 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Practical Approach for Building Production-Grade Conversational Agents with Workflow Graphs
May 29, 2025The advancement of Large Language Models (LLMs) has led to significant improvements in various service domains, including search, recommendation, and chatbot applications. However, applying state-of-the-art (SOTA) research to industrial settings presents challenges, as it requires maintaining flexible conversational abilities while also strictly complying with service-specific constraints. This can be seen as two conflicting requirements due to the probabilistic nature of LLMs. In this paper, we propose our approach to addressing this challenge and detail the strategies we employed to overcome their inherent limitations in real-world applications. We conduct a practical case study of a conversational agent designed for the e-commerce domain, detailing our implementation workflow and optimizations. Our findings provide insights into bridging the gap between academic research and real-world application, introducing a framework for developing scalable, controllable, and reliable AI-driven agents.
Unigram-Normalized Perplexity as a Language Model Performance Measure with Different Vocabulary Sizes
Nov 26, 2020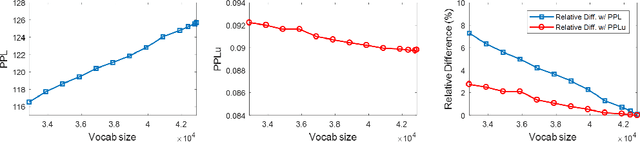


Although Perplexity is a widely used performance metric for language models, the values are highly dependent upon the number of words in the corpus and is useful to compare performance of the same corpus only. In this paper, we propose a new metric that can be used to evaluate language model performance with different vocabulary sizes. The proposed unigram-normalized Perplexity actually presents the performance improvement of the language models from that of simple unigram model, and is robust on the vocabulary size. Both theoretical analysis and computational experiments are reported.
Hierarchical GPT with Congruent Transformers for Multi-Sentence Language Models
Sep 18, 2020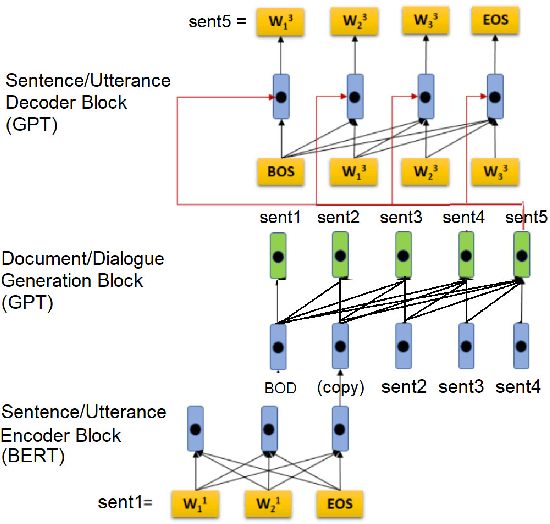
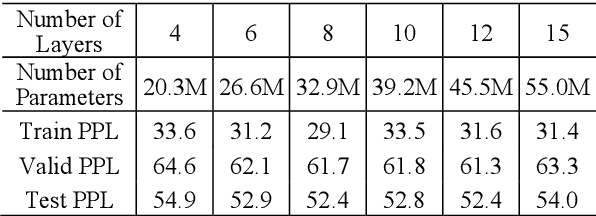
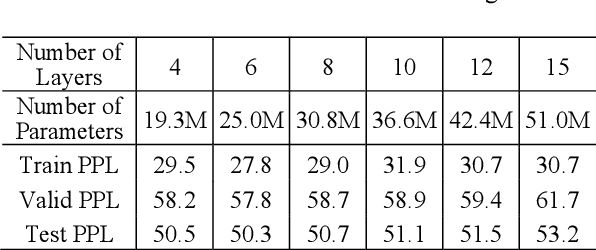
We report a GPT-based multi-sentence language model for dialogue generation and document understanding. First, we propose a hierarchical GPT which consists of three blocks, i.e., a sentence encoding block, a sentence generating block, and a sentence decoding block. The sentence encoding and decoding blocks are basically the encoder-decoder blocks of the standard Transformers, which work on each sentence independently. The sentence generating block is inserted between the encoding and decoding blocks, and generates the next sentence embedding vector from the previous sentence embedding vectors. We believe it is the way human make conversation and understand paragraphs and documents. Since each sentence may consist of fewer words, the sentence encoding and decoding Transformers can use much smaller dimensional embedding vectors. Secondly, we note the attention in the Transformers utilizes the inner-product similarity measure. Therefore, to compare the two vectors in the same space, we set the transform matrices for queries and keys to be the same. Otherwise, the similarity concept is incongruent. We report experimental results to show that these two modifications increase the language model performance for tasks with multiple sentences.