Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaphrasing via Ranking Many Candidates
Paper and Code
Jul 20, 2021
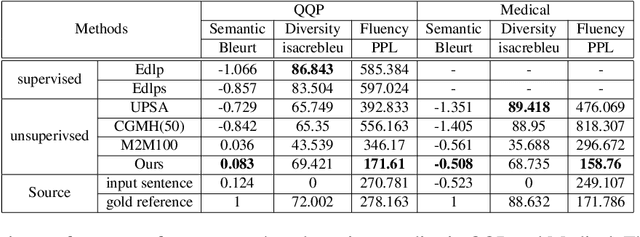
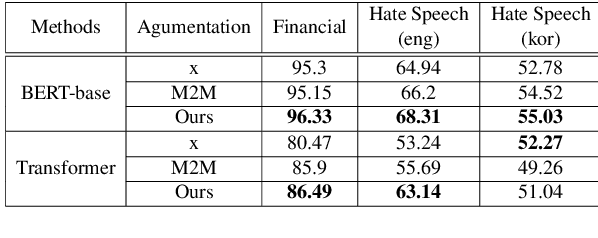
We present a simple and effective way to generate a variety of paraphrases and find a good quality paraphrase among them. As in previous studies, it is difficult to ensure that one generation method always generates the best paraphrase in various domains. Therefore, we focus on finding the best candidate from multiple candidates, rather than assuming that there is only one combination of generative models and decoding options. Our approach shows that it is easy to apply in various domains and has sufficiently good performance compared to previous methods. In addition, our approach can be used for data agumentation that extends the downstream corpus, showing that it can help improve performance in English and Korean datasets.
* 4 pages
View paper on