 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Interactions Using Pretrained Unimodal Models for SIMMC 2.0
Dec 18, 2021
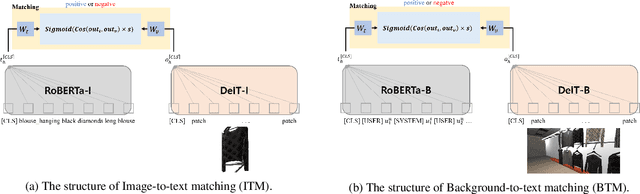
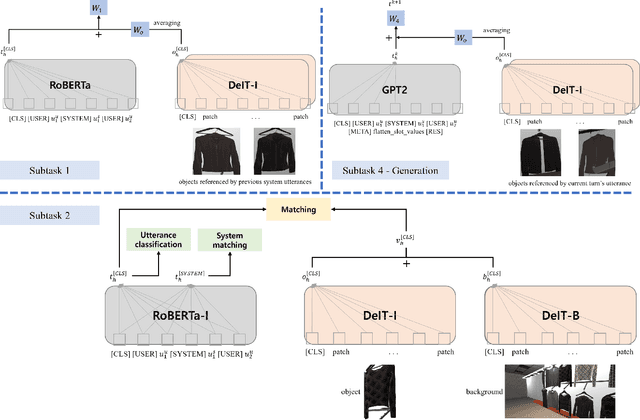
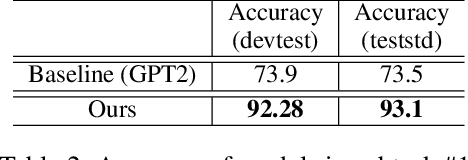
This paper presents our work on the Situated Interactive MultiModal Conversations 2.0 challenge held at Dialog State Tracking Challenge 10. SIMMC 2.0 includes 4 subtasks, and we introduce our multimodal approaches for the subtask \#1, \#2 and the generation of subtask \#4. SIMMC 2.0 dataset is a multimodal dataset containing image and text information, which is more challenging than the problem of only text-based conversations because it must be solved by understanding the relationship between image and text. Therefore, since there is a limit to solving only text models such as BERT or GPT2, we propose a multimodal model combining image and text. We first pretrain the multimodal model to understand the relationship between image and text, then finetune our model for each task. We achieve the 3rd best performance in subtask \#1, \#2 and a runner-up in the generation of subtask \#4. The source code is available at https://github.com/rungjoo/simmc2.0.
An Evaluation Dataset and Strategy for Building Robust Multi-turn Response Selection Model
Sep 10, 2021


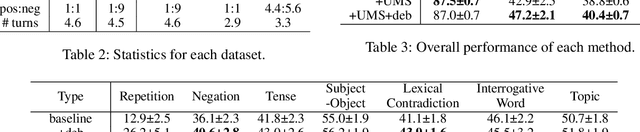
Multi-turn response selection models have recently shown comparable performance to humans in several benchmark datasets. However, in the real environment, these models often have weaknesses, such as making incorrect predictions based heavily on superficial patterns without a comprehensive understanding of the context. For example, these models often give a high score to the wrong response candidate containing several keywords related to the context but using the inconsistent tense. In this study, we analyze the weaknesses of the open-domain Korean Multi-turn response selection models and publish an adversarial dataset to evaluate these weaknesses. We also suggest a strategy to build a robust model in this adversarial environment.
Do Response Selection Models Really Know What's Next? Utterance Manipulation Strategies for Multi-turn Response Selection
Sep 10, 2020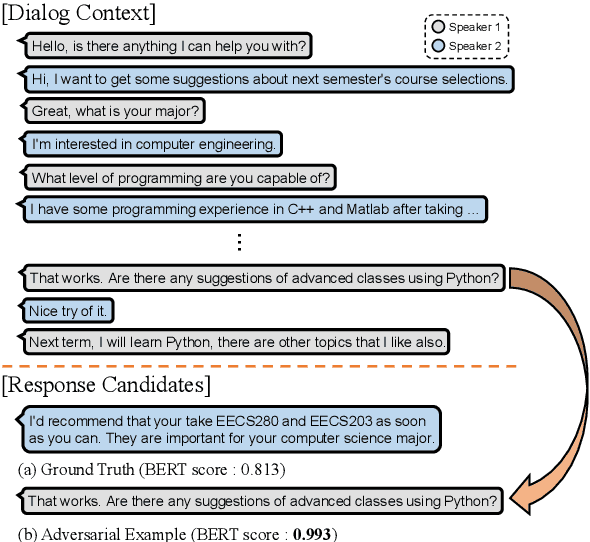

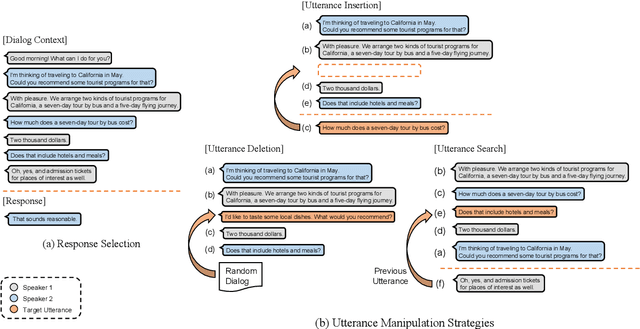
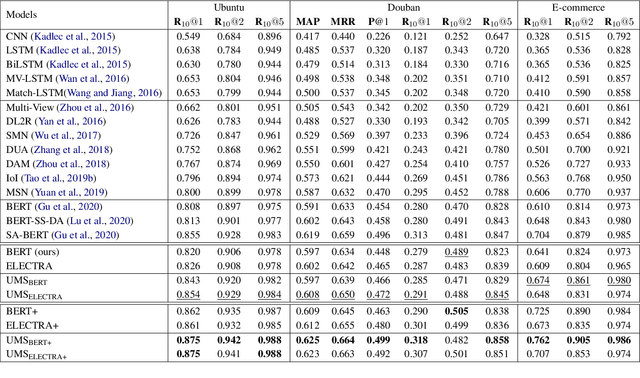
In this paper, we study the task of selecting optimal response given user and system utterance history in retrieval-based multi-turn dialog systems. Recently, pre-trained language models (e.g., BERT, RoBERTa, and ELECTRA) have shown significant improvements in various natural language processing tasks. This and similar response selection tasks can also be solved using such language models by formulating them as dialog-response binary classification tasks. Although existing works using this approach successfully obtained state-of-the-art results, we observe that language models trained in this manner tend to make predictions based on the relatedness of history and candidates, ignoring the sequential nature of multi-turn dialog systems. This suggests that the response selection task alone is insufficient in learning temporal dependencies between utterances. To this end, we propose utterance manipulation strategies (UMS) to address this problem. Specifically, UMS consist of several strategies (i.e., insertion, deletion, and search), which aid the response selection model towards maintaining dialog coherence. Further, UMS are self-supervised methods that do not require additional annotation and thus can be easily incorporated into existing approaches. Extensive evaluation across multiple languages and models shows that UMS are highly effective in teaching dialog consistency, which lead to models pushing the state-of-the-art with significant margins on multiple public benchmark datasets.