 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Hallucination Detection via Future Context
Jul 28, 2025Large Language Models (LLMs) are widely used to generate plausible text on online platforms, without revealing the generation process. As users increasingly encounter such black-box outputs, detecting hallucinations has become a critical challenge. To address this challenge, we focus on developing a hallucination detection framework for black-box generators. Motivated by the observation that hallucinations, once introduced, tend to persist, we sample future contexts. The sampled future contexts provide valuable clues for hallucination detection and can be effectively integrated with various sampling-based methods. We extensively demonstrate performance improvements across multiple methods using our proposed sampling approach.
Cross-lingual Collapse: How Language-Centric Foundation Models Shape Reasoning in Large Language Models
Jun 06, 2025



We identify \textbf{Cross-lingual Collapse}, a systematic drift in which the chain-of-thought (CoT) of a multilingual language model reverts to its dominant pre-training language even when the prompt is expressed in a different language. Recent large language models (LLMs) with reinforcement learning with verifiable reward (RLVR) have achieved strong logical reasoning performances by exposing their intermediate reasoning traces, giving rise to large reasoning models (LRMs). However, the mechanism behind multilingual reasoning in LRMs is not yet fully explored. To investigate the issue, we fine-tune multilingual LRMs with Group-Relative Policy Optimization (GRPO) on translated versions of the GSM$8$K and SimpleRL-Zoo datasets in three different languages: Chinese, Korean, and Ukrainian. During training, we monitor both task accuracy and language consistency of the reasoning chains. Our experiments reveal three key findings: (i) GRPO rapidly amplifies pre-training language imbalances, leading to the erosion of low-resource languages within just a few hundred updates; (ii) language consistency reward mitigates this drift but does so at the expense of an almost 5 - 10 pp drop in accuracy. and (iii) the resulting language collapse is severely damaging and largely irreversible, as subsequent fine-tuning struggles to steer the model back toward its original target-language reasoning capabilities. Together, these findings point to a remarkable conclusion: \textit{not all languages are trained equally for reasoning}. Furthermore, our paper sheds light on the roles of reward shaping, data difficulty, and pre-training priors in eliciting multilingual reasoning.
Enhanced Facet Generation with LLM Editing
Mar 25, 2024In information retrieval, facet identification of a user query is an important task. If a search service can recognize the facets of a user's query, it has the potential to offer users a much broader range of search results. Previous studies can enhance facet prediction by leveraging retrieved documents and related queries obtained through a search engine. However, there are challenges in extending it to other applications when a search engine operates as part of the model. First, search engines are constantly updated. Therefore, additional information may change during training and test, which may reduce performance. The second challenge is that public search engines cannot search for internal documents. Therefore, a separate search system needs to be built to incorporate documents from private domains within the company. We propose two strategies that focus on a framework that can predict facets by taking only queries as input without a search engine. The first strategy is multi-task learning to predict SERP. By leveraging SERP as a target instead of a source, the proposed model deeply understands queries without relying on external modules. The second strategy is to enhance the facets by combining Large Language Model (LLM) and the small model. Overall performance improves when small model and LLM are combined rather than facet generation individually.
P5: Plug-and-Play Persona Prompting for Personalized Response Selection
Oct 10, 2023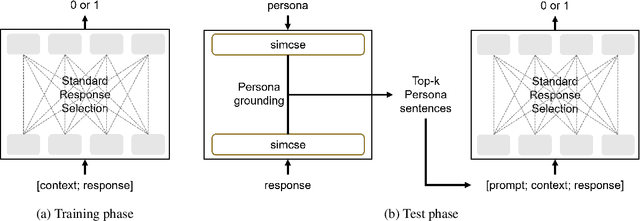
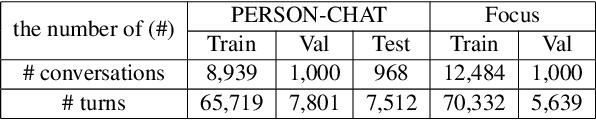
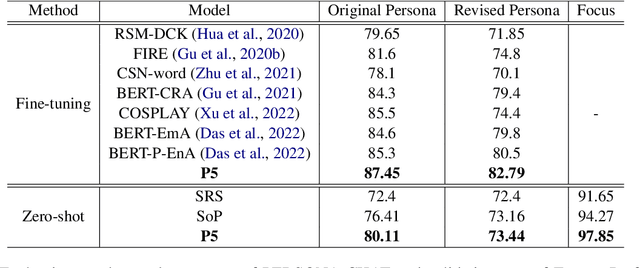
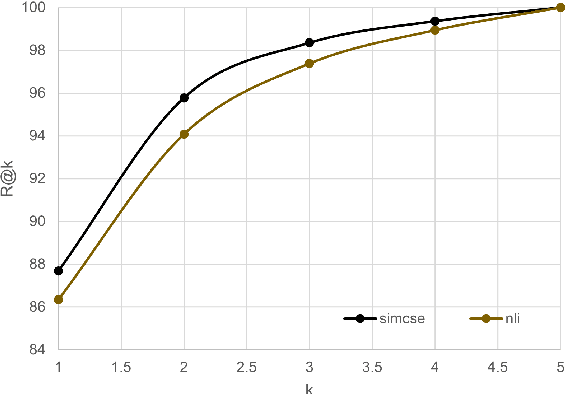
The use of persona-grounded retrieval-based chatbots is crucial for personalized conversations, but there are several challenges that need to be addressed. 1) In general, collecting persona-grounded corpus is very expensive. 2) The chatbot system does not always respond in consideration of persona at real applications. To address these challenges, we propose a plug-and-play persona prompting method. Our system can function as a standard open-domain chatbot if persona information is not available. We demonstrate that this approach performs well in the zero-shot setting, which reduces the dependence on persona-ground training data. This makes it easier to expand the system to other languages without the need to build a persona-grounded corpus. Additionally, our model can be fine-tuned for even better performance. In our experiments, the zero-shot model improved the standard model by 7.71 and 1.04 points in the original persona and revised persona, respectively. The fine-tuned model improved the previous state-of-the-art system by 1.95 and 3.39 points in the original persona and revised persona, respectively. To the best of our knowledge, this is the first attempt to solve the problem of personalized response selection using prompt sequences. Our code is available on github~\footnote{https://github.com/rungjoo/plug-and-play-prompt-persona}.
