 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASAP: Attention Sink Anchored Pruning
May 21, 2026Vision Transformers (ViTs) face severe computational bottlenecks due to the quadratic complexity of self-attention at high resolutions. Existing token reduction methods rely on local metrics - such as single-layer attention scores - that are inherently vulnerable to the attention sink phenomenon, where uninformative tokens are paradoxically preserved over salient foreground objects. We propose ASAP (Attention Sink Anchored Pruning), a training-free framework that recasts this sink as a feature. Modeling ViT information flow as a Lazy Random Walk, ASAP identifies the sink as a dominant accumulator of probability mass. By computing the diffusion distance to the sink within the cumulative transition matrix, ASAP partitions tokens via Radial Diffusion Clustering and compresses background redundancy through Transition Weight Pooling in a single shot. Extensive experiments across image, video, and vision-language tasks demonstrate ASAP outperforms state-of-the-art methods, accelerating throughput by up to 48% while maintaining - or even exceeding - baseline accuracy.
The Weight Gram Matrix Captures Sequential Feature Linearization in Deep Networks
May 07, 2026Understanding how deep neural networks learn representations remains a central challenge in machine learning theory. In this work, we propose a feature-centric framework for analyzing neural network training by relating weight updates to feature evolution. We introduce a simple identity, the Feature Learning Equation, which identifies the weight Gram matrix as the key object capturing feature dynamics. This enables us to interpret gradient descent as implicitly inducing a hypothetical evolution of features, whose covariance structure - termed the Virtual Covariance - characterizes how representations evolve during training. Building on this perspective, we introduce Target Linearity, a measure quantifying the linear alignment between features and targets. By analyzing the training and layer-wise dynamics, we show that deep networks learn to sequentially transform representations toward target-linear structure. This linearization perspective provides a unified interpretation of several empirical phenomena, including Neural Collapse and linear interpolation in generative models.
OPC: One-Point-Contraction Unlearning Toward Deep Feature Forgetting
Jul 10, 2025Machine unlearning seeks to remove the influence of particular data or class from trained models to meet privacy, legal, or ethical requirements. Existing unlearning methods tend to forget shallowly: phenomenon of an unlearned model pretend to forget by adjusting only the model response, while its internal representations retain information sufficiently to restore the forgotten data or behavior. We empirically confirm the widespread shallowness by reverting the forgetting effect of various unlearning methods via training-free performance recovery attack and gradient-inversion-based data reconstruction attack. To address this vulnerability fundamentally, we define a theoretical criterion of ``deep forgetting'' based on one-point-contraction of feature representations of data to forget. We also propose an efficient approximation algorithm, and use it to construct a novel general-purpose unlearning algorithm: One-Point-Contraction (OPC). Empirical evaluations on image classification unlearning benchmarks show that OPC achieves not only effective unlearning performance but also superior resilience against both performance recovery attack and gradient-inversion attack. The distinctive unlearning performance of OPC arises from the deep feature forgetting enforced by its theoretical foundation, and recaps the need for improved robustness of machine unlearning methods.
