 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Practical Approach for Building Production-Grade Conversational Agents with Workflow Graphs
May 29, 2025The advancement of Large Language Models (LLMs) has led to significant improvements in various service domains, including search, recommendation, and chatbot applications. However, applying state-of-the-art (SOTA) research to industrial settings presents challenges, as it requires maintaining flexible conversational abilities while also strictly complying with service-specific constraints. This can be seen as two conflicting requirements due to the probabilistic nature of LLMs. In this paper, we propose our approach to addressing this challenge and detail the strategies we employed to overcome their inherent limitations in real-world applications. We conduct a practical case study of a conversational agent designed for the e-commerce domain, detailing our implementation workflow and optimizations. Our findings provide insights into bridging the gap between academic research and real-world application, introducing a framework for developing scalable, controllable, and reliable AI-driven agents.
Practical and Reproducible Symbolic Music Generation by Large Language Models with Structural Embeddings
Jul 29, 2024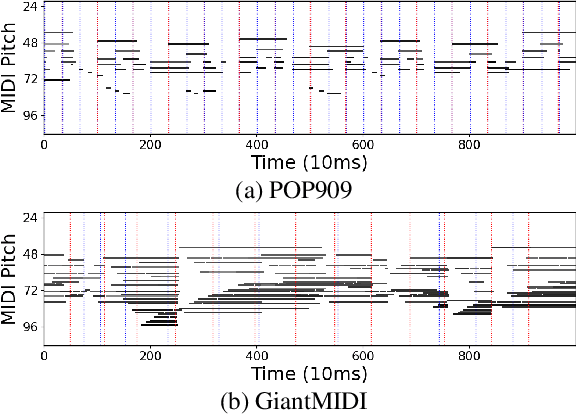
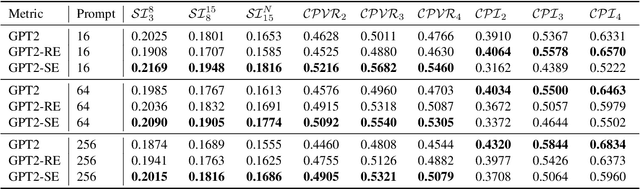
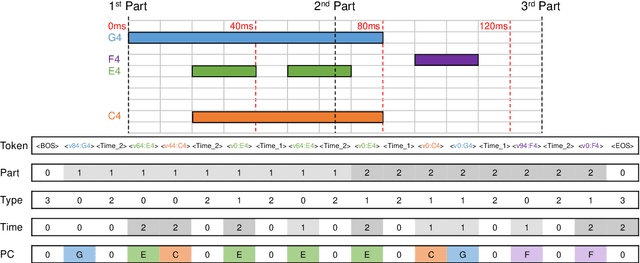

Music generation introduces challenging complexities to large language models. Symbolic structures of music often include vertical harmonization as well as horizontal counterpoint, urging various adaptations and enhancements for large-scale Transformers. However, existing works share three major drawbacks: 1) their tokenization requires domain-specific annotations, such as bars and beats, that are typically missing in raw MIDI data; 2) the pure impact of enhancing token embedding methods is hardly examined without domain-specific annotations; and 3) existing works to overcome the aforementioned drawbacks, such as MuseNet, lack reproducibility. To tackle such limitations, we develop a MIDI-based music generation framework inspired by MuseNet, empirically studying two structural embeddings that do not rely on domain-specific annotations. We provide various metrics and insights that can guide suitable encoding to deploy. We also verify that multiple embedding configurations can selectively boost certain musical aspects. By providing open-source implementations via HuggingFace, our findings shed light on leveraging large language models toward practical and reproducible music generation.
A Technical Report for Polyglot-Ko: Open-Source Large-Scale Korean Language Models
Jun 06, 2023Polyglot is a pioneering project aimed at enhancing the non-English language performance of multilingual language models. Despite the availability of various multilingual models such as mBERT (Devlin et al., 2019), XGLM (Lin et al., 2022), and BLOOM (Scao et al., 2022), researchers and developers often resort to building monolingual models in their respective languages due to the dissatisfaction with the current multilingual models non-English language capabilities. Addressing this gap, we seek to develop advanced multilingual language models that offer improved performance in non-English languages. In this paper, we introduce the Polyglot Korean models, which represent a specific focus rather than being multilingual in nature. In collaboration with TUNiB, our team collected 1.2TB of Korean data meticulously curated for our research journey. We made a deliberate decision to prioritize the development of Korean models before venturing into multilingual models. This choice was motivated by multiple factors: firstly, the Korean models facilitated performance comparisons with existing multilingual models; and finally, they catered to the specific needs of Korean companies and researchers. This paper presents our work in developing the Polyglot Korean models, which propose some steps towards addressing the non-English language performance gap in multilingual language models.
