 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruly Batch Apprenticeship Learning with Deep Successor Features
Paper and Code
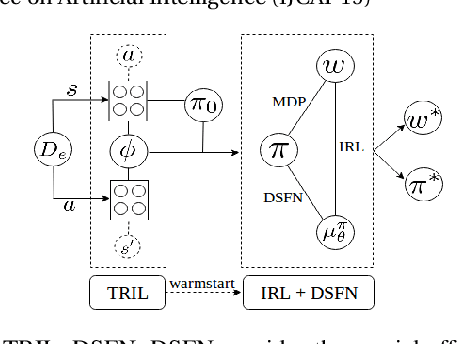
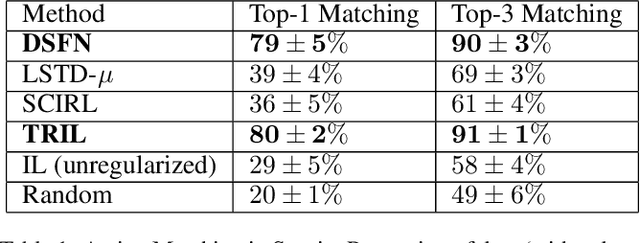
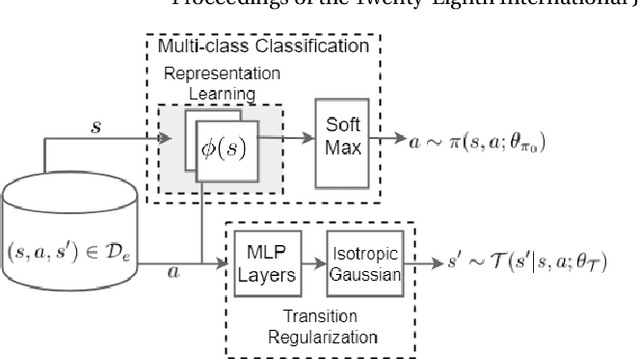
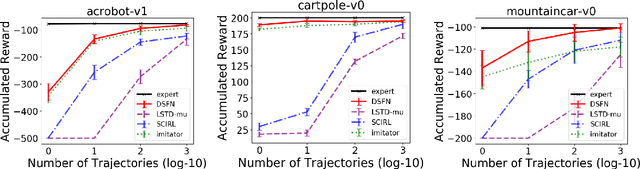
We introduce a novel apprenticeship learning algorithm to learn an expert's underlying reward structure in off-policy model-free \emph{batch} settings. Unlike existing methods that require a dynamics model or additional data acquisition for on-policy evaluation, our algorithm requires only the batch data of observed expert behavior. Such settings are common in real-world tasks---health care, finance or industrial processes ---where accurate simulators do not exist or data acquisition is costly. To address challenges in batch settings, we introduce Deep Successor Feature Networks(DSFN) that estimate feature expectations in an off-policy setting and a transition-regularized imitation network that produces a near-expert initial policy and an efficient feature representation. Our algorithm achieves superior results in batch settings on both control benchmarks and a vital clinical task of sepsis management in the Intensive Care Unit.