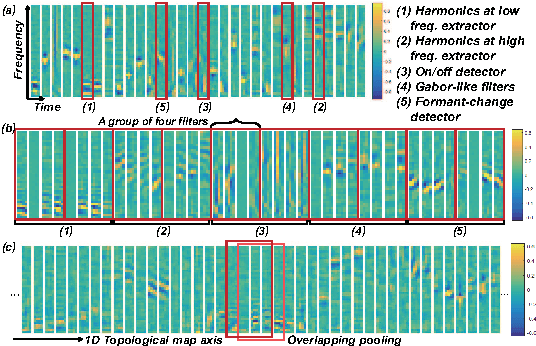
Convolutional neural networks (CNNs) with convolutional and pooling operations along the frequency axis have been proposed to attain invariance to frequency shifts of features. However, this is inappropriate with regard to the fact that acoustic features vary in frequency. In this paper, we contend that convolution along the time axis is more effective. We also propose the addition of an intermap pooling (IMP) layer to deep CNNs. In this layer, filters in each group extract common but spectrally variant features, then the layer pools the feature maps of each group. As a result, the proposed IMP CNN can achieve insensitivity to spectral variations characteristic of different speakers and utterances. The effectiveness of the IMP CNN architecture is demonstrated on several LVCSR tasks. Even without speaker adaptation techniques, the architecture achieved a WER of 12.7% on the SWB part of the Hub5'2000 evaluation test set, which is competitive with other state-of-the-art methods.
Hierarchical Data Representation Model - Multi-layer NMF
Mar 18, 2013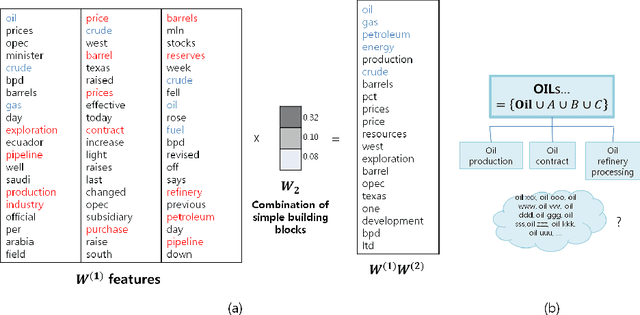
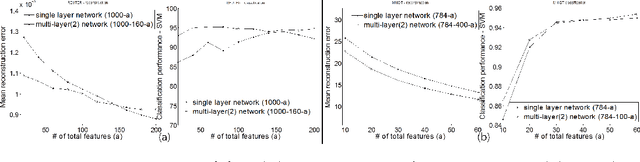
In this paper, we propose a data representation model that demonstrates hierarchical feature learning using nsNMF. We extend unit algorithm into several layers. Experiments with document and image data successfully discovered feature hierarchies. We also prove that proposed method results in much better classification and reconstruction performance, especially for small number of features. feature hierarchies.