CLIP-KOA: Enhancing Knee Osteoarthritis Diagnosis with Multi-Modal Learning and Symmetry-Aware Loss Functions
Apr 28, 2025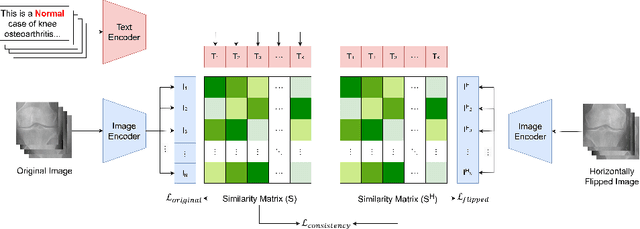
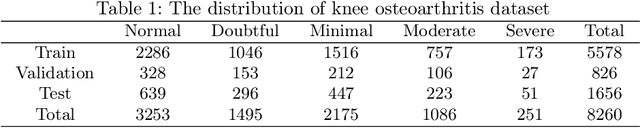

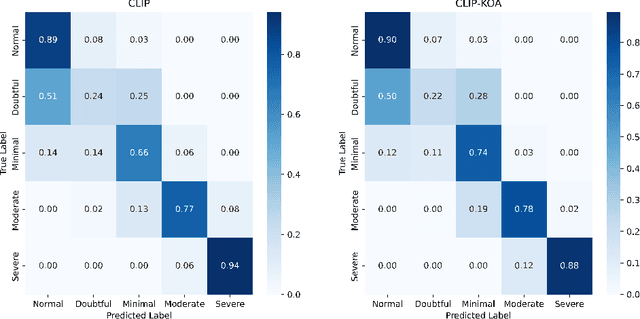
Knee osteoarthritis (KOA) is a universal chronic musculoskeletal disorders worldwide, making early diagnosis crucial. Currently, the Kellgren and Lawrence (KL) grading system is widely used to assess KOA severity. However, its high inter-observer variability and subjectivity hinder diagnostic consistency. To address these limitations, automated diagnostic techniques using deep learning have been actively explored in recent years. In this study, we propose a CLIP-based framework (CLIP-KOA) to enhance the consistency and reliability of KOA grade prediction. To achieve this, we introduce a learning approach that integrates image and text information and incorporate Symmetry Loss and Consistency Loss to ensure prediction consistency between the original and flipped images. CLIP-KOA achieves state-of-the-art accuracy of 71.86\% on KOA severity prediction task, and ablation studies show that CLIP-KOA has 2.36\% improvement in accuracy over the standard CLIP model due to our contribution. This study shows a novel direction for data-driven medical prediction not only to improve reliability of fine-grained diagnosis and but also to explore multimodal methods for medical image analysis. Our code is available at https://github.com/anonymized-link.
Kanana: Compute-efficient Bilingual Language Models
Feb 26, 2025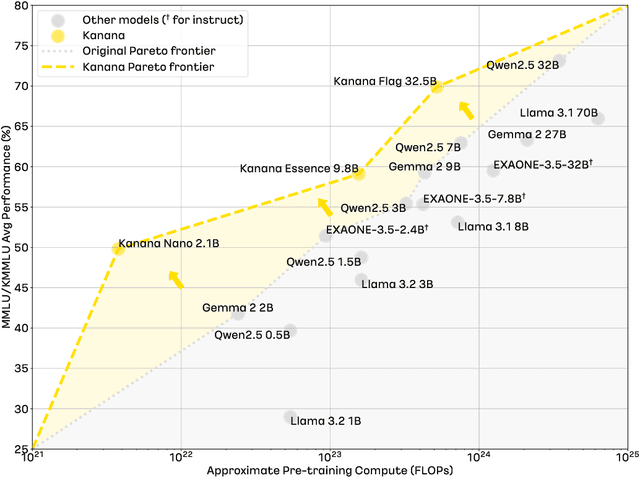



We introduce Kanana, a series of bilingual language models that demonstrate exceeding performance in Korean and competitive performance in English. The computational cost of Kanana is significantly lower than that of state-of-the-art models of similar size. The report details the techniques employed during pre-training to achieve compute-efficient yet competitive models, including high quality data filtering, staged pre-training, depth up-scaling, and pruning and distillation. Furthermore, the report outlines the methodologies utilized during the post-training of the Kanana models, encompassing supervised fine-tuning and preference optimization, aimed at enhancing their capability for seamless interaction with users. Lastly, the report elaborates on plausible approaches used for language model adaptation to specific scenarios, such as embedding, retrieval augmented generation, and function calling. The Kanana model series spans from 2.1B to 32.5B parameters with 2.1B models (base, instruct, embedding) publicly released to promote research on Korean language models.
