 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABC3: Active Bayesian Causal Inference with Cohn Criteria in Randomized Experiments
Dec 15, 2024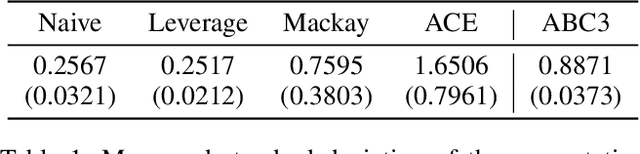
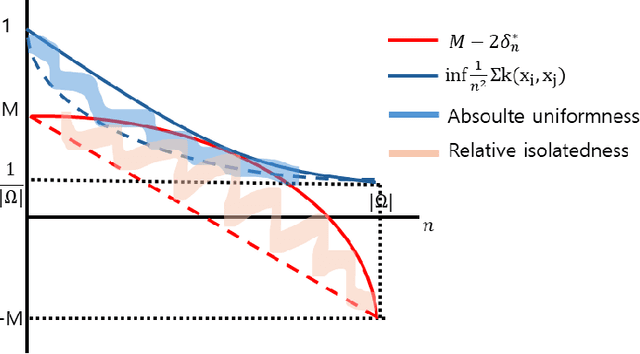
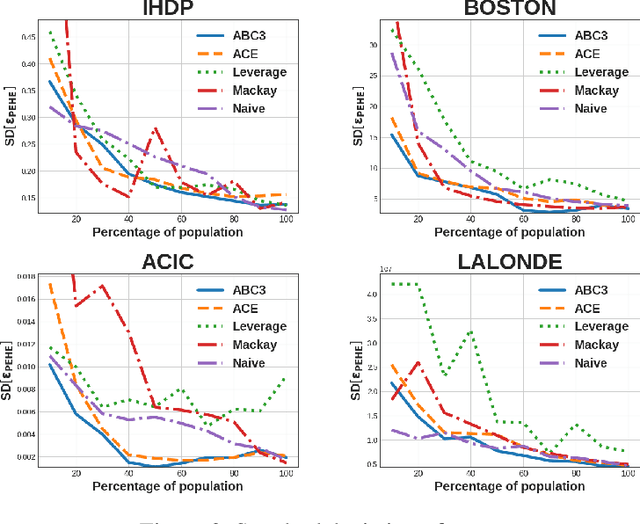
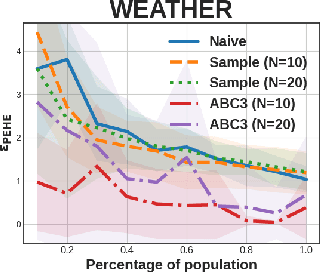
In causal inference, randomized experiment is a de facto method to overcome various theoretical issues in observational study. However, the experimental design requires expensive costs, so an efficient experimental design is necessary. We propose ABC3, a Bayesian active learning policy for causal inference. We show a policy minimizing an estimation error on conditional average treatment effect is equivalent to minimizing an integrated posterior variance, similar to Cohn criteria \citep{cohn1994active}. We theoretically prove ABC3 also minimizes an imbalance between the treatment and control groups and the type 1 error probability. Imbalance-minimizing characteristic is especially notable as several works have emphasized the importance of achieving balance. Through extensive experiments on real-world data sets, ABC3 achieves the highest efficiency, while empirically showing the theoretical results hold.
Pre-trained Language Models Return Distinguishable Probability Distributions to Unfaithfully Hallucinated Texts
Sep 25, 2024In this work, we show the pre-trained language models return distinguishable generation probability and uncertainty distribution to unfaithfully hallucinated texts, regardless of their size and structure. By examining 24 models on 6 data sets, we find out that 88-98% of cases return statistically significantly distinguishable generation probability and uncertainty distributions. Using this general phenomenon, we showcase a hallucination-reducing training algorithm. Our algorithm outperforms other baselines by achieving higher faithfulness metrics while maintaining sound general text quality measures.