 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Multi-Robot Motion Planning via Diffusion Modeling with Multi-Agent Reinforcement Learning Guidance
May 30, 2026Coordinating multiple robots in shared environments requires generating feasible trajectories for each agent while accounting for interactions among agents. Centralized planning approaches become difficult to scale as the number of robots increases, while decentralized approaches that allow each agent to plan independently do not inherently account for inter-agent interactions. This paper presents a framework for coordinated multi-robot motion planning that combines decentralized generative trajectory planning with multi-agent reinforcement learning (MARL)-based coordination. Each robot independently generates candidate trajectories using a diffusion model trained on single-agent motion data, leveraging the generative model's ability to produce feasible and diverse trajectories. To reduce conflicts between agents, a centralized value function trained via MARL guides the reverse diffusion process through gradient-based steering, enabling interaction-aware trajectory generation without centralized joint planning or retraining of the generative model. This guidance follows an exponential tilting formulation, in which the value function biases the denoising distribution toward trajectories with higher expected multi-agent return. The framework is evaluated in a simulated maze environment with four mobile robots. Experimental results show that the proposed value-guided diffusion planning reduces the inter-agent interference rate from 55.4% to 41.8%, demonstrating that coordination can be effectively achieved while preserving the scalability of decentralized trajectory generation. These results suggest that MARL-based value guidance can effectively introduce coordination into decentralized generative planners without requiring a fully joint multi-robot model.
MP-GFormer: A 3D-Geometry-Aware Dynamic Graph Transformer Approach for Machining Process Planning
Nov 14, 2025Machining process planning (MP) is inherently complex due to structural and geometrical dependencies among part features and machining operations. A key challenge lies in capturing dynamic interdependencies that evolve with distinct part geometries as operations are performed. Machine learning has been applied to address challenges in MP, such as operation selection and machining sequence prediction. Dynamic graph learning (DGL) has been widely used to model dynamic systems, thanks to its ability to integrate spatio-temporal relationships. However, in MP, while existing DGL approaches can capture these dependencies, they fail to incorporate three-dimensional (3D) geometric information of parts and thus lack domain awareness in predicting machining operation sequences. To address this limitation, we propose MP-GFormer, a 3D-geometry-aware dynamic graph transformer that integrates evolving 3D geometric representations into DGL through an attention mechanism to predict machining operation sequences. Our approach leverages StereoLithography surface meshes representing the 3D geometry of a part after each machining operation, with the boundary representation method used for the initial 3D designs. We evaluate MP-GFormer on a synthesized dataset and demonstrate that the method achieves improvements of 24\% and 36\% in accuracy for main and sub-operation predictions, respectively, compared to state-of-the-art approaches.
A Domain Adaptation of Large Language Models for Classifying Mechanical Assembly Components
May 02, 2025



The conceptual design phase represents a critical early stage in the product development process, where designers generate potential solutions that meet predefined design specifications based on functional requirements. Functional modeling, a foundational aspect of this phase, enables designers to reason about product functions before specific structural details are determined. A widely adopted approach to functional modeling is the Function-Behavior-Structure (FBS) framework, which supports the transformation of functional intent into behavioral and structural descriptions. However, the effectiveness of function-based design is often hindered by the lack of well-structured and comprehensive functional data. This scarcity can negatively impact early design decision-making and hinder the development of accurate behavioral models. Recent advances in Large Language Models (LLMs), such as those based on GPT architectures, offer a promising avenue to address this gap. LLMs have demonstrated significant capabilities in language understanding and natural language processing (NLP), making them suitable for automated classification tasks. This study proposes a novel LLM-based domain adaptation (DA) framework using fine-tuning for the automated classification of mechanical assembly parts' functions. By fine-tuning LLMs on domain-specific datasets, the traditionally manual and subjective process of function annotation can be improved in both accuracy and consistency. A case study demonstrates fine-tuning GPT-3.5 Turbo on data from the Oregon State Design Repository (OSDR), and evaluation on the A Big CAD (ABC) dataset shows that the domain-adapted LLM can generate high-quality functional data, enhancing the semantic representation of mechanical parts and supporting more effective design exploration in early-phase engineering.
Generative Machine Learning in Adaptive Control of Dynamic Manufacturing Processes: A Review
Apr 30, 2025
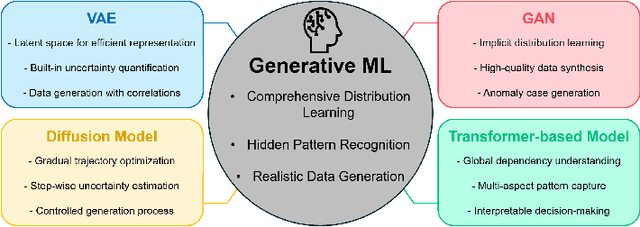
Dynamic manufacturing processes exhibit complex characteristics defined by time-varying parameters, nonlinear behaviors, and uncertainties. These characteristics require sophisticated in-situ monitoring techniques utilizing multimodal sensor data and adaptive control systems that can respond to real-time feedback while maintaining product quality. Recently, generative machine learning (ML) has emerged as a powerful tool for modeling complex distributions and generating synthetic data while handling these manufacturing uncertainties. However, adopting these generative technologies in dynamic manufacturing systems lacks a functional control-oriented perspective to translate their probabilistic understanding into actionable process controls while respecting constraints. This review presents a functional classification of Prediction-Based, Direct Policy, Quality Inference, and Knowledge-Integrated approaches, offering a perspective for understanding existing ML-enhanced control systems and incorporating generative ML. The analysis of generative ML architectures within this framework demonstrates control-relevant properties and potential to extend current ML-enhanced approaches where conventional methods prove insufficient. We show generative ML's potential for manufacturing control through decision-making applications, process guidance, simulation, and digital twins, while identifying critical research gaps: separation between generation and control functions, insufficient physical understanding of manufacturing phenomena, and challenges adapting models from other domains. To address these challenges, we propose future research directions aimed at developing integrated frameworks that combine generative ML and control technologies to address the dynamic complexities of modern manufacturing systems.
Kanana: Compute-efficient Bilingual Language Models
Feb 26, 2025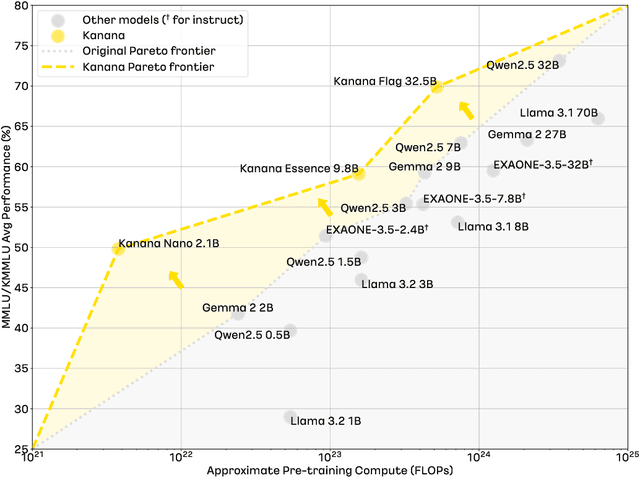