Broadband Ground Motion Synthesis by Diffusion Model with Minimal Condition
Dec 23, 2024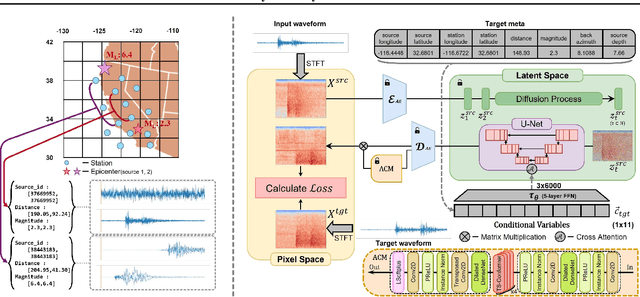
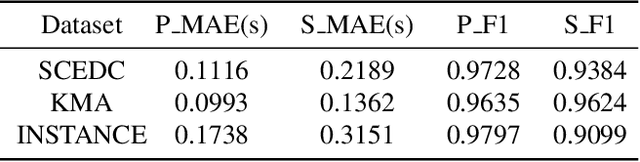
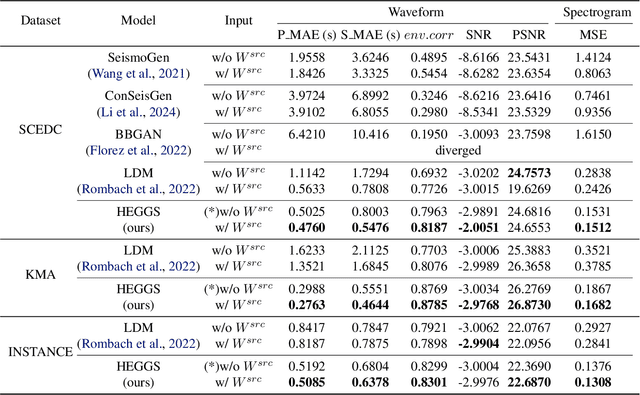
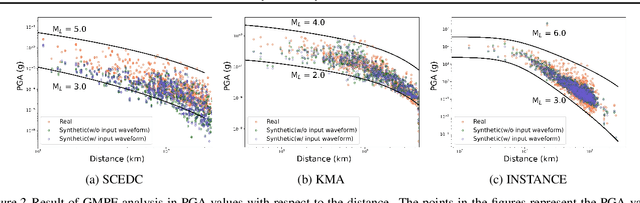
Earthquakes are rare. Hence there is a fundamental call for reliable methods to generate realistic ground motion data for data-driven approaches in seismology. Recent GAN-based methods fall short of the call, as the methods either require special information such as geological traits or generate subpar waveforms that fail to satisfy seismological constraints such as phase arrival times. We propose a specialized Latent Diffusion Model (LDM) that reliably generates realistic waveforms after learning from real earthquake data with minimal conditions: location and magnitude. We also design a domain-specific training method that exploits the traits of earthquake dataset: multiple observed waveforms time-aligned and paired to each earthquake source that are tagged with seismological metadata comprised of earthquake magnitude, depth of focus, and the locations of epicenter and seismometers. We construct the time-aligned earthquake dataset using Southern California Earthquake Data Center (SCEDC) API, and train our model with the dataset and our proposed training method for performance evaluation. Our model surpasses all comparable data-driven methods in various test criteria not only from waveform generation domain but also from seismology such as phase arrival time, GMPE analysis, and spectrum analysis. Our result opens new future research directions for deep learning applications in seismology.
