 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteerable Cultural Preference Optimization of Reward Models
Jun 17, 2026It is essential for large language model (LLM) technology to serve many different cultural sub-communities in a manner that is acceptable to each community. However, research on LLM alignment has so far predominantly focused on predicting a unified response preference of annotators from certain regions. This paper aims to advance the development of alignment models with a more global outlook, that are able to accurately represent the preferences of subcommunities and do not exhibit excessive bias towards any of them. We focus on the development of reward models for this purpose and present a novel reward model training algorithm (SCPO) that can incorporate diverse cultural preferences in a balanced manner. Our method results in performance increases of the minority reward model of up to 7 points over the baseline model across two datasets, PRISM and GlobalOpinionQA, and across 7 countries. SCPO is up to 280% more training data-efficient than full-data finetuning of reward models. In addition, we perform analysis of bias by separately evaluating on the preference of subcommunities and show that excessive bias is mitigated via our weighting method. Our code is available at https://github.com/minsik-ai/Steerable-Cultural-Preference
P5: Plug-and-Play Persona Prompting for Personalized Response Selection
Oct 10, 2023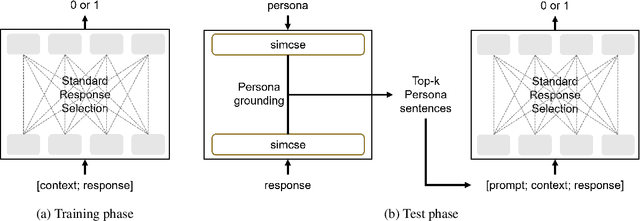
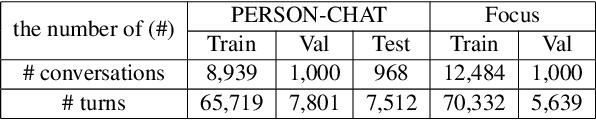
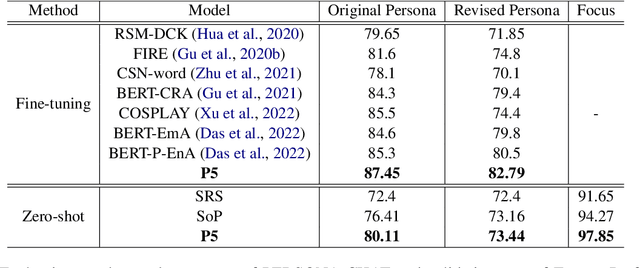
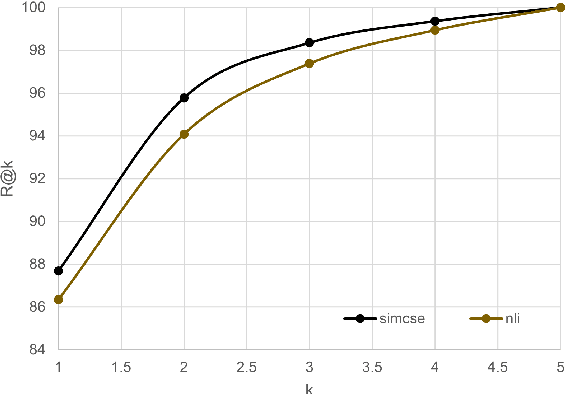
The use of persona-grounded retrieval-based chatbots is crucial for personalized conversations, but there are several challenges that need to be addressed. 1) In general, collecting persona-grounded corpus is very expensive. 2) The chatbot system does not always respond in consideration of persona at real applications. To address these challenges, we propose a plug-and-play persona prompting method. Our system can function as a standard open-domain chatbot if persona information is not available. We demonstrate that this approach performs well in the zero-shot setting, which reduces the dependence on persona-ground training data. This makes it easier to expand the system to other languages without the need to build a persona-grounded corpus. Additionally, our model can be fine-tuned for even better performance. In our experiments, the zero-shot model improved the standard model by 7.71 and 1.04 points in the original persona and revised persona, respectively. The fine-tuned model improved the previous state-of-the-art system by 1.95 and 3.39 points in the original persona and revised persona, respectively. To the best of our knowledge, this is the first attempt to solve the problem of personalized response selection using prompt sequences. Our code is available on github~\footnote{https://github.com/rungjoo/plug-and-play-prompt-persona}.
TaDSE: Template-aware Dialogue Sentence Embeddings
May 23, 2023



Learning high quality sentence embeddings from dialogues has drawn increasing attentions as it is essential to solve a variety of dialogue-oriented tasks with low annotation cost. However, directly annotating and gathering utterance relationships in conversations are difficult, while token-level annotations, \eg, entities, slots and templates, are much easier to obtain. General sentence embedding methods are usually sentence-level self-supervised frameworks and cannot utilize token-level extra knowledge. In this paper, we introduce Template-aware Dialogue Sentence Embedding (TaDSE), a novel augmentation method that utilizes template information to effectively learn utterance representation via self-supervised contrastive learning framework. TaDSE augments each sentence with its corresponding template and then conducts pairwise contrastive learning over both sentence and template. We further enhance the effect with a synthetically augmented dataset that enhances utterance-template relation, in which entity detection (slot-filling) is a preliminary step. We evaluate TaDSE performance on five downstream benchmark datasets. The experiment results show that TaDSE achieves significant improvements over previous SOTA methods, along with a consistent Intent Classification task performance improvement margin. We further introduce a novel analytic instrument of Semantic Compression method, for which we discover a correlation with uniformity and alignment. Our code will be released soon.
PK-ICR: Persona-Knowledge Interactive Context Retrieval for Grounded Dialogue
Feb 13, 2023Identifying relevant Persona or Knowledge for conversational systems is a critical component of grounded dialogue response generation. However, each grounding has been studied in isolation with more practical multi-context tasks only recently introduced. We define Persona and Knowledge Dual Context Identification as the task to identify Persona and Knowledge jointly for a given dialogue, which could be of elevated importance in complex multi-context Dialogue settings. We develop a novel grounding retrieval method that utilizes all contexts of dialogue simultaneously while also requiring limited training via zero-shot inference due to compatibility with neural Q \& A retrieval models. We further analyze the hard-negative behavior of combining Persona and Dialogue via our novel null-positive rank test.