We introduce Kanana, a series of bilingual language models that demonstrate exceeding performance in Korean and competitive performance in English. The computational cost of Kanana is significantly lower than that of state-of-the-art models of similar size. The report details the techniques employed during pre-training to achieve compute-efficient yet competitive models, including high quality data filtering, staged pre-training, depth up-scaling, and pruning and distillation. Furthermore, the report outlines the methodologies utilized during the post-training of the Kanana models, encompassing supervised fine-tuning and preference optimization, aimed at enhancing their capability for seamless interaction with users. Lastly, the report elaborates on plausible approaches used for language model adaptation to specific scenarios, such as embedding, retrieval augmented generation, and function calling. The Kanana model series spans from 2.1B to 32.5B parameters with 2.1B models (base, instruct, embedding) publicly released to promote research on Korean language models.
Transferability analysis of data-driven additive manufacturing knowledge: a case study between powder bed fusion and directed energy deposition
Sep 12, 2023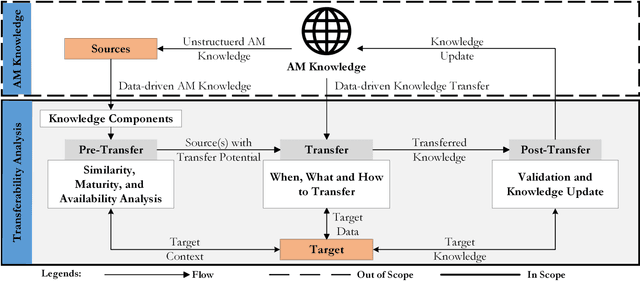



Data-driven research in Additive Manufacturing (AM) has gained significant success in recent years. This has led to a plethora of scientific literature to emerge. The knowledge in these works consists of AM and Artificial Intelligence (AI) contexts that have not been mined and formalized in an integrated way. Moreover, no tools or guidelines exist to support data-driven knowledge transfer from one context to another. As a result, data-driven solutions using specific AI techniques are being developed and validated only for specific AM process technologies. There is a potential to exploit the inherent similarities across various AM technologies and adapt the existing solutions from one process or problem to another using AI, such as Transfer Learning. We propose a three-step knowledge transferability analysis framework in AM to support data-driven AM knowledge transfer. As a prerequisite to transferability analysis, AM knowledge is featurized into identified knowledge components. The framework consists of pre-transfer, transfer, and post-transfer steps to accomplish knowledge transfer. A case study is conducted between flagship metal AM processes. Laser Powder Bed Fusion (LPBF) is the source of knowledge motivated by its relative matureness in applying AI over Directed Energy Deposition (DED), which drives the need for knowledge transfer as the less explored target process. We show successful transfer at different levels of the data-driven solution, including data representation, model architecture, and model parameters. The pipeline of AM knowledge transfer can be automated in the future to allow efficient cross-context or cross-process knowledge exchange.
A Technical Report for Polyglot-Ko: Open-Source Large-Scale Korean Language Models
Jun 06, 2023Polyglot is a pioneering project aimed at enhancing the non-English language performance of multilingual language models. Despite the availability of various multilingual models such as mBERT (Devlin et al., 2019), XGLM (Lin et al., 2022), and BLOOM (Scao et al., 2022), researchers and developers often resort to building monolingual models in their respective languages due to the dissatisfaction with the current multilingual models non-English language capabilities. Addressing this gap, we seek to develop advanced multilingual language models that offer improved performance in non-English languages. In this paper, we introduce the Polyglot Korean models, which represent a specific focus rather than being multilingual in nature. In collaboration with TUNiB, our team collected 1.2TB of Korean data meticulously curated for our research journey. We made a deliberate decision to prioritize the development of Korean models before venturing into multilingual models. This choice was motivated by multiple factors: firstly, the Korean models facilitated performance comparisons with existing multilingual models; and finally, they catered to the specific needs of Korean companies and researchers. This paper presents our work in developing the Polyglot Korean models, which propose some steps towards addressing the non-English language performance gap in multilingual language models.