ABC3: Active Bayesian Causal Inference with Cohn Criteria in Randomized Experiments
Dec 15, 2024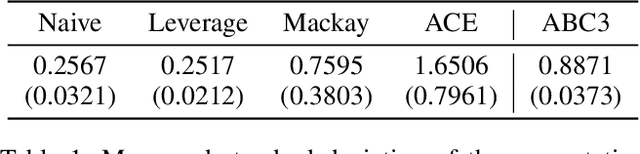
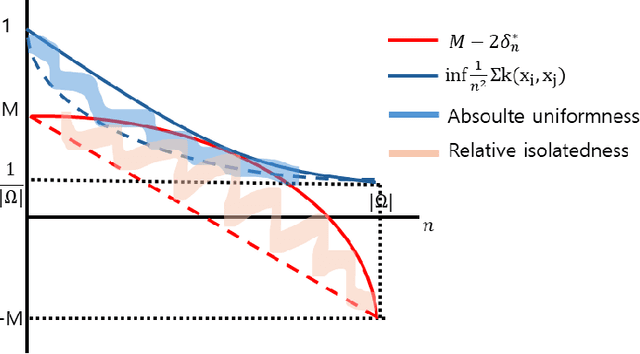
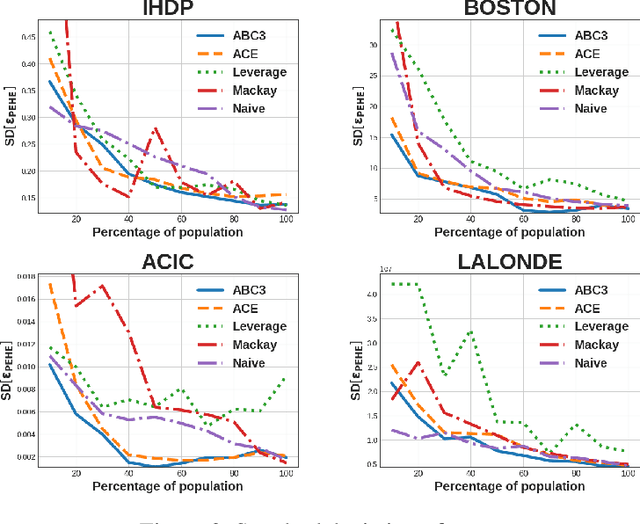
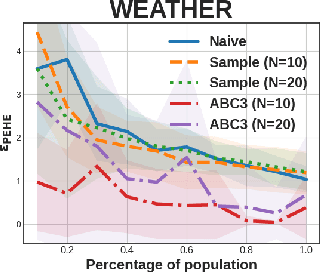
In causal inference, randomized experiment is a de facto method to overcome various theoretical issues in observational study. However, the experimental design requires expensive costs, so an efficient experimental design is necessary. We propose ABC3, a Bayesian active learning policy for causal inference. We show a policy minimizing an estimation error on conditional average treatment effect is equivalent to minimizing an integrated posterior variance, similar to Cohn criteria \citep{cohn1994active}. We theoretically prove ABC3 also minimizes an imbalance between the treatment and control groups and the type 1 error probability. Imbalance-minimizing characteristic is especially notable as several works have emphasized the importance of achieving balance. Through extensive experiments on real-world data sets, ABC3 achieves the highest efficiency, while empirically showing the theoretical results hold.
Pre-trained Language Models Return Distinguishable Probability Distributions to Unfaithfully Hallucinated Texts
Sep 25, 2024In this work, we show the pre-trained language models return distinguishable generation probability and uncertainty distribution to unfaithfully hallucinated texts, regardless of their size and structure. By examining 24 models on 6 data sets, we find out that 88-98% of cases return statistically significantly distinguishable generation probability and uncertainty distributions. Using this general phenomenon, we showcase a hallucination-reducing training algorithm. Our algorithm outperforms other baselines by achieving higher faithfulness metrics while maintaining sound general text quality measures.
