 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Judge a Language Model by Its Last Layer: Contrastive Learning with Layer-Wise Attention Pooling
Sep 13, 2022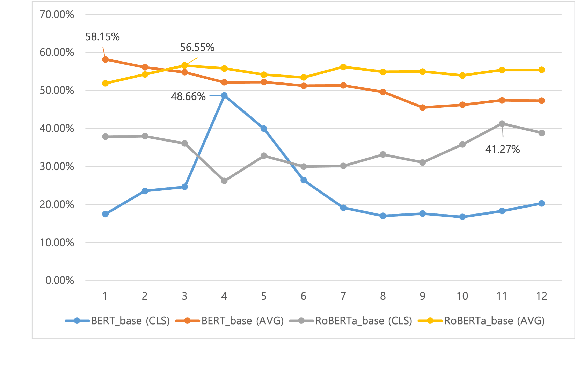
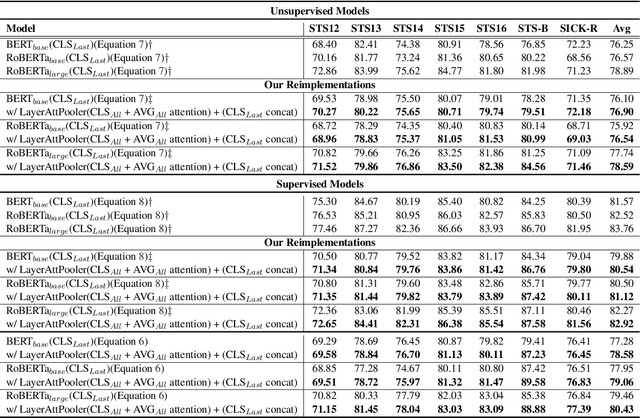
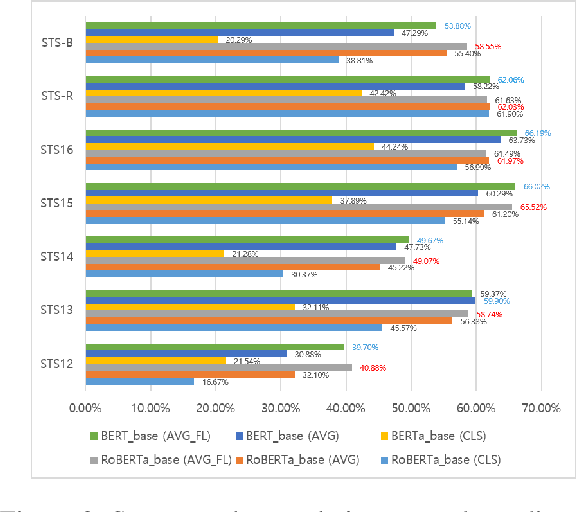

Recent pre-trained language models (PLMs) achieved great success on many natural language processing tasks through learning linguistic features and contextualized sentence representation. Since attributes captured in stacked layers of PLMs are not clearly identified, straightforward approaches such as embedding the last layer are commonly preferred to derive sentence representations from PLMs. This paper introduces the attention-based pooling strategy, which enables the model to preserve layer-wise signals captured in each layer and learn digested linguistic features for downstream tasks. The contrastive learning objective can adapt the layer-wise attention pooling to both unsupervised and supervised manners. It results in regularizing the anisotropic space of pre-trained embeddings and being more uniform. We evaluate our model on standard semantic textual similarity (STS) and semantic search tasks. As a result, our method improved the performance of the base contrastive learned BERT_base and variants.
Call for Customized Conversation: Customized Conversation Grounding Persona and Knowledge
Dec 16, 2021


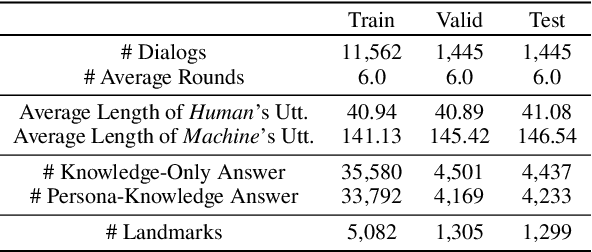
Humans usually have conversations by making use of prior knowledge about a topic and background information of the people whom they are talking to. However, existing conversational agents and datasets do not consider such comprehensive information, and thus they have a limitation in generating the utterances where the knowledge and persona are fused properly. To address this issue, we introduce a call For Customized conversation (FoCus) dataset where the customized answers are built with the user's persona and Wikipedia knowledge. To evaluate the abilities to make informative and customized utterances of pre-trained language models, we utilize BART and GPT-2 as well as transformer-based models. We assess their generation abilities with automatic scores and conduct human evaluations for qualitative results. We examine whether the model reflects adequate persona and knowledge with our proposed two sub-tasks, persona grounding (PG) and knowledge grounding (KG). Moreover, we show that the utterances of our data are constructed with the proper knowledge and persona through grounding quality assessment.