APEACH: Attacking Pejorative Expressions with Analysis on Crowd-Generated Hate Speech Evaluation Datasets
Feb 25, 2022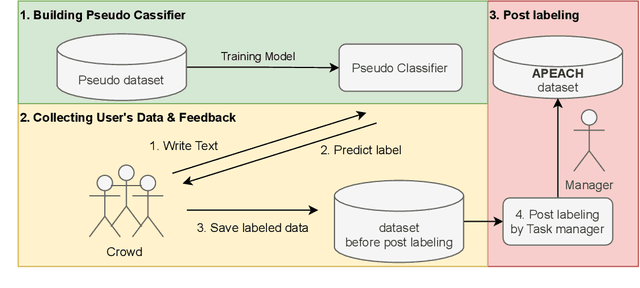
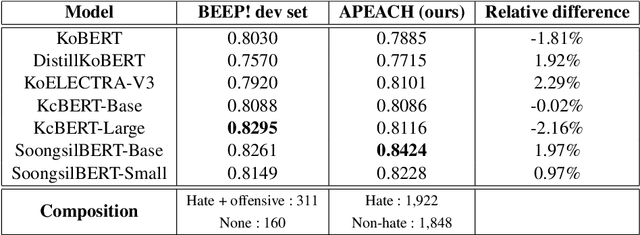
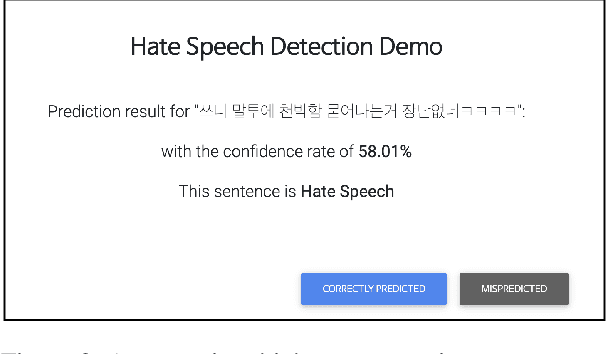
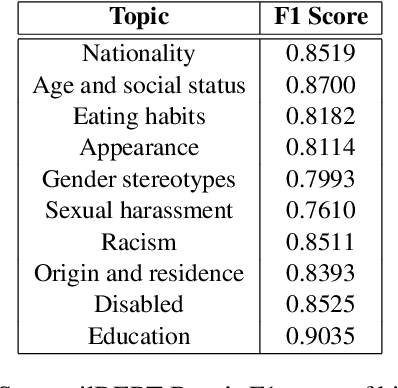
Detecting toxic or pejorative expressions in online communities has become one of the main concerns for preventing the users' mental harm. This led to the development of large-scale hate speech detection datasets of various domains, which are mainly built upon web-crawled texts with labels by crowd workers. However, for languages other than English, researchers might have to rely on only a small-sized corpus due to the lack of data-driven research of hate speech detection. This sometimes misleads the evaluation of prevalently used pretrained language models (PLMs) such as BERT, given that PLMs often share the domain of pretraining corpus with the evaluation set, resulting in over-representation of the detection performance. Also, the scope of pejorative expressions might be restricted if the dataset is built on a single domain text. To alleviate the above problems in Korean hate speech detection, we propose APEACH,a method that allows the collection of hate speech generated by unspecified users. By controlling the crowd-generation of hate speech and adding only a minimum post-labeling, we create a corpus that enables the generalizable and fair evaluation of hate speech detection regarding text domain and topic. We Compare our outcome with prior work on an annotation-based toxic news comment dataset using publicly available PLMs. We check that our dataset is less sensitive to the lexical overlap between the evaluation set and pretraining corpus of PLMs, showing that it helps mitigate the unexpected under/over-representation of model performance. We distribute our dataset publicly online to further facilitate the general-domain hate speech detection in Korean.