PK-ICR: Persona-Knowledge Interactive Context Retrieval for Grounded Dialogue
Feb 13, 2023Identifying relevant Persona or Knowledge for conversational systems is a critical component of grounded dialogue response generation. However, each grounding has been studied in isolation with more practical multi-context tasks only recently introduced. We define Persona and Knowledge Dual Context Identification as the task to identify Persona and Knowledge jointly for a given dialogue, which could be of elevated importance in complex multi-context Dialogue settings. We develop a novel grounding retrieval method that utilizes all contexts of dialogue simultaneously while also requiring limited training via zero-shot inference due to compatibility with neural Q \& A retrieval models. We further analyze the hard-negative behavior of combining Persona and Dialogue via our novel null-positive rank test.
The Emotion is Not One-hot Encoding: Learning with Grayscale Label for Emotion Recognition in Conversation
Jun 16, 2022



In emotion recognition in conversation (ERC), the emotion of the current utterance is predicted by considering the previous context, which can be utilized in many natural language processing tasks. Although multiple emotions can coexist in a given sentence, most previous approaches take the perspective of a classification task to predict only a given label. However, it is expensive and difficult to label the emotion of a sentence with confidence or multi-label. In this paper, we automatically construct a grayscale label considering the correlation between emotions and use it for learning. That is, instead of using a given label as a one-hot encoding, we construct a grayscale label by measuring scores for different emotions. We introduce several methods for constructing grayscale labels and confirm that each method improves the emotion recognition performance. Our method is simple, effective, and universally applicable to previous systems. The experiments show a significant improvement in the performance of baselines.
Multimodal Interactions Using Pretrained Unimodal Models for SIMMC 2.0
Dec 18, 2021
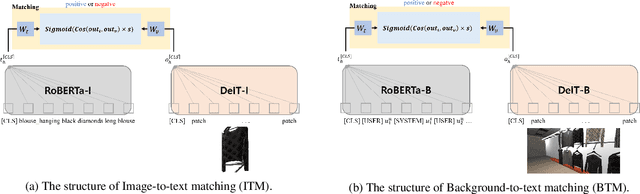
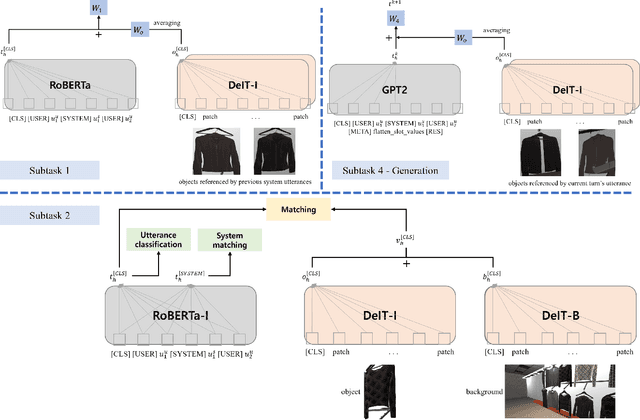
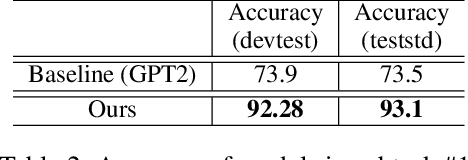
This paper presents our work on the Situated Interactive MultiModal Conversations 2.0 challenge held at Dialog State Tracking Challenge 10. SIMMC 2.0 includes 4 subtasks, and we introduce our multimodal approaches for the subtask \#1, \#2 and the generation of subtask \#4. SIMMC 2.0 dataset is a multimodal dataset containing image and text information, which is more challenging than the problem of only text-based conversations because it must be solved by understanding the relationship between image and text. Therefore, since there is a limit to solving only text models such as BERT or GPT2, we propose a multimodal model combining image and text. We first pretrain the multimodal model to understand the relationship between image and text, then finetune our model for each task. We achieve the 3rd best performance in subtask \#1, \#2 and a runner-up in the generation of subtask \#4. The source code is available at https://github.com/rungjoo/simmc2.0.