I Know What You Asked: Graph Path Learning using AMR for Commonsense Reasoning
Nov 06, 2020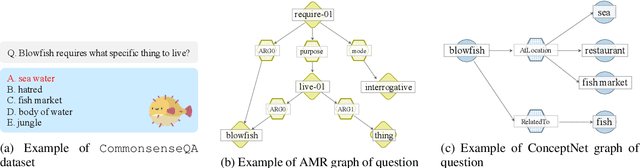
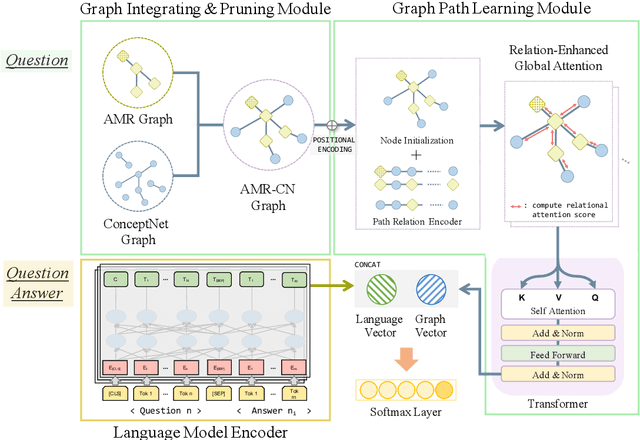
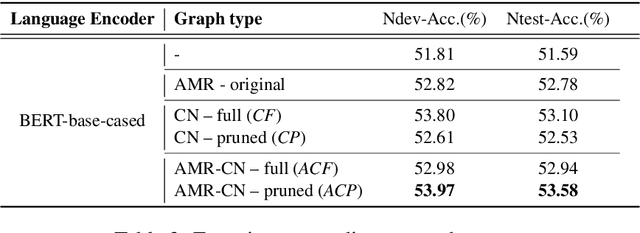
CommonsenseQA is a task in which a correct answer is predicted through commonsense reasoning with pre-defined knowledge. Most previous works have aimed to improve the performance with distributed representation without considering the process of predicting the answer from the semantic representation of the question. To shed light upon the semantic interpretation of the question, we propose an AMR-ConceptNet-Pruned (ACP) graph. The ACP graph is pruned from a full integrated graph encompassing Abstract Meaning Representation (AMR) graph generated from input questions and an external commonsense knowledge graph, ConceptNet (CN). Then the ACP graph is exploited to interpret the reasoning path as well as to predict the correct answer on the CommonsenseQA task. This paper presents the manner in which the commonsense reasoning process can be interpreted with the relations and concepts provided by the ACP graph. Moreover, ACP-based models are shown to outperform the baselines.
Do Response Selection Models Really Know What's Next? Utterance Manipulation Strategies for Multi-turn Response Selection
Sep 10, 2020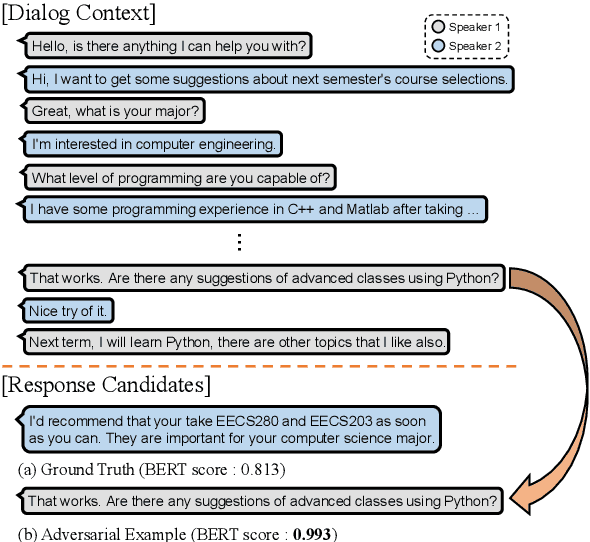

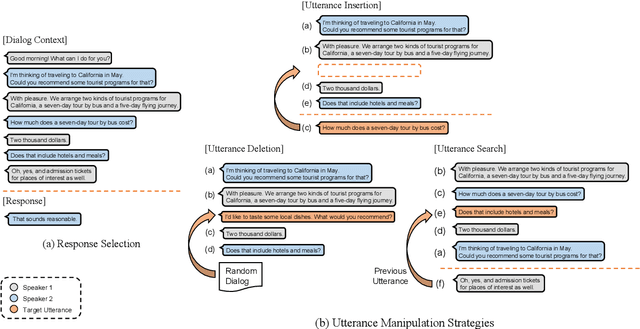
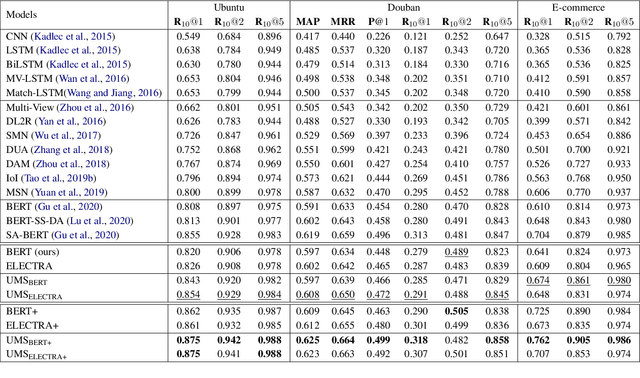
In this paper, we study the task of selecting optimal response given user and system utterance history in retrieval-based multi-turn dialog systems. Recently, pre-trained language models (e.g., BERT, RoBERTa, and ELECTRA) have shown significant improvements in various natural language processing tasks. This and similar response selection tasks can also be solved using such language models by formulating them as dialog-response binary classification tasks. Although existing works using this approach successfully obtained state-of-the-art results, we observe that language models trained in this manner tend to make predictions based on