Transformer-based Korean Pretrained Language Models: A Survey on Three Years of Progress
Nov 25, 2021
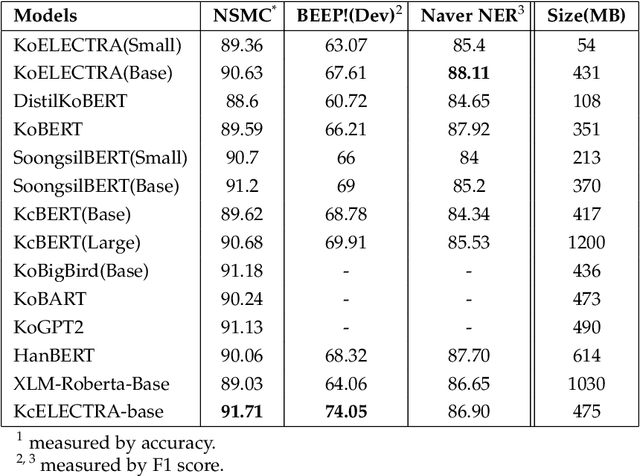
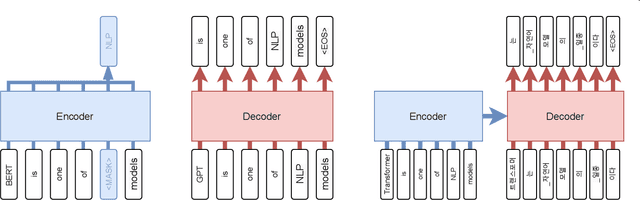
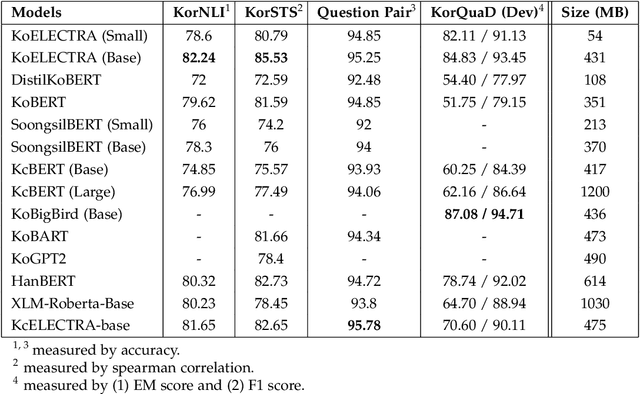
With the advent of Transformer, which was used in translation models in 2017, attention-based architectures began to attract attention. Furthermore, after the emergence of BERT, which strengthened the NLU-specific encoder part, which is a part of the Transformer, and the GPT architecture, which strengthened the NLG-specific decoder part, various methodologies, data, and models for learning the Pretrained Language Model began to appear. Furthermore, in the past three years, various Pretrained Language Models specialized for Korean have appeared. In this paper, we intend to numerically and qualitatively compare and analyze various Korean PLMs released to the public.
Revisiting Modularized Multilingual NMT to Meet Industrial Demands
Oct 19, 2020
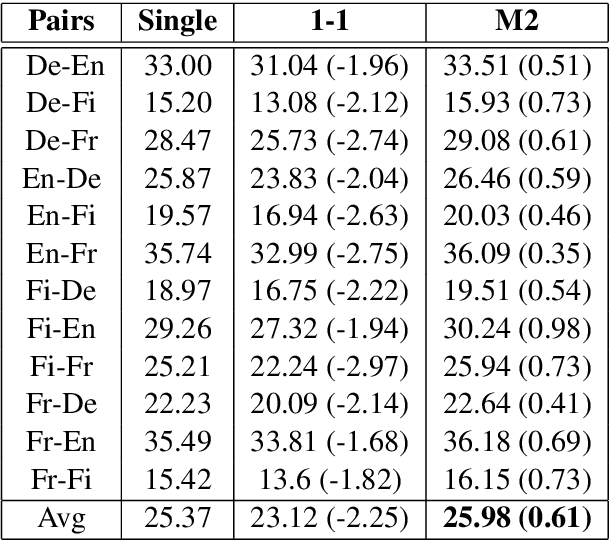
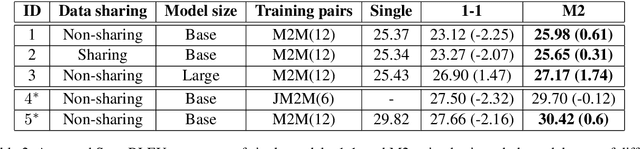
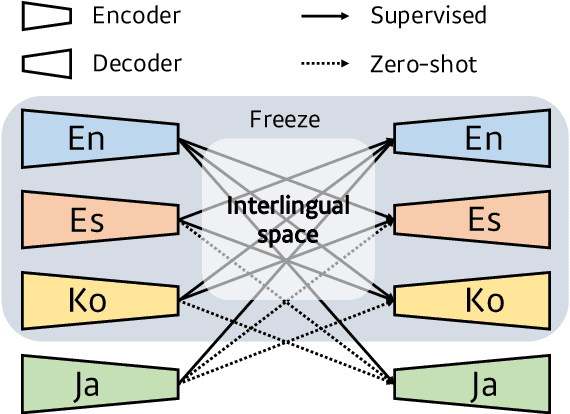
The complete sharing of parameters for multilingual translation (1-1) has been the mainstream approach in current research. However, degraded performance due to the capacity bottleneck and low maintainability hinders its extensive adoption in industries. In this study, we revisit the multilingual neural machine translation model that only share modules among the same languages (M2) as a practical alternative to 1-1 to satisfy industrial requirements. Through comprehensive experiments, we identify the benefits of multi-way training and demonstrate that the M2 can enjoy these benefits without suffering from the capacity bottleneck. Furthermore, the interlingual space of the M2 allows convenient modification of the model. By leveraging trained modules, we find that incrementally added modules exhibit better performance than singly trained models. The zero-shot performance of the added modules is even comparable to supervised models. Our findings suggest that the M2 can be a competent candidate for multilingual translation in industries.