An Evaluation Dataset and Strategy for Building Robust Multi-turn Response Selection Model
Sep 10, 2021


Multi-turn response selection models have recently shown comparable performance to humans in several benchmark datasets. However, in the real environment, these models often have weaknesses, such as making incorrect predictions based heavily on superficial patterns without a comprehensive understanding of the context. For example, these models often give a high score to the wrong response candidate containing several keywords related to the context but using the inconsistent tense. In this study, we analyze the weaknesses of the open-domain Korean Multi-turn response selection models and publish an adversarial dataset to evaluate these weaknesses. We also suggest a strategy to build a robust model in this adversarial environment.
CoMPM: Context Modeling with Speaker's Pre-trained Memory Tracking for Emotion Recognition in Conversation
Aug 26, 2021
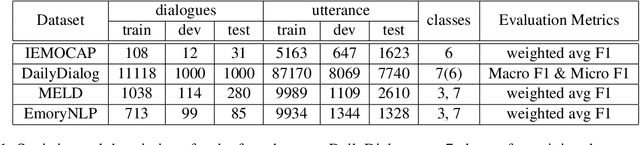
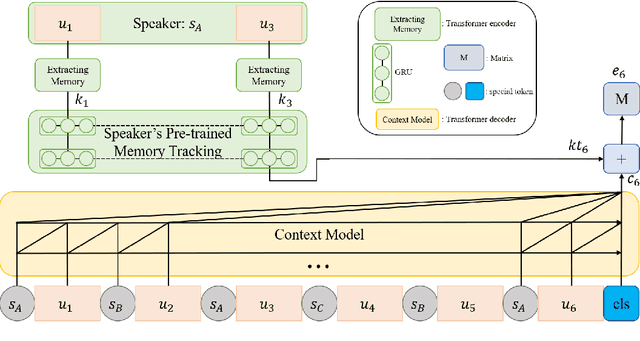
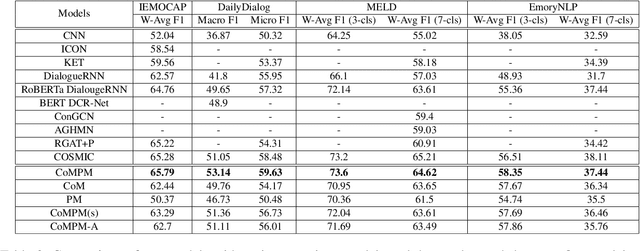
As the use of interactive machines grow, the task of Emotion Recognition in Conversation (ERC) became more important. If the machine generated sentences reflect emotion, more human-like sympathetic conversations are possible. Since emotion recognition in conversation is inaccurate if the previous utterances are not taken into account, many studies reflect the dialogue context to improve the performances. We introduce CoMPM, a context embedding module (CoM) combined with a pre-trained memory module (PM) that tracks memory of the speaker's previous utterances within the context, and show that the pre-trained memory significantly improves the final accuracy of emotion recognition. We experimented on both the multi-party datasets (MELD, EmoryNLP) and the dyadic-party datasets (IEMOCAP, DailyDialog), showing that our approach achieve competitive performance on all datasets.
Paraphrasing via Ranking Many Candidates
Jul 20, 2021
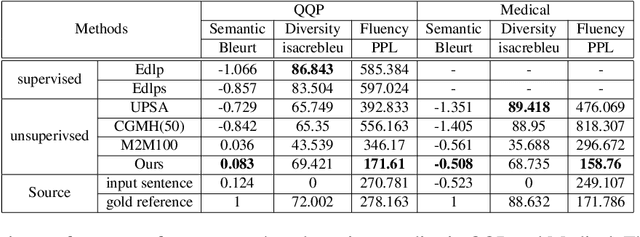
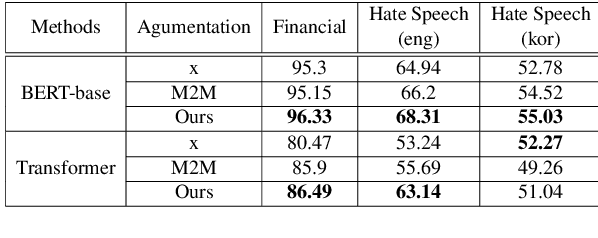
We present a simple and effective way to generate a variety of paraphrases and find a good quality paraphrase among them. As in previous studies, it is difficult to ensure that one generation method always generates the best paraphrase in various domains. Therefore, we focus on finding the best candidate from multiple candidates, rather than assuming that there is only one combination of generative models and decoding options. Our approach shows that it is easy to apply in various domains and has sufficiently good performance compared to previous methods. In addition, our approach can be used for data agumentation that extends the downstream corpus, showing that it can help improve performance in English and Korean datasets.