the relatedness of history and candidates, ignoring the sequential nature of multi-turn dialog systems. This suggests that the response selection task alone is insufficient in learning temporal dependencies between utterances. To this end, we propose utterance manipulation strategies (UMS) to address this problem. Specifically, UMS consist of several strategies (i.e., insertion, deletion, and search), which aid the response selection model towards maintaining dialog coherence. Further, UMS are self-supervised methods that do not require additional annotation and thus can be easily incorporated into existing approaches. Extensive evaluation across multiple languages and models shows that UMS are highly effective in teaching dialog consistency, which lead to models pushing the state-of-the-art with significant margins on multiple public benchmark datasets.
Word Sense Disambiguation using Knowledge-based Word Similarity
Nov 11, 2019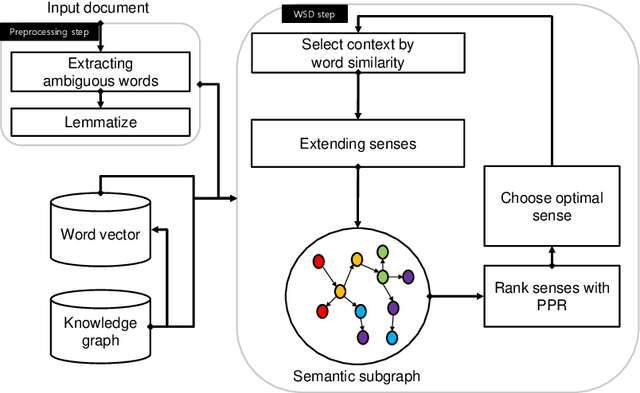

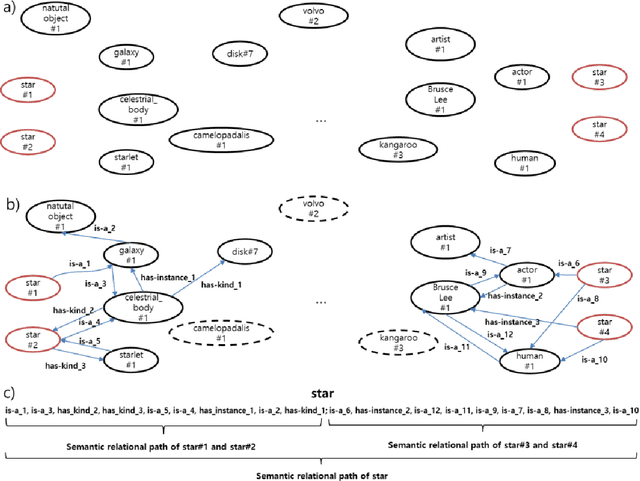

In natural language processing, word-sense disambiguation (WSD) is an open problem concerned with identifying the correct sense of words in a particular context. To address this problem, we introduce a novel knowledge-based WSD system. We suggest the adoption of two methods in our system. First, we suggest a novel method to encode the word vector representation by considering the graphical semantic relationships from the lexical knowledge-base. Second, we propose a method for extracting the contextual words from the text for analyzing an ambiguous word based on the similarity of word vector representations. To validate the effectiveness of our WSD system, we conducted experiments on the five benchmark English WSD corpora (Senseval-02, Senseval-03, SemEval-07, SemEval-13, and SemEval-15). The obtained results demonstrated that the suggested methods significantly enhanced the WSD performance. Furthermore, our system outperformed the existing knowledge-based WSD systems and showed a performance comparable to that of the state-of-the-art supervised WSD systems.