Block Orthogonal Sparse Superposition Codes for $ \sf{L}^3 $ Communications: Low Error Rate, Low Latency, and Low Power Consumption
Mar 23, 2024Block orthogonal sparse superposition (BOSS) code is a class of joint coded modulation methods, which can closely achieve the finite-blocklength capacity with a low-complexity decoder at a few coding rates under Gaussian channels. However, for fading channels, the code performance degrades considerably because coded symbols experience different channel fading effects. In this paper, we put forth novel joint demodulation and decoding methods for BOSS codes under fading channels. For a fast fading channel, we present a minimum mean square error approximate maximum a posteriori (MMSE-A-MAP) algorithm for the joint demodulation and decoding when channel state information is available at the receiver (CSIR). We also propose a joint demodulation and decoding method without using CSIR for a block fading channel scenario. We refer to this as the non-coherent sphere decoding (NSD) algorithm. Simulation results demonstrate that BOSS codes with MMSE-A-MAP decoding outperform CRC-aided polar codes, while NSD decoding achieves comparable performance to quasi-maximum likelihood decoding with significantly reduced complexity. Both decoding algorithms are suitable for parallelization, satisfying low-latency constraints. Additionally, real-time simulations on a software-defined radio testbed validate the feasibility of using BOSS codes for low-power transmission.
P5: Plug-and-Play Persona Prompting for Personalized Response Selection
Oct 10, 2023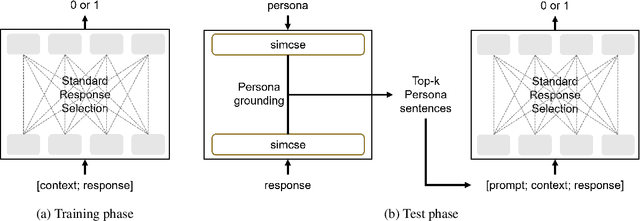
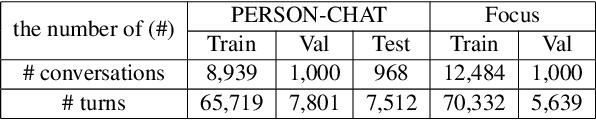
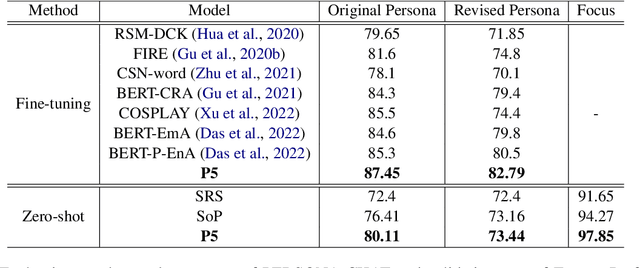
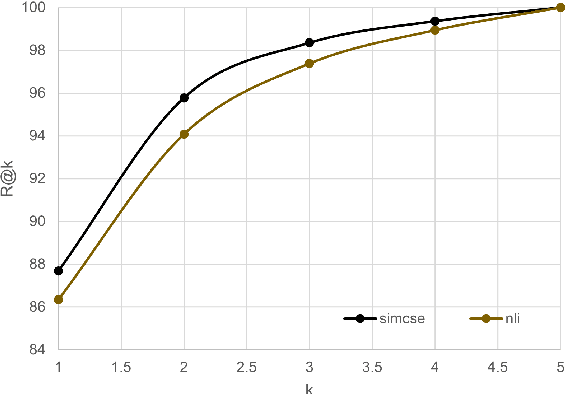
The use of persona-grounded retrieval-based chatbots is crucial for personalized conversations, but there are several challenges that need to be addressed. 1) In general, collecting persona-grounded corpus is very expensive. 2) The chatbot system does not always respond in consideration of persona at real applications. To address these challenges, we propose a plug-and-play persona prompting method. Our system can function as a standard open-domain chatbot if persona information is not available. We demonstrate that this approach performs well in the zero-shot setting, which reduces the dependence on persona-ground training data. This makes it easier to expand the system to other languages without the need to build a persona-grounded corpus. Additionally, our model can be fine-tuned for even better performance. In our experiments, the zero-shot model improved the standard model by 7.71 and 1.04 points in the original persona and revised persona, respectively. The fine-tuned model improved the previous state-of-the-art system by 1.95 and 3.39 points in the original persona and revised persona, respectively. To the best of our knowledge, this is the first attempt to solve the problem of personalized response selection using prompt sequences. Our code is available on github~\footnote{https://github.com/rungjoo/plug-and-play-prompt-persona}.