Domain Adaptive Training BERT for Response Selection
Aug 13, 2019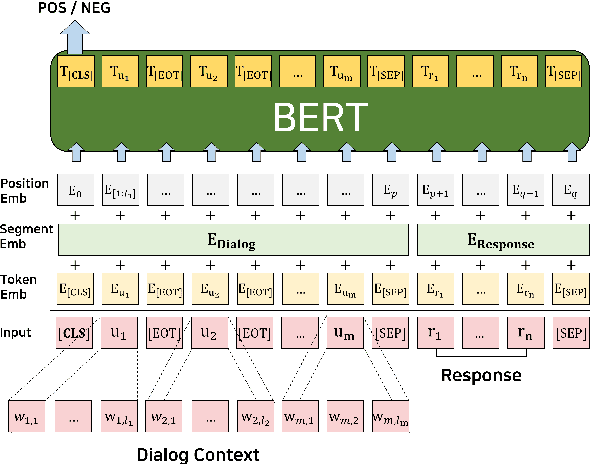
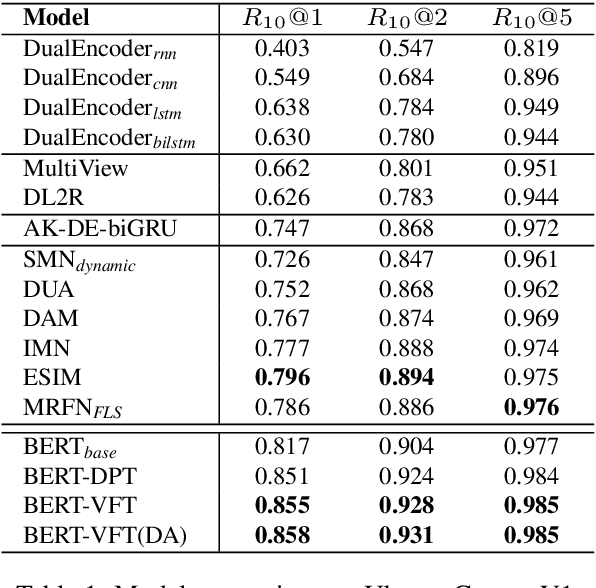
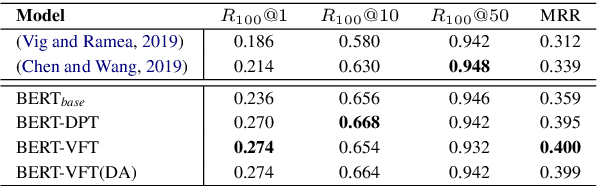
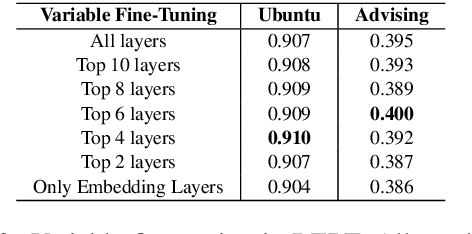
We focus on multi-turn response selection in a retrieval-based dialog system. In this paper, we utilize the powerful pre-trained language model Bi-directional Encoder Representations from Transformer (BERT) for a multi-turn dialog system and propose a highly effective post-training method on domain-specific corpus. Although BERT is easily adopted to various NLP tasks and outperforms previous baselines of each task, it still has limitations if a task corpus is too focused on a certain domain. Post-training on domain-specific corpus (e.g., Ubuntu Corpus) helps the model to train contextualized representations and words that do not appear in general corpus (e.g.,English Wikipedia). Experiment results show that our approach achieves new state-of-the-art on two response selection benchmark datasets (i.e.,Ubuntu Corpus V1, Advising Corpus) performance improvement by 5.9% and 6% on Recall@1.